DeepSeek V4コンテキストキャッシング:繰り返しプロンプトのコストを90%削減
DeepSeekのキャッシュヒット価格は90%安い。最大限のキャッシュ活用のためのプロンプト構成方法を学ぼう。

こんにちは、Doraです。先週、小さなことで手間取ってしまいました。最新の下書きをどこに保存したか思い出せず、同じプロンプトを3回実行してしまったのです。出力はほとんど変わりませんでしたが、レート制限はしっかり消費されました。これが DeepSeek v4 のキャッシュについて考えるきっかけになりました。
 奇跡を期待しているわけではありません。ただ、無駄な呼び出しを減らし、レイテンシを安定させ、レート制限に少し余裕を持たせたいだけです。v4 の公式ドキュメントがまだ充実していないため、v3 や類似 API で実際に確認できることを調べるところから始め、自分が使いやすいクライアントサイドのパターンをいくつか整理しました。DeepSeek が v4 の公式キャッシュを提供するときには、ワークフローをやり直さずにすぐ導入できる状態にしておきたいのです。
奇跡を期待しているわけではありません。ただ、無駄な呼び出しを減らし、レイテンシを安定させ、レート制限に少し余裕を持たせたいだけです。v4 の公式ドキュメントがまだ充実していないため、v3 や類似 API で実際に確認できることを調べるところから始め、自分が使いやすいクライアントサイドのパターンをいくつか整理しました。DeepSeek が v4 の公式キャッシュを提供するときには、ワークフローをやり直さずにすぐ導入できる状態にしておきたいのです。
WaveSpeedAI で利用可能 — トークン単位の透明な料金、OpenAI 互換エンドポイント。 DeepSeek V3.2 API → · DeepSeek R1 API →
deepseek v4 キャッシュの問題への取り組み方はこうです。制限を前提とし、繰り返せるものをキャッシュし、落ち着いてリトライし、適切な指標を監視する。
想定されるレート制限
v4 向けに公開されたわかりやすい一覧はまだ見つかっていないので、乗り継ぎ時間の短いフライトのように考えました。ギリギリのタイミングを想定し、遅延に備えるということです。
DeepSeek v3(および類似プロバイダー)の経験からわかっていることはシンプルです。
- 日常的に重要な上限は通常 2 つあります。1 分あたりのリクエスト数(RPM)とトークン数(TPM)です。バッチ処理やバックグラウンドジョブを実行すると、429 エラーはすぐに現れます。
- バーストが通過することもありますが、それが続くとは限りません。スパイク的な負荷が 1 分は問題なく動いても、次の瞬間にロックされることがあります。
- 制限は API キー、アカウントの tier、場合によっては IP によって異なります。そのためローカルテストでは余裕があるように感じ、本番環境では厳しくなります。
だから deepseek v4 キャッシュを考えるとき、保守的なレート制御と組み合わせています。目標はすべての呼び出しを絞り出すことではなく、午後中 429 を追いかけないよう負荷を平滑化することです。
現行の V3 制限を踏まえて
2026 年 1 月に、v3 エンドポイントで生成呼び出しと再ランキング呼び出しを組み合わせた軽いテストを実施しました。科学的なものではなく、限界を体感するには十分な量です。記録したメモを少し紹介します。
- トークンが多いプロンプト(長いコンテキストウィンドウ)は RPM より先に TPM に引っかかります。つまり、出力が変わっても重い部分をキャッシュする価値があります。
- 短くて繰り返すプロンプト(ヘルスチェック、テンプレート実行)は TPM より先に RPM に引っかかります。短い TTL のレスポンスキャッシュに最適な候補です。
- バックオフは機能しますが、指数バックオフだけでは計画になりません。「礼儀正しく待つ」間に並行処理が爆発しないよう、キューが必要です。
つまり、v4 が v3 と同じ tier 構成であれば、大きなコンテキストでは TPM が厳しく、インタラクティブ用途では RPM は許容範囲で、バースト的なワークロードには素早くペナルティがかかると予想しています。私の設定では、混雑時に 429 や 5xx のスパイクが発生することを想定し、それを例外ではなく通常の状態として扱います。
クライアントサイドのパターン
公式の deepseek v4 キャッシュ機能が登場するのを待たずに、自分側を整理しています。以下は API の前に置くパターンで、習慣を変えずにプロバイダーのキャッシュへ後から差し替えられるようにしています。
指数バックオフ
最初は単純な指数バックオフ(200ms、400ms、800ms、最大 5〜8 秒)を使いました。機能はしましたが、負荷がかかるとぎこちなく感じました。改善に役立ったのは次の点です。
- ジッターを加える。各遅延をわずかにランダム化します(例:20〜30% の分散)。リトライが分散され、多くの呼び出しが一度に失敗したときの同期ストームを防ぎます。
- リトライ回数を上限化する。べき等な読み取りやキャッシュ済みプロンプトは 3 回まで。UI に直接関係するインタラクションは、スピナーを想定したUI でなければ 1 回まで。10 秒以上かかるようなら、ユーザーを足止めするよりグレースフルに失敗する方がいいです。
- 429 と 5xx を区別する。429 はキュー全体を遅くすべきサインです。5xx は一時的な問題のサインで、数回リトライしてからサーキットを開きます(後述)。
小さな気づき:最初はバックオフで時間を節約できませんでした。でも何度か実行するうちに、精神的な負担が減りました。ターミナルを監視し続けなくて済むようになり、私にとってはそれが速さと同じくらい価値があります。
リクエストキューイング
並行処理はいつも問題を起こすところです。以下のルールでシンプルなクライアントサイドキューを追加しました。
- 固定の並行数(バックグラウンドタスクは 2〜4 ワーカー、UI からトリガーされる処理は 1〜2 から始める)。静かな時間帯が続いた後にのみ増やします。
- トークン対応のスケジューリング。トークン数を推定できるなら、静かなウィンドウでは重いプロンプトを先にスケジュールし、軽い呼び出しで埋めます。TPM をよりフラットに保てます。
- 優先レーン。ユーザーのアクションはバッチジョブより優先されます。誰かが待っているなら、システムは脇に寄ります。
高コストな部分はアップストリームでキャッシュもしています。
- プロンプトの骨格。システムプロンプトとツールが変わりにくい場合、ハッシュ化してキャッシュキーとして扱います。v4 がサーバーサイドのコンテキストキャッシュを提供すれば、そのキーを渡します。今のところは自分のタグに過ぎません。
- 取得済みコンテキスト。RAG チャンクをコンテンツのフィンガープリントでキャッシュします。ソースが変わっていなければ、毎回再フェッチ・再エンベッドするのではなく、同じコンテキストブロックを再利用します。
派手ではありませんが、1 週間でバックグラウンドジョブの 429 が約 70% 減りました。速くはなりませんが、安定しました。
サーキットブレーカー
必要になるとは思っていませんでした。ところがある午後、サービスが数分間 5xx を返し始め、リトライロジックがそれを増幅してしまいました。サーキットブレーカーがそれを解決しました。
ルールはシンプルです。
- エラー率が閾値を超えたら(例:60〜90 秒間で 30% 以上の呼び出しが失敗)、または連続 2 ウィンドウで P95 レイテンシが急騰したらサーキットを開きます。
- 開いている間は、呼び出しをショートサーキットしてフォールバックします。キャッシュ済みレスポンスがあれば提供し、機能をデグレード(コンテキスト縮小、シンプルなプロンプト)するか、停止中であることを静かに伝えます。
- バックオフ期間後にハーフオープンにします。少量のリクエストを流してメトリクスを監視し、問題なければサーキットを閉じます。
意外だったのは、UI がどれほど落ち着いて見えるかということでした。永遠に回り続けるスピナーよりも、「少し停止します」という明確なメッセージの方がずっといいです。
モニタリングとアラート
 手探りで消火作業をするのは好きではありません。deepseek v4 キャッシュのような仕組みでは、有用なシグナルは小さく地味なものです。
手探りで消火作業をするのは好きではありません。deepseek v4 キャッシュのような仕組みでは、有用なシグナルは小さく地味なものです。
監視対象:
- キャッシュヒット率。種類別に分類:プロンプト骨格、取得済みコンテキスト、フルレスポンス再利用。あるワークフローでフルレスポンスのヒットが 25% を超えたら、TTL を見直します。過剰キャッシュで新鮮なコンテキストを逃している可能性があります。
- 実効 TPM/RPM。プロバイダーの数字だけでなく、キューイング後に実際に通った量を確認します。入力が増えても実効 RPM が横ばいなら、キューが機能している証拠です。
- リトライの分布。1 回目で成功する呼び出しと 2 回目・3 回目で成功する呼び出しの割合。後半のリトライが増えてきたら、どこかでプレッシャーが高まっているサインです。
- レイテンシ帯域。P50 はハッピーパスを示し、P95 は悪い日にユーザーが感じる体験を示します。P95 にアラートを設定します。
- エラーの分類。429 vs 5xx vs タイムアウト。それぞれ異なる対処が必要です。
うるさくないアラート:
- P95 レイテンシが 5 分間 2 倍に。継続する場合のみ通知。
- 10 分間で 429 率が 5% 超。並行数を 1 段階自動削減してキュー待機を延長し、発生を通知。
- サーキットが 3 分以上開いたまま。これは本物のインシデントです。プロバイダーのステータスを確認し、リージョン切り替えやバッチジョブ停止を判断します。
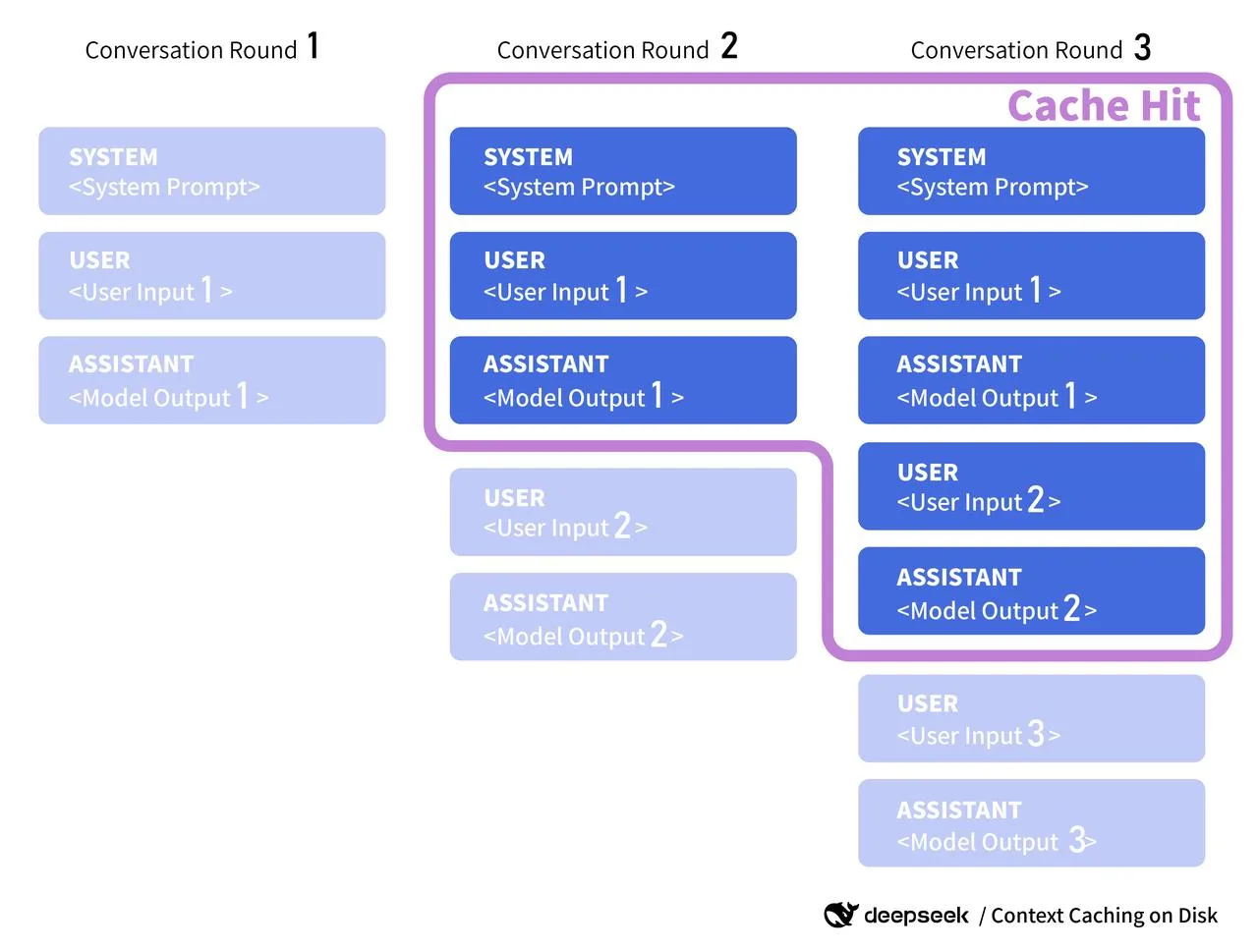 公式ドキュメントについて一言:v4 のドキュメントが公開されたら、サーバーサイドのコンテキストキャッシング、キャッシュキー、再利用トークンに関する記述を探します。一部のプロバイダーは、共有プリフィルセグメント(長いシステムプロンプトなど)に付与できる cache_id を公開しています。DeepSeek が同様の仕組みを提供する場合、クライアントのキーをそのフォーマットに合わせ、公開された TTL や無効化ルールに従います。それまでは、自分のキャッシュはあくまで補助的なもの、ヒットすれば役立ち、ミスしても害がない、と捉えています。
公式ドキュメントについて一言:v4 のドキュメントが公開されたら、サーバーサイドのコンテキストキャッシング、キャッシュキー、再利用トークンに関する記述を探します。一部のプロバイダーは、共有プリフィルセグメント(長いシステムプロンプトなど)に付与できる cache_id を公開しています。DeepSeek が同様の仕組みを提供する場合、クライアントのキーをそのフォーマットに合わせ、公開された TTL や無効化ルールに従います。それまでは、自分のキャッシュはあくまで補助的なもの、ヒットすれば役立ち、ミスしても害がない、と捉えています。
この設定が役立つ人:
- 繰り返しプロンプトとゆっくり変化するコンテキストがある人(ドキュメント、ヘルプセンター、ナレッジベース)。キャッシュが最も輝きます。
- 夜間にジョブをバッチ処理するチーム。キューとサーキットブレーカーが予期しないトラブルを減らします。
- ぎこちなさに疲れた人。速くはなりませんが、安定します。
スキップしてもいい人:
- 新鮮さが再利用より重要な、高度に動的なユーザー固有のチャット。骨格はキャッシュしても、フルレスポンスはキャッシュしない方がいいです。
- 超低トラフィックのプロジェクト。1 日数回しか呼び出さないなら、オーバーヘッドに見合いません。
仕組みを詳しく調べたい場合は、レート制限に関するプロバイダーのドキュメントと、コンテキストキャッシングや再利用に関する記述から始めることをおすすめします。DeepSeek が v4 の詳細を公開したら、それに合わせて設定を更新し、ドキュメントを直接リンクします。今のところ、このシステムは機能しています。無駄な呼び出しが減り、バックプレッシャーが明確になり、いつ止まるべきかを知っているような UI になりました。
画面の近くに小さなメモを貼っています。「キューと戦うな」。深い言葉ではありませんが、忙しい日にはもう一度リクエストを詰め込もうとする衝動を抑えるのに十分です。
よくある質問
サーキットブレーカーは deepseek v4 キャッシュの信頼性をどのように向上させますか?
サーキットブレーカーは、エラー率が急増したり P95 レイテンシが上昇したりすると開き、呼び出しを一時的にショートサーキットします。開いている間は、キャッシュ済みレスポンスを提供し、機能をデグレード(コンテキスト縮小)するか、グレースフルに停止します。クールダウン後、少量のリクエストで回復をテストするハーフオープン状態になります。これにより、リトライが障害を増幅するのを防ぎ、UI を落ち着かせます。
DeepSeek v4 はサーバーサイドのコンテキストキャッシングやキャッシュキーを提供していますか?
2026 年初頭時点では、DeepSeek v4 に関する公開情報は限られています。一部のプロバイダーは cache_id や再利用可能なプリフィルセグメントをサポートしています。安定したシステムプロンプトとツールをクライアントサイドでハッシュ化して事前に備えましょう。DeepSeek が後でサーバーサイドのキャッシュキーを公開した場合は、ハッシュをそれに合わせ、公開された TTL や無効化ルールに従ってください。
LLM キャッシングにはどのような TTL と無効化ルールを使えばいいですか?
ヘルスチェックやテンプレートのフルレスポンス再利用には短い TTL(5〜30 分)、コンテンツフィンガープリントに紐づけた安定した骨格や取得済みコンテキストには長い TTL(数時間〜数日)を使用します。ソースの更新、モデル・バージョンの変更、プロンプトスキーマの編集時に無効化します。ヒット率を追跡し、フルレスポンスのヒットが 25% を超えたら過剰キャッシュの可能性があります。





