なぜHappyHorse-1.0が突然ビデオリーダーボードで1位になったのか?
HappyHorse-1.0は公開チームなしでArtificial Analysisの1位を獲得した。Eloがブランドよりもビデオクオリティをどのように評価するか、そしてビルダーにとってそれが何を意味するのかを解説する。

やあ、みなさん。Doraです。今週、私のフィードで誰かが「HappyHorseって一体何なんだ?」というような質問をしているのを何回数えたか。6回。6つの別々のスレッドで。それぞれに少し異なる噂がくっついていました——WAN 2.7だ、ByteDanceのステルスリリースだ、Alibabaの何かだ、と。誰も確かなことは知らない。ただ全員が同意していること:2026年4月7〜8日頃にArtificial Analysisのビデオリーダーボードに登場し、即座にText-to-VideoとImage-to-Videoの1位を獲得したということです。
それが事実です。その後のこと——誰が作ったか、いつウェイトが公開されるか、1位を維持するか——はまだ未解決です。
この記事では、リーダーボードが実際に何を測定しているか、なぜ無名のモデルが正当にトップに立てるのか、そしてビルダーとしてその情報をどう使うべきか・使うべきでないかについて解説します。
Artificial Analysisビデオアリーナの仕組み
ランキングを信頼する前に、そのランキングが何を測定しているかを理解する必要があります。Artificial Analysisビデオアリーナは、モデル開発者が自分でスコアを提出するベンチマークではありません——ブラインドユーザー投票システムです。
ユーザーが見るもの(と見えないもの)
アリーナにアクセスすると、同じテキストプロンプトまたは入力画像から生成された2本の動画が表示され、どちらが好みかを選びます。どちらのモデルがどの動画を作ったかはわかりません。ラベルなし。コンテキストなし。ただ2つのクリップだけ。
これがArtificial Analysisが直接説明している内容です:「ユーザーは、どのモデルが各動画を作成したかを知らずに、同じテキストプロンプトから生成された2本の動画を比較します。」重要なのはここです。自己申告なし、開発者提供のベンチマークなし、マーケティングページによる影響なし。
Elo:信頼性のあるシグナル、ただし完璧ではない
ランキングはEloシステムを使用しています——競技チェスから借用したアプローチと同じです。2つのモデルが投票で対決するたびに、勝者はEloポイントを獲得し、敗者は失います。高いEloを持つモデルは、他のモデルとのマッチアップで一貫して勝ち越しています。
Eloスコアが高いほど、そのモデルがより頻繁に好まれることを示します。これは本物のシグナルです。合成テストではなく、チェリーピックされた例でも、モデルカードでもなく、何千もの実際の人間の選択に基づいています。
投票数とサンプルサイズ:見落とされがちな部分
新規参入者とEloに関して重要なことがあります。Seedance 2.0などの確立されたモデルは、スコアの背後に何千もの投票があります——Seedance 2.0はT2Vカテゴリで7,500以上の投票サンプルを持っています。HappyHorseのサンプル数はまだ公開されていません。投票数が多いほど、スコアが安定します。マッチアップ数が少ない新しいモデルは、新しい投票ごとにより大きく変動する可能性があります。

より多くの投票が集まるにつれ、これらの数値は変化します。その変化の方向性は不明です。わずか2日前の数値に基づいてパイプラインの決定を行う前に、そのことを念頭に置いてください。
HappyHorse-1.0が実際にスコアしていること
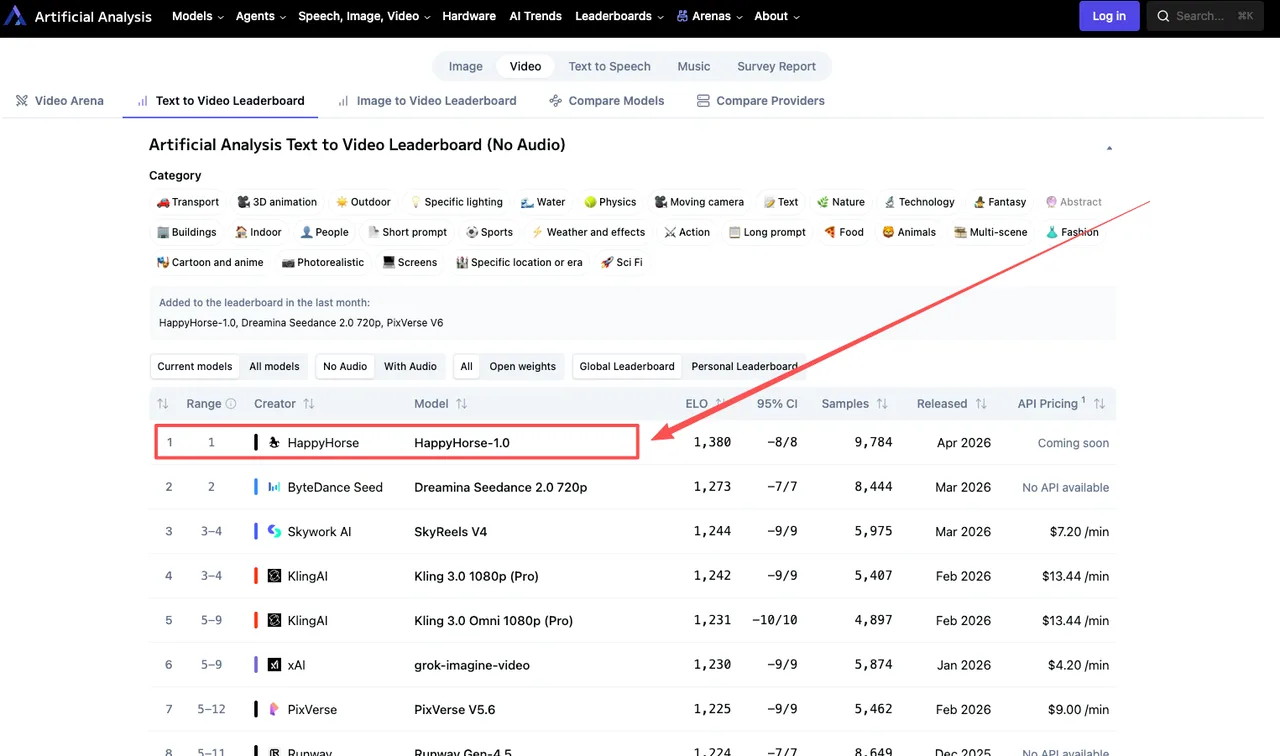
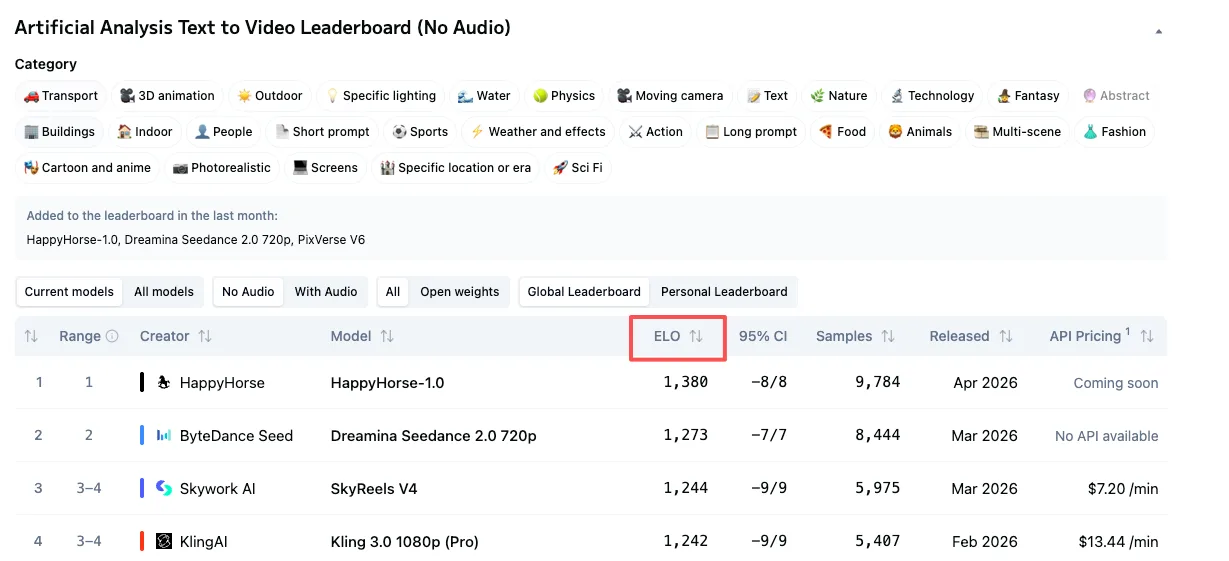
2026年4月初旬時点でのライブリーダーボードから取得した現在の数値:
T2V(音声なし): HappyHorse-1.0がEloスコア1357でトップ、Dreamina Seedance 2.0の1273、SkyReels V4の1244、Kling 3.0 Proの1243を上回っています。
I2V(音声なし): HappyHorse-1.0がElo 1402でトップ、Seedance 2.0が1355、Grok Imagine Videoが1331。
音声なしI2Vでの84ポイント差は小さくありません。60ポイントのElo差は、一方のモデルがブラインドマッチアップの約58〜59%で勝つことを意味します——意味のある差です。80ポイント以上の差はさらに強力です。
音声の話は逆転する
音声ありのImage-to-VideoでHappyHorse-1.0は現在Eloスコア1160でトップ、Dreamina Seedance 2.0が1158。2ポイント差は統計的ノイズです。そして音声ありT2VではSeedance 2.0が1220でHappyHorseが1215。
つまり、「HappyHorseはどこでも#1」というよりも、状況はより微妙です。音声を除外した場合は大差で1位。音声品質が方程式に入ってくると、Seedance 2.0と事実上タイです。
アーキテクチャの主張が言うこと(と証明しないこと)
HappyHorseについて説明しているいくつかのサイトによると、約150億パラメータのシングルストリームTransformerアーキテクチャで動作し、単一のH100で1080pクリップを約38秒で生成すると主張しています。2026年4月8日時点で、これらのHappyHorseサイトのGitHubとHugging Faceのリンクは「coming soon」ページを指しているか、404エラーを返します。ウェイトは公開ダウンロード可能ではありません。
これらのアーキテクチャの主張は妥当ですが、未検証です。パラメータ数、アーキテクチャの種類、推論速度を確認した独立した技術監査はありません。確認済みではなく、主張済みとして扱ってください。
未知のモデルがEloで勝てる理由
リーダーボードがブランド認知度を報酬にすると思っている人々が混乱する部分はここです。
Eloは誰がモデルを作ったかを気にしません。 あなたがGoogleか3人のラボかを知りません。Artificial AnalysisのVideo Arenaは、Eloレーティングシステムを使用し、完全に実際のユーザーによるブラインド投票に依存しています。パラメータ、論文、ハイプを無視し、ただ一つの質問だけを気にします:「両方を見た後、どちらの動画が好みでしたか?」
これは実際には特徴です。資金豊富なブランドが有利な論文を発表することで良い結果を「買う」ことができない、数少ない評価システムの一つです。
このパターンは以前にも起きた
匿名プレローンチドロップは中国AIエコシステムでパターンになっています。2026年2月のPony Alpha案件が最も明確な先例です——謎のモデルがOpenRouterに登場し、推測ゲームを引き起こし、Z.aiのGLM-5がステルスストレステストをしていたことが判明しました。HappyHorseはこのテンプレートに当てはまります:不明な名前、ローンチ時にチーム帰属なし、「coming soon」のGitHubリンクがあるランディングページ、強力な出力。
それが静かな能力チェックを行う大手ラボなのか、本当に新しいチームなのか——まだ未解決です。しかしEloスコア自体はいずれにせよ本物です。
Eloが隠せない限界
Eloは一つのことを測定します:実際のユーザーがブラインド比較でどちらの動画を好んだか。バッチランでのモデルのパフォーマンスは測定しません。API稼働時間、負荷下のレイテンシ、アリーナの例をチェリーピックするのではなくスケールで生成する場合の出力品質の一貫性も測定しません。
モデルはブラインドテストで優れた結果を持ちながら、本番環境では完全に使えないことがあります。これらは別々の質問です。
「リーダーボード1位」がビルダーにとって意味しないこと
HappyHorseの現在のランキングに基づいてツールの決定をしようとしているなら、ここで少し立ち止まることをお勧めします。
APIなし、本番アクセスなし
HappyHorseを「リーダーボードエントリー」から「実際のオプション」に変える3つのものがあります:実際のウェイトと推論コードを持つGitHubリポジトリ、検証可能な詳細とライセンスを持つHuggingFaceモデルカード、またはドキュメント化された価格設定のあるAPIエンドポイント。これらはいずれも執筆時点では存在しません。
呼び出せないなら、使えません。リーダーボードの位置は出力品質に関する情報であり、可用性に関するものではありません。
音声パフォーマンスが計算を変える
ワークフローが音声を必要とする場合——ボイスオーバー、環境音、リップシンク——HappyHorseのリードは実質的に消えます。音声ありカテゴリでのSeedance 2.0との差はT2Vで5ポイント、I2Vで2ポイントです。これらは通常のEloバリアンス内のタイです。
音声が必要なユースケースでは、現時点での実際のフィールドはトップでのSeedance/HappyHorseのタイのように見え、SkyReels V4が一段下にいます。
チームの説明責任:不明
Artificial Analysisはアリーナにモデルを追加した際にHappyHorseを「匿名」と説明しました。モデルに関連するサイトの一つは、Taotian Group(Alibaba)のFuture Life Labチームによって構築されたと主張し、Kling AIの元ヘッドであるZhang Diが率いているとしています。別の分析では、ほぼ同一の仕様を共有するSand.aiのオープンソースプロジェクトdaVinci-MagiHumanに関連付けました。どちらも公式に確認されていません。
本番ツールとして、チームの説明責任はバグ修正、モデルのアップデート、長期的なサポートにとって重要です。匿名モデルでは、その明確さがありません。
ビルダーとしてビデオリーダーボードを読む方法
抽象論ではなく、具体的なフレームワークです。
Eloを品質シグナルとして使い、調達決定としては使わない。 モデルが資金豊富な競合他社とのブラインド比較で一貫して勝っているなら、それは生産するものについて本物のことを教えてくれます。注目する価値があります。API条件、価格設定、レイテンシ、またはチームがバグレポートに対応するかどうかについては何も教えてくれません。
実際のリーダーボードは3位から始まる。 EloによるトップクオリティのモデルであるHappyHorseとSeedance 2.0はどちらも公開APIでアクセスできません。次のティア——SkyReels V4、Kling 3.0、PixVerse V6——が現在実際の統合決定が行われる場所です。
新しいリーダーボード参入者に早期対応する時期。 モデルが意味のあるEloギャップでトップにあり、検証済みのGitHubリリースがあり、ドキュメントが存在する場合——すぐにテストする価値があります。トップにいるがGitHubが「coming soon」と言っている場合——2週間後に確認するリマインダーを設定してください。蒸気の周りにパイプラインを再構築しないでください。
ライブリーダーボードを直接確認し、記事ではなく。 この記事も含めて。Eloスコアは毎日変動します。ここで参照した数値は2026年4月初旬を反映しており、あなたがこれを読む頃には変化しているでしょう。
FAQ
HappyHorse-1.0はArtificial Analysisリーダーボードにどのくらいの期間掲載されていますか?
Artificial Analysisは2026年4月7日にそれを発表し、新たに追加された匿名モデルとして説明しました。執筆時点で、約48時間ライブであり、投票数はまだ積み重なっています。
モデルはEloで1位を無期限に維持できますか?
通常はできません。新しいモデルがアリーナに参加してより多くの票を集めるにつれ、ランキングは変わります。小サンプルで2日目に支配するモデルは、投票プールが深まるにつれてより低く安定する可能性があります。スコアは常にライブです——現在のデータを反映しており、永久的な判断ではありません。
Artificial Analysisはアリーナへのモデル提出者を検証しますか?
Artificial Analysisはモデル提出の公式検証ポリシーを公開していません。アリーナに追加する際にHappyHorse-1.0を「匿名」と説明しており、これはチームの身元が彼らには知られているが公開されていないことを示唆しています。提出モデルの技術的監査を行うかどうかは文書化されていません。
Eloスコアだけでモデルを選ぶべきですか?
いいえ。Eloはブラインド比較での視覚的好みについて教えてくれます。API可用性、生成あたりのコスト、レイテンシ、稼働時間、コンテンツポリシー、またはモデルが3ヶ月後に存在するかどうかについては何も言いません。いくつかのシグナルの一つです。
リーダーボードランキングと並んで重要な他の指標は何ですか?
APIアクセスとドキュメント;生成あたりまたは分あたりの価格設定;使用頻度でのレイテンシとコールドスタートの動作;Eloスコアの背後にあるサンプル数(投票数が多いほど安定);チームがモデルを維持・更新してきた実績。WaveSpeedモデル比較ページでは、出発点としてアクセス可能なモデルにわたるこれらのいくつかの次元を追跡しています。
現状はこうです。未知のチームと公開ウェイトのないモデルが、私たちが持つ最も信頼できるビデオベンチマークのトップに立ちました。無視しがたいマージンで。それが本当の本番オプションになるかどうかは、今後数週間で何がリリースされるかにまったくかかっています。
注目する価値あり。まだ行動する価値なし。
続報をお楽しみに。
WaveSpeedAIでHappyHorse-1.0を試す
HappyHorse-1.0はWaveSpeedAIで利用可能になりました:
関連記事:





