Claude MythosのコーディングパフォーマンスがAI開発ワークフローにもたらす意味
Claude MythosはOpus 4.6よりもコーディングスコアが大幅に高いと報告されています。2026年にAIコーディングエージェントを構築する開発者にとって何を意味するかを解説します。

Fortuneが「Anthropicが未公開モデルを宣伝する下書きブログ記事を含む約3,000件の内部ファイルを誤って公開した」という太字の見出しを掲げたとき、誰もがサイバーセキュリティの脅威に注目した。しかし、毎日Claudeを使って開発している私にとって、注目を引いたのはリーク自体ではなく——その下書きに静かに埋もれていたコーディング性能に関する爆発的な主張だった。
WaveSpeedAI で利用可能 — トークン単位の透明な料金、OpenAI 互換エンドポイント。 Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Playground を開く →
この記事では、私Doraと皆さんが一緒に、誇大広告やセキュリティパニックを追いかけるのではなく、Claude Mythos / Capybaraのコーディング能力について私たちが実際に知っていること(そして知らないこと)を正確に整理し、開発者や実際のプロダクトを出荷しているチームにとって本当に重要なことに切り込んでいく。
リークされた下書きがClaude MythosのコーディングパフォーマンスについてSayしていること
リークされた下書きの正確な主張:「以前の最良モデルであるClaude Opus 4.6と比較して、Capybaraはソフトウェアコーディング、学術的推論、サイバーセキュリティなどのテストで劇的に高いスコアを獲得している。」
コーディング性能についてAnthropicが文書に記したのはこれが全てだ。SWE-benchのパーセンテージも、Terminal-Benchのスコアも、比較表もない。「劇的に高い」というフレーズが実際のシグナルだ——曖昧ではあるが、無意味ではない。

参考までに、Opus 4.6は現在、SWE-bench Verified(約80.8%)、Terminal-Bench 2.0、Humanity’s Last Examで公開モデルのトップに立っている。Anthropicの公式スポークスパーソンはこのモデルが「推論、コーディング、サイバーセキュリティにおける意味のある進歩」を表すと確認した。トレーニングは完了し、早期アクセステストが進行中であり、コーディングは3つの主要な能力次元の1つとして明示されている。それ以外はすべて推測だ。
このモデル層においてコーディングが最も重要な能力である理由
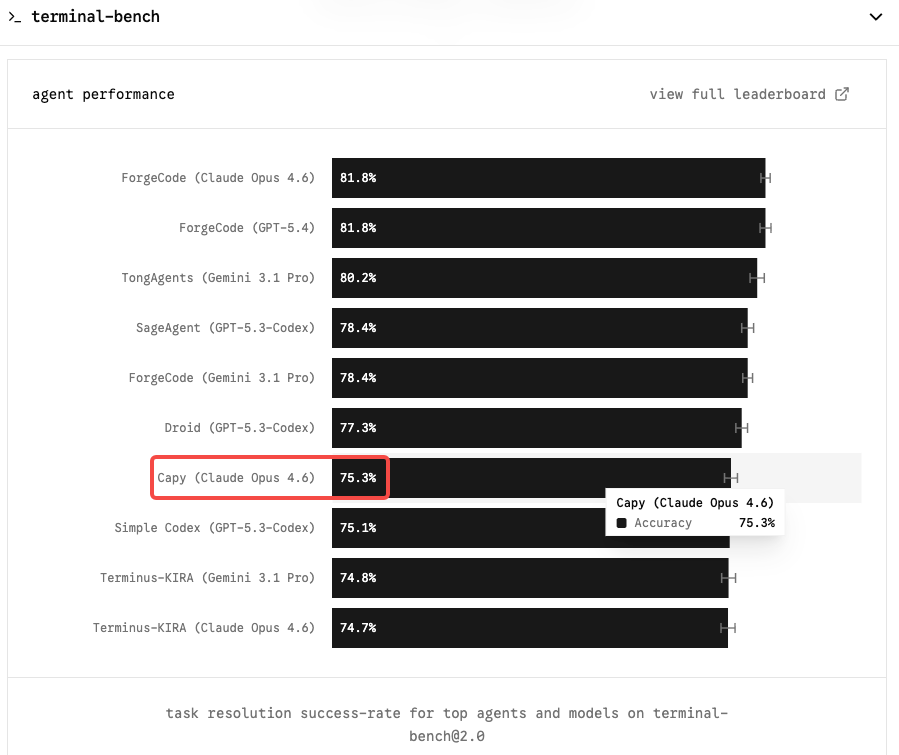
Terminal-Bench 2.0のコンテキストと現在のOpus 4.6のスコア
Terminal-Bench 2.0は、エージェント型コーディングワークフローにとって最も重要なベンチマークだ。孤立したGitHubイシューの解決をテストするSWE-benchとは異なり、Terminal-Benchはサンドボックス化されたターミナル環境での実際のタスク——システム管理、DevOps、マルチステップCLIワークフロー——を評価する。より難しく、本番環境の利用をより代表しており、スキャフォールドによるインフレの影響を受けにくい。
Claude Opus 4.6はTerminal-Bench 2.0で65.4%、OSWorldで72.7%でトップを保持している。Capybaraクラスのモデルがこの数値を75〜85%の範囲に引き上げれば、自律型コーディングエージェントを動かすあらゆるチームにとって真の変革となるだろう。
SWE-bench Verifiedでは、状況はより圧縮されている:現在6つのモデルが互いに0.8ポイント以内に収まっている。Opus 4.6は80.8%、Gemini 3.1 Proは100万トークンあたり2ドル/12ドルで80.6%を出している。生のSWE-benchはもはや意味のある差別化要因ではない。Terminal-Benchと長いコンテキストの一貫性こそ、Opus 4.6がプレミアムを正当化する領域であり——Mythosが最も明確なケースを示す場所でもある。
「劇的に高い」が構造的に意味すること
下書きでは、「劇的に高い」が「ステップチェンジ」と並んで登場する——Anthropicのスポークスパーソンが公式に使ったのと同じフレーズだ。どちらの言葉も軽率ではない。Opus 4.1からOpus 4.6へのジャンプは同じ層内での世代的な改善だった。「ステップチェンジ」は種類の違うものを示唆している——連続する2つのOpusバージョン間の差というより、SonnetとOpusの間のギャップに近い。
コーディングでOpus 4.6を意味のある形で上回るモデルは、ソフトウェア開発、デバッグ、エージェント型ワークフローにとって重要なツールとなるだろう。未解決の問題は、いつ利用可能になるかとコストだ。それが正直な見方だ。パフォーマンスの主張はAnthropicの最近の実績を考えれば信憑性がある。検証はまだ手元にない。
エージェント型コーディングワークフローへの示唆
長いコンテキストのコードタスク
コーディングチームにとってのCapybaraクラスモデルの最も直接的な実用的示唆は、生のベンチマークスコアではなく——より優れた推論がスケールで何をもたらすか、だ。
Claude Codeの1Mコンテキストウィンドウは現在Opus 4.6でGAとなっており、コンパクション後に約83万トークンが使用可能——モノリポ全体や完全なドキュメントセットに十分な量だ。同じウィンドウに適用されるコーディングでOpus 4.6を劇的に上回るモデルは、大規模なコードベース全体でのアーキテクチャ理解の向上と、マルチファイルリファクタリングでの推論エラーの減少を意味する。コンテキストウィンドウは変わらない。その中の推論の質が変わるのだ。
今日、大規模なコードベース分析——5万行以上のソースをロードしてモデルに全体像を理解させるような作業——を行っているチームにとって、これが最も重要な実用的なアップグレードパスだ。
マルチステップデバッグエージェント
Anthropicはエージェント型ワークフローの重要な一歩として、Opus 4.6のリリースとともにAgent Teamsを実験的機能として出荷した。1つのセッションがチームリードとして機能し——作業を調整し、タスクを割り当て、結果を統合する。チームメンバーは独立して作業し、それぞれ独自のコンテキストウィンドウを持ち、互いに直接コミュニケーションする。
マルチステップデバッグエージェントは、より優れたベースモデルの複合的な価値が最も明確になる場所だ。マルチエージェントセットアップでは、チームリードの計画品質が全体の運用をどれだけうまく行えるかを決定する。より強力なモデルは、より優れたタスク分解の決定を行い、サブエージェントのためにより明確なタスク仕様を書き、統合エラーを早期に発見する。
リークされた下書きは、ソフトウェアコーディングをサイバーセキュリティと並んでCapybaraがOpus 4.6を「劇的に」上回る領域として明示的に挙げていた。そのギャップがTerminal-Benchスタイルのタスクで本物かつ実質的なものであれば、誤った仮定から回復するための人間の介入をより少なく必要とする、より信頼性の高いマルチステップデバッグエージェントに直接転換されるだろう。
自律的なコードベース探索
これは実践的に私が最も興味を持っているユースケースだ。Claude Codeはコードベースを通じて問題をトレースし、根本原因を特定し、修正を実装する。そのトレースの質は、コンテキストウィンドウのサイズだけでなく、推論の深さの関数だ。
典型的な2026年のワークフローでは、開発者が高レベルの要件を提示し、リードエージェントがこれを異なるタスクに分解し、チームメンバーがModel Context Protocolを利用して外部ツールにアクセスし、テストを実行し、セキュリティ監査を同時に行う。そのようなセットアップでオーケストレーターとして動作するCapybaraクラスのモデルは、ワークフロー全体をより自律的にする——つまり、より少ない明確化リクエスト、より優れた初期タスク分解、サブエージェントが予期しない状態に陥った際のより信頼性の高い自己修正を意味する。
MythosがまだAvailableでない間にビルダーがすべきこと
現在のユースケースにおけるOpus 4.6のベンチマーク方法
今すぐできる最も有用なことは、Opus 4.6に対して自分自身の評価を実行すること——ベンチマークに対してではなく、実際のワークロードに対して。SWE-benchのような汎用ベンチマークは、標準化されたスキャフォールディングを使った孤立したイシュー解決をテストする。あなたの本番コーディングエージェントには特定のコードベース構造、特定のタスクセット、特定の障害モードがある。重要なのはそれらだ。
コーディングエージェントの実用的なベースライン評価はこんな形かもしれない:
# シンプルなタスク成功率トラッキング
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# 同じ20〜30の代表的なタスクをOpus 4.6で実行する
# トラッキング:最初の試みで成功したか?何ターン必要だったか?
# 1Mコンテキストウィンドウのどの程度を消費したか?
# どこで失敗したか——推論エラー、ツール使用、またはコンテキストオーバーフロー?これが重要な理由:Mythosが利用可能になったとき、その能力向上があなたの特定のワークフローにとってコストプレミアムを正当化するかどうかを評価するための真のベースラインが手元にある。Anthropicの内部テストスイートでの「劇的に高い」が、あなたの特定のコードベース構造とタスク分布で意味のある差異に転換されるかどうかは未知数だ。
「最良のモデル」はそれとのコミュニケーション方法にマッチするものだ。優れたハーネスの中級モデルは、劣悪なハーネスのフロンティアモデルに勝る。あなたのハーネス品質——プロンプトエンジニアリング、ツール設定、CLAUDE.md構造——は今改善できる変数だ。Mythosは設計の悪いエージェントアーキテクチャを修正しない。
より有能なモデルとともにスケールするアーキテクチャ上の決定
朗報は、適切に設計されたエージェントアーキテクチャはルーティング層でモデルに依存しないということだ。今から構築する価値のあるパターン:
オーケストレーションを実行から分離する。 タスクを分解し、ファイルを割り当て、出力をレビューするオーケストレーターエージェント——実装のための専門サブエージェントによってサポートされる——は、単一のパラメータ変更でベースモデルを交換できる。この分離を今構築すれば、Mythosへのアップグレードはアーキテクチャのリファクタリングではなく設定の更新になる。
CLAUDE.mdをセッション固有のプロンプティングではなくランタイムコンテキストとして使用する。 CLAUDE.mdファイルはリポジトリ内のAIエージェントの「憲法」として機能し——エージェントが人間のナノマネジメントなしに動作できるようにするプロジェクトアーキテクチャ、コーディング標準、ビルドコマンドに関する必要なコンテキストを提供する。適切に構造化されたCLAUDE.mdは今日のOpus 4.6でのタスクごとの探索コストを削減し、明日のより強力なモデルからの利益を増幅させる。
コンテキストの制限に反するのではなく、1Mコンテキストウィンドウのために設計する。 ファイルロード戦略、チャンキングロジック、コンテキスト管理を1Mウィンドウ内で機能するよう既に再構築したチームは、同じウィンドウ全体でMythosの推論能力を最大限に活用する準備が整う。天井が上がらないと仮定したコンテキスト制限の回避策を構築しないこと。
コーディング特化チームがローンチ時に注目すべきこと
開発者にとって最も重要なシグナルは、一般的なエンタープライズのシグナルとは異なる。コーディングに特化したチームに特に関連するもの:
ローンチ時のSWE-benchとTerminal-Benchのスコア。 Anthropicは歴史的にモデルリリースと共にこれらを公開してきた。MythosがCapybara「劇的に高い」という主張を実現するなら、Terminal-Bench 2.0のスコアがOpus 4.6の65.4%を意味のある形で上回ることが期待される。75%以上へのジャンプはエージェント型ワークフローにおける主張を検証するだろう。
Claude Codeのモデル文字列の更新。 Claude CodeのドキュメントとAPIモデルの概要で新しいモデルエイリアスを確認する。Claude Codeは歴史的に、新しいフラッグシップリリースから数日以内にデフォルトモデルを更新してきた。Mythosが公開APIに出荷されれば、コーディングチームにとってここで最初に表面化する。
Agent Teamsの互換性発表。 Agent TeamsはOpus 4.6とともに実験的として出荷された。MythosがローンチでAgent Teamsにネイティブに統合されるか——それとも別の設定が必要か——によって、チームがそれをマルチエージェントワークフローに組み込める速さが決まる。
Anthropicの変更履歴と価格ドキュメント。 これら2つのページは、プレスアナウンスの前の最も早い信頼できるシグナルだ。新しいモデル文字列と新しい価格行がここに最初に表示される。
FAQ
Claude Mythosは今コーディングタスクに使用できますか?
いいえ。2026年4月初頭時点で、Claude MythosまたはCapybaraクラスの公開APIエンドポイントは存在しない。Claude Mythos / CapybaraはAnthropicが選定した少数の早期アクセス顧客のみが利用可能であり、公開API、発表された価格設定、確認されたリリース日はない。SWE-bench Verifiedで80.8%、Terminal-Bench 2.0で65.4%のClaude Opus 4.6が、引き続き最良の公開利用可能なオプションだ。
Claude MythosはClaude Codeで動作しますか?
ほぼ確実にyes、最終的には。Claude Codeのアーキテクチャはモデルに依存しない;新しいフラッグシップへの切り替えは単一のパラメータ変更だ。しかし、これはローンチ時のMythosについては確認されていない。
AIコーディングツールを構築するためにMythosを待つべきですか?
いいえ。Anthropicは「一般リリースの前にはるかに効率的になる必要がある」と述べている。今Opus 4.6で構築することは、Mythosが到着したときにアーキテクチャが本番で検証済みであることを意味する。アップグレードはモデル文字列のスワップになる。待つチームは追いかける立場になる。
前回の記事:




