SkyReels V4とは?初の統合ビデオ・オーディオAIモデルを解説
SkyReels V4は、映像と音声を同時に生成できる初のオープンソースAI — 1080p/32FPS対応。その機能、仕組み、そして重要性を詳しく解説します。

こんにちは、Doraです。あの日、初めて SkyReels V4 の動画を生成しました。夕暮れ時の雨に濡れた路地を歩く猫の、15秒の映像です。動画は見栄えが良く——1080p、滑らかな動き、美しいライティング。でも私が足を止めたのは音声でした。水たまりに足音が響く音。遠くの車の音。路地の壁にかすかに反響するエコー。それらすべてが同時に生成され、完璧に同期されていました。私は音声編集ツールに一切触れていないのに。
それが、これまでと違うと感じた部分でした。
V4以前のすべてのビデオAIツールが抱えていた問題
映像のみの生成がいつも不完全に感じられた理由
ほとんどのビデオAIツールは無音のクリップを生成します。Runway、Pika、初期のSkyReelsバージョンでさえ——映像を生成してそこで終わります。ビーチに打ち寄せる波の美しい10秒のショットが生成されますが、完全に無音です。波は砕けない。風は吹かない。環境音がまったくありません。
これは技術的な見落としではありません。映像と同期した音声を生成することは、本質的に困難です。音声は単に全体的なシーンに合わせるだけでなく、特定の視覚的イベントと一致させる必要があります——足が地面に触れたときに足音が鳴り、ドアが閉じるときに閉まる音がし、声が口の動きに同期する、といったように。
「ポスト作業で音声を追加する」というボトルネック
標準的なワークフローとなったのは、動画を生成し、エクスポートし、音声エディターを開き、効果音や音楽を手動で追加し、手作業ですべてを同期させ、再度エクスポートするというものでした。15秒のクリップでも、20〜30分かかることがありました。
先月、Pikaの出力でこれを試してみました。動画はプロフェッショナルな仕上がりでした。しかし、適切な環境音を見つけ、視覚的な手がかりに合わせてタイミングを合わせ、「明らかに後から追加した」という感じを避けることに、動画を生成するより多くの時間がかかりました。ワークフローが壊れているように感じました——車を買ってもエンジンは別途取り付けなければならないようなものです。
SkyReels V4とは何か
SkyworkAIが開発(V1/V2/V3の系譜を解説)
SkyworkAIは2025年初頭に基本的なテキスト・トゥ・ビデオモデルとしてSkyReels V1をリリースしました。V2では自己回帰シーケンスによる無限長生成を可能にするdiffusion forcing アーキテクチャを導入。V3は2026年1月にローンチし、マルチモーダルなin-context learningを搭載——参照画像、音声クリップ、または既存の動画を与えることで、一貫した続きを生成できるようになりました。

2026年2月25日に公開されたV4は、別次元の飛躍を表しています。V3が機能を追加したのに対し、V4は映像と音声を同時に生成するデュアルストリームシステムを中心にアーキテクチャ全体を再構築しました。
「統合型映像・音声基盤モデル」が実際に意味すること
技術論文では、V4が2つの並列ブランチを持つMultimodal Diffusion Transformer(MMDiT)を使用していると説明されています。一方のブランチが映像フレームを合成し、もう一方が時間的に整合した音声を生成します。両ブランチはマルチモーダル大規模言語モデルに基づくテキストエンコーダーを共有しており、プロンプトの同じ意味理解を処理し、生成全体を通じて同期を維持します。
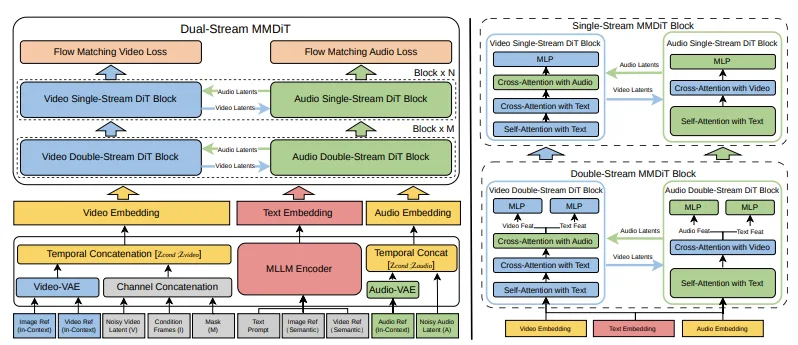
これは映像生成に音声を後付けしたものではありません。視覚と音声を同等に重要な出力として扱い、シーンの同じ潜在的理解から一緒に生成する単一のモデルです。
実際には、「演壇でスピーチする女性」とプロンプトを入力すると、モデルは彼女の唇が動く映像と実際のスピーチ音声の両方を、フレームレベルで同期して生成します。「金属屋根に打ち付ける激しい雨」を生成すると、雨が流れ落ちる映像と特徴的な金属を叩くドラミングサウンドの両方が得られます——おおよそ一致しているのではなく、統合された映像音響イベントとして生成されます。
主な機能の概要
1つのプロンプトからの映像+音声の同時生成
単一プロンプト生成が核心的な機能です。「砂漠の景観を横切る雷鳴」と書くと、V4は雲が集まり、稲妻が光り、視覚的なタイミングと一致した同期された雷が轟く15秒の映像を生成します。音声生成の別ステップはありません。手動での同期作業もありません。
セリフシーンでこれをテストしました。「賑やかなカフェで口論する二人」とプロンプトを入力すると、会話の映像だけでなく、バックグラウンドのざわめき、食器の触れ合う音、話者の声がジェスチャーの強度に合わせて上下するのも得られました。リップシンクは完璧ではありませんでした——タイミングがわずかにズレる瞬間がいくつかありましたが——それでも手動で同期させたどんなものよりも優れていました。
1080p / 32FPS / 15秒出力
技術仕様:最大1080p解像度、毎秒32フレーム、最大15秒の尺。参考として、競合ツールのほとんどは720pが上限か、HD出力には大幅に長い生成時間を要します。
15秒の制限は聞こえるよりも重要です。ほとんどのソーシャルメディアコンテンツは10〜15秒のチャンクで存在します。YouTubeショーツは60秒まで。Instagramリールは90秒まで。そのユースケースでは、ポスト制作が必要な30秒の無音動画よりも、同期した音声付きの15秒の方がより実用的です。
マルチモーダル入力:テキスト、画像、動画、マスク、音声リファレンス
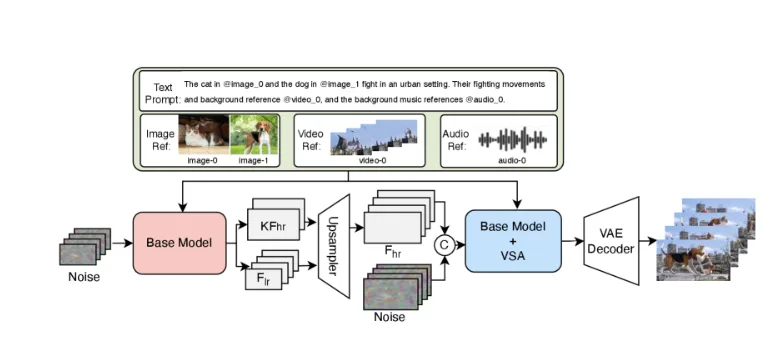
V4は5つの入力タイプを受け付けます:テキストプロンプト、参照画像、動画クリップ、インペインティング用のバイナリマスク、音声リファレンス。これらを組み合わせることができます——特定の人物の画像をアップロードし、砂利の上を歩く足音の音声サンプルを提供し、「夜明けの森を歩く」とプロンプトを入力する、といったように。モデルはこれら3つの入力すべてを使って生成をガイドします。
特定の建築スタイルの参照画像と街の環境音の音声クリップを使ってマルチモーダルプロンプティングをテストしました。生成された動画は画像からの建築的な詳細を維持しながら、音声リファレンスの環境音をレイヤーとして加えました。完璧ではありませんでした——いくつかの音声要素は汎用的に感じられましたが——機能自体は動作しました。
3つのタスクを1つで:生成、インペインティング、編集
生成を超えて、V4はチャネル結合によるインペインティングと編集を処理します。動画と修正する領域を示すマスクを提供すると、モデルはその領域のみを再生成しながら残りを保持します。これにより、クリップ全体を再生成することなく、オブジェクトの削除、背景の変更、特定の要素の置き換えなどのタスクが可能になります。
V4は以前のものと比べてどうか
V4 vs SkyReels V1/V2/V3の進化
V1はテキスト・トゥ・ビデオのみでした。V2はdiffusion forcingによって長さを追加しました。V3はマルチモーダル入力を導入しましたが、ネイティブ音声なしで動画を生成していました。V4は、映像と同時に生成されるファーストクラスの出力として音声を扱う初めてのバージョンです。
SkyReels V4に注目すべき人は?

コンテンツクリエイターと映像制作者
ソーシャルプラットフォーム向けの短尺コンテンツを制作する人なら誰でも、すぐにメリットを受けられます。ワークフローの圧縮——プロンプトから完成した映像音響クリップへ——は、AIビデオツールが節約するよりも多くの作業を生み出すと感じさせていたボトルネックを取り除きます。
映像制作者の友人がV4を使ってドキュメンタリーのBロールを生成するのを見ました。「夕暮れ時に街のライトが点灯するタイムラプス」や「ガラスに当たる雨のクローズアップ」といったプロンプトに適切な環境音を加えて。出力は本物の映像と見分けがつかないものではありませんでしたが、背景ショットとしては十分な品質で、ロケ撮影やストック映像のライセンス取得を必要とせず、それぞれ60秒以内に用意できました。
映像パイプラインを構築する開発者
映像を生成または操作するアプリケーションを構築している場合、V4の生成、インペインティング、編集のための統合インターフェースはスタックを簡素化します。動画生成、音声合成、同期補正のための個別モデルをチェーンする代わりに、1回のAPI呼び出しでフロー全体を処理します。
モデルアーキテクチャは詳細に文書化されており、SkyworkAIには以前のバージョンをオープンソース化してきた実績があります。これは開発者アクセスが拡大することを示唆しています。V3のウェイトはすでにHugging FaceとGitHubで入手可能です。
現在のアクセス状況と今後の展開
2026年3月2日時点で、V4は限定プレビュー中です。公式サイトでは1日の生成制限付きの無料ティアを提供していますが、APIアクセスはまだありません。論文リリースから公開APIまで約2週間かかったV3のタイムラインに基づくと、3月中旬までにより広い利用が可能になると予想されます。
技術論文では、今後の課題として15秒を超える拡張とより細かい音声制御の改善が挙げられています。これらの制限は今のところ重要に感じます。特に尺の上限は。しかしV4が解決する特定の問題——ポスト制作なしで短く同期された映像音響クリップを生成すること——については、私がテストした他のどのツールよりもうまく機能します。
最初のテストからV4をワークフローに取り入れています。すべてに使うわけではありません——撮影済み映像やストック動画の方が適しているタスクはまだあります。しかし、同期した音声が重要なクイックBロール、環境シーン、ソーシャルメディアの短編コンテンツについては、V4は十分な摩擦を取り除いてくれたので、今では最初に手を伸ばすツールになっています。
この統合アーキテクチャは、段階的な機能追加というより、最初からこうあるべきだった何かを修正したように感じられます。





