WaveSpeedのZ-Image-Turbo LoRAでカスタムスタイルを適用する(最大3つのLoRA)
Z-Image-Turbo LoRAを使用して、カスタムスタイル、キャラクター、ブランドアイデンティティを適用できます。最大3つのLoRAをスタックし、1画像あたり$0.01。トレーニングガイド付き(1000ステップあたり$1.25)。

こんにちは、Doraです。私と同じように、モックアップがブランドからずれ続けるのに悩んでいませんか?ティールに傾きがちなブルー、端がぼやけるロゴマーク、なんとなく惜しい商品写真。ドラフトなら「だいたい合ってる」でも問題ないけれど、ノイズは積み重なる。そこで先週、WaveSpeedのZ-Image-TurboでLoRAを試してみました。目新しさを追いかけたわけではなく、「だいたい合ってる」を「よし、出せる」に変えられるか、プロンプトを付きっきりで世話しなくてもいいかを確かめるためです。
これは私のメモです。うまくいったこと、詰まったところ、そして一度セットしたら邪魔にならないようにする方法。
LoRAとは何か?
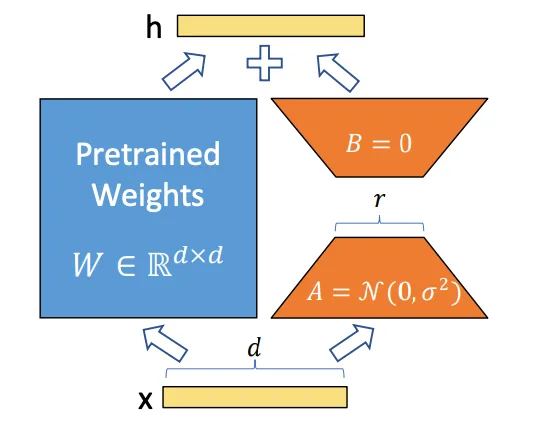 LoRA(Low-Rank Adaptation)は、大きなモデルを丸ごと再学習させずに、特定のスタイル・キャラクター・美的感覚へと誘導する、小さくターゲットを絞ったレイヤーです。着脱可能な柔らかなレンズのようなものだと思ってください。ベースモデルは幅広いスキルを保ったまま、LoRAがそこに「好み」を教え込みます。
LoRA(Low-Rank Adaptation)は、大きなモデルを丸ごと再学習させずに、特定のスタイル・キャラクター・美的感覚へと誘導する、小さくターゲットを絞ったレイヤーです。着脱可能な柔らかなレンズのようなものだと思ってください。ベースモデルは幅広いスキルを保ったまま、LoRAがそこに「好み」を教え込みます。
実用上、LoRAファイルはコンパクトで学習が速く、差し替えコストも低い。最後の点がワークフローにとって重要です。ブランドパレットやキャラクターごとに別々のモデルチェックポイントは持ちたくない。速いバックボーン(Z-Image-Turbo)ひとつと、いくつかの交換可能なダイヤルで済ませたいのです。
Z-Image-TurboにLoRAを使う理由
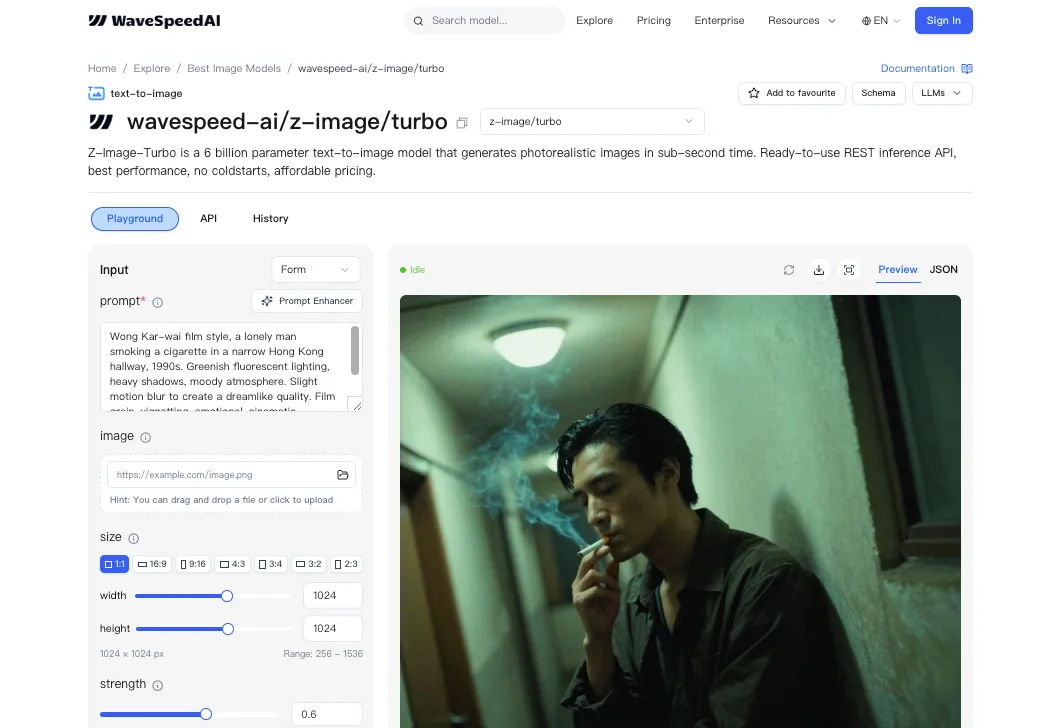 WaveSpeedのZ-Image-Turboはスピード重視でチューニングされています。イテレーションには最適ですが、速さだけでは「スタイルの一貫性」という問題は解決しません。LoRAはそのギャップを埋めてくれます。
WaveSpeedのZ-Image-Turboはスピード重視でチューニングされています。イテレーションには最適ですが、速さだけでは「スタイルの一貫性」という問題は解決しません。LoRAはそのギャップを埋めてくれます。
- ベースモデルのキビキビとした動作を維持しつつ、
- あらかじめ用意されたLoRAでルックやキャラクターを付加する、
- あるいは自分のアセット用に小さなカスタムLoRAを学習させることができます。
驚いたのは、scaleパラメーターが与えてくれるコントロールの幅です。小さいscale(0.3〜0.6)ではベースモデルの強みが保たれ、高い値(0.8〜1.0)では学習済みスタイルがより強く押し出されます――強すぎることもありました。私は低いところから始めて、ちょうどいいと感じるまで少しずつ上げていきました。この単純な習慣だけで、その週のうちに再レンダリングが約3分の1減りました。
既製LoRAを使う
最初は既製LoRAから試しました。境界感覚をつかむ前に何かを学習させたくなかったからです。WaveSpeedはLoRAをプラグインのように扱います。ファイルを指定してscaleを設定すれば、あとは走るだけです。
互換性のあるLoRAを探す
互換性はフォーマットとベースモデルファミリーに依存します。同じまたは近い拡散バックボーンで学習されたLoRAであれば(Z-Image-Turboまたはその系譜と互換性ありと明記されているもの)、概ねうまく動きました。私が確認するチェックリスト:
- 同一または隣接するベースモデルファミリー、
- 提供されていればバージョンノート(日付+モデルタグ)、
- 特定のヒットだけでなく多様性を示すプレビューギャラリー。
LoRAが「完璧すぎる」に見えたとき、私は過学習を疑いました。実際のテストでも、そういったものは狭い範囲のプロンプト以外で崩れる傾向がありました。質の高いセットは、ライティングやカメラの指示を変えても耐えてくれました。
APIパラメーター:pathとscale
 WaveSpeedのAPIはLoRAごとにシンプルな構造を使います。path(LoRAファイルの場所)とscale(適用の強度)です。pathはホストされたWaveSpeedアセットか、自分で管理する署名済みURLが使えます。scaleはfloat値です。私はほとんど0.35〜0.7の間で使っていました。0.3以下だと効いているかわからないことが多く、0.8以上だとコンポジションを強引に上書きされることがありました。
WaveSpeedのAPIはLoRAごとにシンプルな構造を使います。path(LoRAファイルの場所)とscale(適用の強度)です。pathはホストされたWaveSpeedアセットか、自分で管理する署名済みURLが使えます。scaleはfloat値です。私はほとんど0.35〜0.7の間で使っていました。0.3以下だと効いているかわからないことが多く、0.8以上だとコンポジションを強引に上書きされることがありました。
実際の使用から気づいた小さな注意点:pathが間違っているか、適切なトークンなしにアセットが非公開の場合、派手なエラーが出るとは限りません――単にベースモデルそのままのような画像が返ってくるだけです。なんだか見慣れた感じがすると思ったら、pathを再確認しました。
複数のLoRAをスタックする(最大3つ)
LoRAは最大3つ重ねることができます。カラー処理用、ブランドテクスチャ用、キャラクター特徴用とそれぞれ試してみました。うまくいきましたが、それぞれのscaleを調整してからの話です。2つのLoRAが衝突すると(たとえば、一方がソフトなフィルムグレインを主張し、もう一方がシャープな商品ツヤを加えようとする場合)、画像は決め手のない見た目になります。私のルール:
- それぞれを0.3から始め、
- アンカーLoRA(譲れないルック)を特定して、
- そちらをゆっくり上げながら、
- 他が競合するのではなく補完するように微調整する。
スタックは、ブランドの雰囲気と繰り返し登場するキャラクターの両方が必要なときに時間を節約してくれました。3つの重いスタイルを一度に詰め込もうとしたときは、節約にはなりませんでした――そうなると試行錯誤に逆戻りです。
API実装
実際に使っている小さなスクリプトでの接続方法を紹介します。実際に本番で使うプロンプト——バリエーションのある商品モックアップと、社内ドキュメント用のキャラクターカット数枚——を使いました。
LoRAパラメーターの構造
リクエストボディにはloras配列を含めます。各アイテム:
- path: 文字列(WaveSpeedアセットのパスまたは署名済みURL)
- scale: float(0.0〜1.0:最初は0.3〜0.7を推奨)
その他のZ-Image-Turboパラメーター(prompt、negative_prompt、seed、steps、width/height)は通常通りに機能します。seedはscaleの変化を一対一で比較するのに役立ちました。
Pythonコード例
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/api/v3/wavespeed-ai/z-image/turbo"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# アカウント設定によってbase64画像またはURLが返されます
print(result.get("images", []))私の環境では、Z-Image-Turboで16ステップがプレビュークオリティには十分でした。最終的な画像では22〜24ステップに上げました。それによりアカウント上で画像1枚あたり約0.3〜0.6秒追加されましたが、問題ありませんでした。
LoRAスケールのバランス調整
私はこのように反復しました:
- seedを固定し、
- すべてのLoRAを0.3に設定し、
- アンカーを選んでちょうど良い感じになるまで0.1ずつ上げ、
- 他を0.05〜0.1ステップで微調整する。
scaleを調整する間seedを固定しておくことで、効果を直接確認できました。バランスが気に入ったら、バリエーションのためにseedを解除。最初は時間がかかりました——感覚をつかむだけで15〜20分費やしました。しかし3日目には、プロンプトの調整をやめていることに気づいていました。scaleがスタイルを運んでくれるので、私はレイアウトとコピーに集中できるようになりました。
カスタムLoRAのトレーニング
既製品を試したあと、あるクライアントのボトルの形状とラベルスタイル用に小さなLoRAをトレーニングしました。ネックの角度とラベルの光沢がずれ続けて生じるやり取りを削減するためです。
トレーニングデータの準備(ZIPアップロード)
18枚の画像を集め、背景をクリーンにして、メタデータを一貫させました。ZIPに圧縮し——シンプルなフォルダ、小文字のファイル名、スペースなし——でアップロードしました。ラベルのテキストが重要な画像には1枚につき3〜4つのキャプションを追加しました。重要でない場合はキャプションを最小限に抑えました。キャプションが多いほどラベルが読みやすく保たれました。
小さなつまずき:ほぼ同一の画像は役に立ちませんでした。重複に近いものを削除したところ、過学習が減りました。
トレーニングパラメーター
軽めに設定しました:
- 解像度:768の正方形クロップ、
- バッチサイズ:1、
- 学習率:保守的なデフォルト、
- トレーニングステップ:スタイル+形状に3,000〜6,000、
- ネットワークランク(r):控えめに——高くすると望む以上に「うるさく」なりました。
ステップを〜8,000を超えて増やすと、指定していないプロンプトにもボトルが押し込まれるようになりました。理想的ではありません。ステップを少なめにしてクリーンなデータセットで勝りました。
料金:1,000ステップあたり$1.25
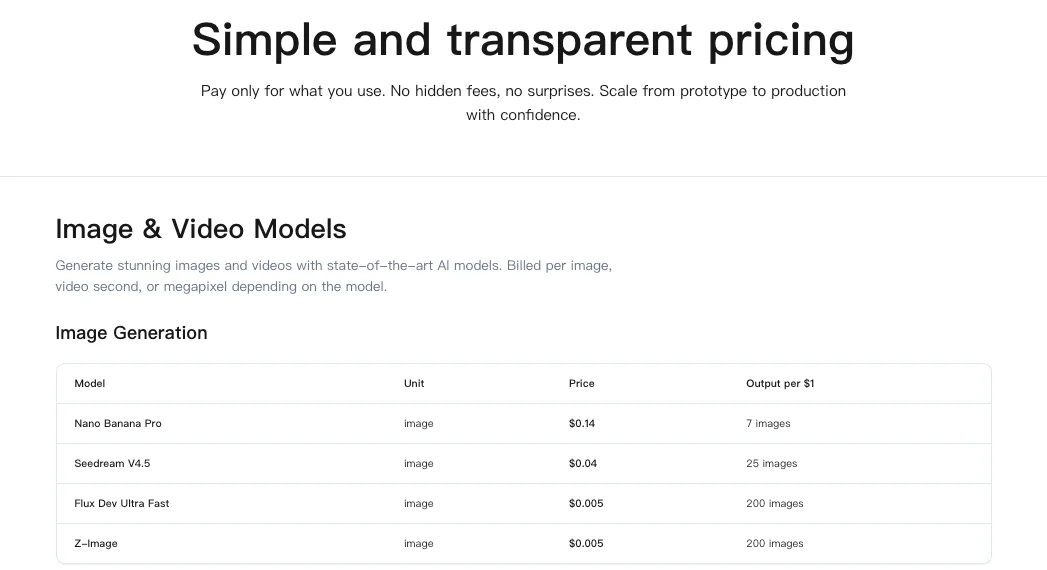 私の2回のトレーニング(3,500ステップと5,000ステップ)は、1,000ステップあたり$1.25で合計$10.63でした。LoRAが数ヶ月使い続けてくれるなら、妥当な価格です。
私の2回のトレーニング(3,500ステップと5,000ステップ)は、1,000ステップあたり$1.25で合計$10.63でした。LoRAが数ヶ月使い続けてくれるなら、妥当な価格です。
標準的なトレーニング予算
今の私が組む予算:
- スタイルのみLoRA:2,000〜4,000ステップ($2.50〜$5.00)、
- 表情つきキャラクター:5,000〜8,000ステップ($6.25〜$10.00)、
- 商品の形状+ラベル詳細:3,000〜6,000ステップ($3.75〜$7.50)。
まず短めのパスを1回走らせて結果を確認し、見込みがあればステップを追加します。長い過学習セッション1回より、短い2回のほうが優ります。
ユースケース
Z-Image-TurboのLoRAが出荷を速めてくれた場面です——毎日ではなく、タスクが合致したときに確実に。

ブランドスタイルの一貫性
プロンプトのたびにブランドの手がかりを打ち込むのに疲れているなら、0.4〜0.6の控えめなスタイルLoRAがカラー・コントラスト・テクスチャを安定させてくれます。私はSNSバリエーションやウェブバナーにこれを使いました。出力を素晴らしくするわけではない——一貫させるだけです。それが目的です。「雰囲気を直して」のラウンドツーをスキップできて、納品物1つにつき5〜7分ほど節約できました。
キャラクターLoRA
社内ドキュメントやオンボーディング画面に登場する軽量マスコット用に、キャラクターLoRAがさまざまなアングルで特徴を安定させてくれました。ソフトなカラー処理と重ねてもうまくいきましたが、キャラクターのscaleを0.35まで下げてからの話です。それ以上だとライティングを強引に上書きしてしまいました。一度調整が決まると、変な心理的負荷がなくなりました——顔がずれるかどうか心配しなくて済むようになったのです。
商品固有の美的感覚
カスタムボトルLoRAがラベルのゆがみを減らし、クローズアップ全体でネックのジオメトリを保ってくれました。完璧ではありません——タイトな反射はまだ数回試行が必要でした——が、使い物にならないレンダリングの数が減りました。静かな勝利は予測可能性です。「リネンの上で四分の三アングル」と入力すると、それが返ってくる。予想外のバリエーションではなく。
これが向いている人:自分が何を望むかすでに知っていて、モデルと再交渉するのに疲れた人。向いていない人:毎回まったく新しいスタイルを探求している人。LoRAはスタビライザーです。サプライズより少ない方がいい、と感じる人が使うと光ります。





