HappyHorse-1.0 vs Seedance 2.0: 今はどちらが優れているか?
HappyHorse-1.0はT2VとI2V(音声なし)でSeedance 2.0をリードしていますが、音声面では劣り、安定したAPIもありません。ビルダーにとっての意味を解説します。

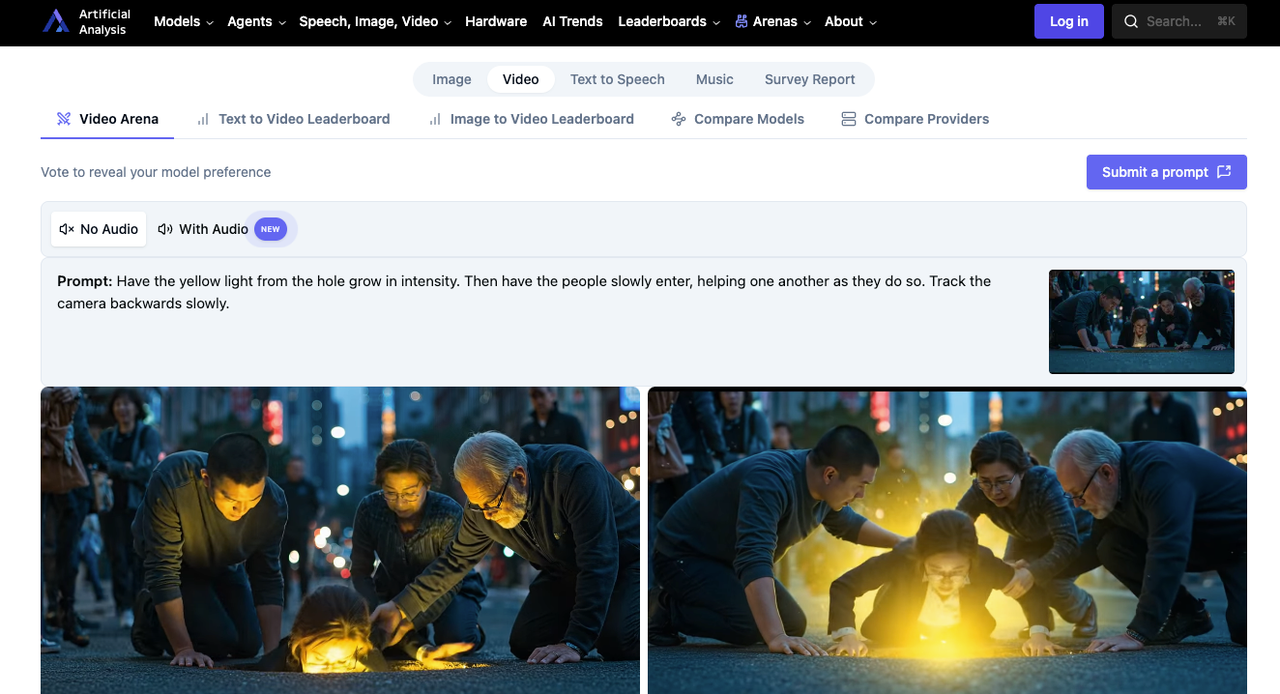
Artificial Analysis Video Arena リーダーボードを何度もリフレッシュしながら、多くの時間を費やしていた。こんにちは、Doraです!週末の間にひっそりと現れたHappyHorse-1.0というモデル — 聞いたことのない名前だったが — がSeedance 2.0を4つの主要ランキングのうち2つでトップから押しのけていた。誰が作ったのか誰も知らないようだった。Artificial Analysis自体もこれを「匿名」エントリーと呼んでいた。私のタイムラインは半分が興奮、半分が混乱で埋まっていた。
そこで数値を引き出し、アクセス経路を追跡し、今これらのモデルで開発している人にとって本当に重要な唯一の問いに答えようとした:今日出荷できるのはどちらか?
答えはリーダーボードが見せるほどすっきりしていない。
リーダーボードで重要な4つの数値
HappyHorseとSeedance 2.0はArtificial Analysisの4つの独立したランキングでトップに位置している。しかし、音声が評価に含まれるかどうかによってその順位は入れ替わる。この違いはほとんどの比較が認めるよりもはるかに重要だ。
音声なしT2V: HappyHorse 1位 (Elo 1333) vs Seedance 2.0 2位 (Elo 1273)
これはHappyHorseが最も強さを発揮するカテゴリーだ。ブラインド投票アリーナでの60ポイントのEloの差は意味がある — ヘッドトゥヘッドのマッチアップでユーザーが約59%の確率でHappyHorseの出力を好むことにほぼ相当する。ここでの投票は、知覚に影響する音声なしで、視覚的なモーションクオリティ、プロンプト忠実度、シーンの一貫性を評価している。
音声ありT2V: Seedance 2.0 1位 (Elo 1219) vs HappyHorse 2位 (Elo 1205)
音声が加わると、Seedanceが14ポイントでリードを取る。ByteDanceのDual-Branch Diffusion Transformerは、1回のパスで動画と音声を同時に生成する — 1つのブランチが動画フレーム用、もう1つが音声波形用で、クロスアテンションで接続されている。同期した効果音とダイアログが判断の一部となるとき、このアーキテクチャの選択が実を結ぶ。
音声なしI2V: HappyHorse 1位 (Elo 1392) vs Seedance 2.0 2位 (Elo 1355)
4つのカテゴリー全体でHappyHorseの最高Elo。音声なしの画像から動画への変換で37ポイントのリードは、このモデルが参照画像の構成に従うことに特に優れていることを示している — モーションを生成する際に被写体のアイデンティティ、フレーミング、視覚スタイルを一貫して維持している。製品アニメーションやコンセプトからモーションへの作業をしているチームには、これが重要な数値だ。
音声ありI2V: Seedance 2.0 1位 (Elo 1162) vs HappyHorse 2位 (Elo 1161) — ほぼ同点
1ポイント。 これはいかなる合理的な誤差範囲内にも収まる。このカテゴリーではどちらのモデルも実質的な優位性はない。大幅に多くの票が蓄積されるまで、このカテゴリーは引き分けとして扱ってほしい。
Eloが実際に測定するものとプロダクション決定における限界
これらのEloスコアは、ブラインドユーザー投票による並列比較から来ており、チェスのランキングから採用したBradley-Terryモデルを使用している。ユーザーは同じプロンプトから匿名で生成された2つの動画を見て、好ましい方を選ぶ。これはスケールでの「バイブチェック」に最も近いものだ。
しかしEloはAPIの信頼性、生成速度、クリップあたりのコスト、アクセスの安定性、またはモデルをプログラム的に呼び出せるかどうかを測定しない。リーダーボードのランクはクオリティシグナルであり、出荷の決定ではない。
コア比較テーブル
| 次元 | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| T2V Elo (音声なし) | 1333 (1位) | 1273 (2位) |
| T2V Elo (音声あり) | 1205 (2位) | 1219 (1位) |
| I2V Elo (音声なし) | 1392 (1位) | 1355 (2位) |
| I2V Elo (音声あり) | 1161 (2位) | 1162 (1位) |
| 音声生成 | あり、Seedanceに劣る | より強力 — ネイティブデュアルブランチ同期 |
| 既知のプロバイダー | なし — 匿名 | あり — ByteDance |
| アーキテクチャ (主張) | シングルストリーム40層Transformer | Dual-Branch Diffusion Transformer |
| オープンウェイト | 「近日公開」と主張 | なし |
| 安定したAPI | 公開APIなし | Dreaminaを介した消費者アクセス; 公式APIは一時停止 |
| 今日のアクセス | デモサイトのみ | Dreamina、CapCut Pro、中国製アプリ |
HappyHorseが優位な点
音声なしの視覚モーションクオリティ: ブラインド投票が捉えているもの
音声なしランキングでのEloの差 — T2Vで60ポイント、I2Vで37ポイント — は些細なものではない。ブラインド比較でのユーザーは、より自然なカメラの流れ、滑らかな体の動き、より強いシーンの雰囲気と表現されるものでHappyHorseを継続的に選んでいる。ユースケースがサイレントな製品ループ、別の音楽で編集されたソーシャルクリップ、またはポストでスコアリングされるBロールなら、これは関連性がある。
シングルストリームTransformerアーキテクチャ (主張) vs マルチストリームパイプライン
HappyHorseのマーケティング資料は、テキスト、動画、音声トークンを1つのシーケンスで処理する統一された40層セルフアテンションTransformer — 別のブランチ間のクロスアテンションなし — を説明している。正確であれば、これはSeedanceのデュアルブランチアプローチとアーキテクチャ的に異なる。最初と最後の4層はモダリティ固有のプロジェクションを使用し、中間の32層はすべてのモダリティでパラメータを共有すると報告されている。これらの主張をまだ独立して検証できない。GitHubとモデルハブは「近日公開」としてリストされている。
多言語音声の主張
HappyHorseは英語、北京語、広東語、日本語、韓国語、ドイツ語、フランス語の7言語のネイティブサポートを主張しており、低い単語誤り率のリップシンクがある。Seedance 2.0はフォネームレベルのリップシンクで8言語以上をサポートしている。書面上では競合している。実際には、HappyHorseの多言語出力を十分にストレステストして同等性を確認するには至っていない。
Seedance 2.0が優位を維持している点
音声生成: 両方の音声ありリーダーボードで依然としてリード
Seedanceは音声ありのT2VとI2Vの両方で1位を維持している。そのデュアルブランチアーキテクチャ — 1つのブランチが動画フレームを生成し、もう1つが音声波形を生成し、ミリ秒レベルの同期のためにクロスアテンションで接続 — はこのために構築された。出力にダイアログ、アンビエントサウンド、またはフレーム精度のフォーリーが必要な場合、生成中に音声を一等市民として扱うというSeedanceのアーキテクチャ的決定 (後処理ステップではなく) が構造的な優位性を与える。
既知のプロバイダー: ByteDance、安定したアイデンティティ、確立されたエコシステム
Seedance 2.0を誰が作ったかは分かっている。Wu Yonghui (元Googleフェロー、Google Brainを含むGoogleで17年) 率いるByteDanceのSeedリサーチチームは、PixeldanceからSeedance 1.0、1.5 Pro、そして2.0への文書化された系譜を持っている。HappyHorseは?公開時点で、誰が作ったかを公式に確認した人はいない。Artificial Analysisはそれを匿名エントリーとして追加した。アリーナデビューから数時間以内に複数のサードパーティラッパーサイトが現れたが、元の開発者であると主張するものはない。
プロダクション決定において、来歴は重要だ。モデルの更新、コンプライアンス、継続性のために誰に依存しているかを知る必要がある。
アクセス経路: Dreaminaには公開エントリーポイントがある
Seedance 2.0は今日、ByteDanceのDreaminaプラットフォームを通じて国際的にアクセス可能で、月約18ドルから有料プランが始まる。CapCut Proの統合は2026年3月下旬に一部市場でロールアウトされた。中国ユーザーは月約69人民元 (約9.60米ドル) のプランでJimengを通じてアクセスできる。
とはいえ — 公式Seedance 2.0 APIは、著作権紛争の報告により2026年3月中旬以来停止されたままだ。 消費者アクセスは機能している。プロダクションスケールでのプログラム的APIアクセスは、パイプラインを構築する前に確認が必要だ。サードパーティプロバイダーはAPIでSeedance v1.5を提供している;公式チャンネルを通じたSeedance 2.0 APIの利用可能性はプレプロダクション確認が必要だ。
アクセスギャップが真の決定要因
HappyHorse: 安定したAPI なし、公開ウェイトなし、公開時点ではデモのみ
オープンソースリリースの主張にもかかわらず、HappyHorseのGitHubとモデルハブは両方とも「近日公開」としてリストされている。複数のデモとラッパーサイトが存在するが、製品を構築できるようなSLA、レート制限、または価格設定を持つ文書化されたAPIエンドポイントを提供するものはない。安定した文書化されたエンドポイントを通じてHappyHorse-1.0を提供しているサードパーティAPIプロバイダーを一つも見つけられなかった。
プロダクションのために評価しているなら、これが最大の単一要因だ。確実に呼び出せないモデルは出荷できるモデルではない。
Seedance 2.0: Dreaminaを介してアクセス可能 — 詳細は確認が必要
Dreaminaを通じた消費者アクセスは機能している。プラットフォームは@参照システム、マルチショット編集、視聴覚生成を含む完全な機能セットをサポートしている。しかし、ワークフローにAPIレベルの統合が必要な場合、状況はあまり確定的ではない。Seedance 2.0の公式BytePlus APIは3月から停止している。fal.aiやPiAPIなどのサードパーティプロバイダーはSeedance 1.5を提供してきた;Seedance 2.0のプログラム的アクセスと関連する価格体系は、プロダクションの依存関係を構築する前に直接確認する必要がある。
「リーダーボード1位」と「プロダクション対応」が異なる理由
これを何度も考える。EloはコントロールされたL比較でユーザーがどのモデルを好むかを教えてくれる。来週の火曜日に503エラーなしで1万件の生成を処理できるかどうかは教えてくれない。HappyHorseは確かにより良いサイレントビデオを生成するかもしれない。しかし確実に呼び出せなければ、そのクオリティの優位性はアリーナの中にあるのであって、パイプラインの中にはない。
意思決定フレームワーク
音声クオリティが必須 → Seedance 2.0。 両方の音声ありリーダーボードでリードしており、デュアルブランチアーキテクチャがネイティブで同期サウンドを生成する。クリップにダイアログ、アンビエント音声、またはフレーム精度の効果音が必要なら、Seedanceが今日のより強い選択だ。
視覚モーションの忠実度が優先事項で待つ意思がある → HappyHorseを監視。 音声なしのEloリードは本物だ。オープンウェイトとAPIアクセスが約束通り実現すれば、HappyHorseはサイレントファーストワークフローに魅力的になる可能性がある。しかし「近日公開」はSLAではない。
今日プロダクションAPIが必要 → Seedance 2.0の方が安全な賭けだ。 完璧だからではなく — 公式APIの一時停止は現実の制約だ — DreaminaがDocumented価格設定付きの機能的なアクセス経路を提供し、サードパーティプロバイダーがSeedance 2.0エンドポイントを積極的に準備しているためだ。HappyHorseには同等のインフラがまだない。
FAQ
HappyHorse-1.0は実際にSeedance 2.0より優れているか?
何を測定しているかによる。HappyHorseは音声なし比較での視覚クオリティでリードしている (T2VでElo 1333 vs 1273、I2VでElo 1392 vs 1355)。Seedanceは音声が評価の一部であるときにリードする。4つのカテゴリーすべてでどちらも優位ではない。「優れている」はあなたの具体的なユースケースと音声が重要かどうかに対してのみ意味をなす。
なぜHappyHorseは音声なしでリードするが音声ありでは劣るのか?
おそらくアーキテクチャの問題だ。HappyHorseは1つのシーケンスですべてのモダリティを処理する統一されたTransformerを主張している。Seedance 2.0はクロスアテンションで接続された別の動画と音声ブランチを持つ専用デュアルブランチデザインを使用している。その専門的な音声ブランチが、視覚と並んでサウンドクオリティと同期が判断されるときにSeedanceに優位を与えているようだ。
今日HappyHorse-1.0にAPIでアクセスできるか?
2026年4月8日時点で確認できた安定した文書化されたエンドポイントを通じてはアクセスできない。複数のラッパーサイトがブラウザベースのデモアクセスを提供しているが、APIドキュメント、レート制限、またはプロダクショングレードのSLAを公開しているものはない。公式GitHubとモデルハブは両方とも「近日公開」としてリストされている。
Artificial Analysisリーダーボードはプロダクション決定にどれほど信頼できるか?
知覚される動画クオリティに対する最も信頼できるクラウドソースシグナルだ — ブラインド投票、Eloベースのランキング、実際の人間の好み。しかし1つのことを測定する:ユーザーが並べて見たときどの出力を好むか。生成速度、コスト、信頼性、API稼働時間、またはアクセスの安定性は考慮していない。クオリティのインプットとして使用し、完全な調達決定としてではなく。
HappyHorse-1.0は将来のバージョンで音声の改善はあるか?
公開ロードマップは存在しない。モデルは1週間も経たないうちに匿名でアリーナに現れた。「近日公開」のオープンソースリリースが実現すれば、コミュニティの貢献が音声クオリティを改善できるかもしれない。しかしタイムラインはなく、確認された開発チームもなく、発表されたv2計画もない。現在リーダーボードにあるもの以上のことはすべて推測だ。
リーダーボードが言うことと開発者が実際に使えるものの間のギャップに興味深いことが起きている。HappyHorseの数値は本当に印象的だ — しかしアクセスのない数値はただの数値だ。そのGitHubリポジトリが公開されるのを見続けるつもりだ。それまで、この比較はどちらのモデルが優れているかについてではない。どちらのモデルが利用可能かについてだ。
WaveSpeedAIでHappyHorse-1.0を試す
HappyHorse-1.0がWaveSpeedAIで利用可能になった:
関連記事:




