Muse Spark vs Llama 4: Pergeseran Strategis Meta
Meta beralih dari Llama berbobot terbuka ke Muse Spark yang tertutup. Apa yang berubah, mengapa hal ini penting bagi para pengembang, dan apakah versi open-source di masa depan realistis.

Meta baru saja meluncurkan seri model baru. Jika kamu telah membangun sesuatu di atas Llama 4 dalam setahun terakhir, kamu mungkin bertanya-tanya apakah harus melanjutkan atau mulai merencanakan migrasi.
Saya Dora. Saya habiskan kemarin membaca semua dokumentasi yang diterbitkan Meta, melakukan cross-reference dengan benchmark pihak ketiga, dan mencoba mencari tahu apa arti ini sebenarnya bagi orang-orang yang menggunakan Llama dalam stack mereka. Artikel ini menguraikan apa yang berubah, apa yang tidak, dan di mana posisi para pembangun saat ini.
Apa yang Berubah Antara Llama 4 dan Muse Spark
Arsitektur: Sembilan Bulan, Dibangun dari Awal
Meta Superintelligence Labs — unit yang dibentuk setelah Alexandr Wang bergabung sebagai chief AI officer pada pertengahan 2025 — membangun ulang seluruh stack AI dari awal. Infrastruktur baru, arsitektur baru, pipeline data baru. Itu bukan salinan marketing; itulah yang dinyatakan blog teknis Meta sendiri. Muse Spark adalah model pertama dari hasil pembangunan ulang tersebut.
Llama 4 menggunakan arsitektur Mixture-of-Experts dengan bobot terbuka. Muse Spark adalah model penalaran multimodal secara native — artinya kemampuan visual tidak ditambahkan belakangan, melainkan diintegrasikan sejak awal. Model ini mendukung penggunaan alat, visual chain of thought, dan orkestrasi multi-agen. Llama 4 tidak memiliki satu pun dari kemampuan-kemampuan ini sebagai fitur native.
Model ini juga memperkenalkan mode penalaran bertingkat: Instant untuk kueri kasual, Thinking untuk pekerjaan langkah demi langkah, dan mode Contemplating yang menjalankan beberapa sub-agen secara paralel. Mode terakhir itu adalah jawaban Meta atas Gemini Deep Think dan penalaran extended GPT Pro.
Efisiensi: Klaim Meta, Bukan Kesimpulan Independen
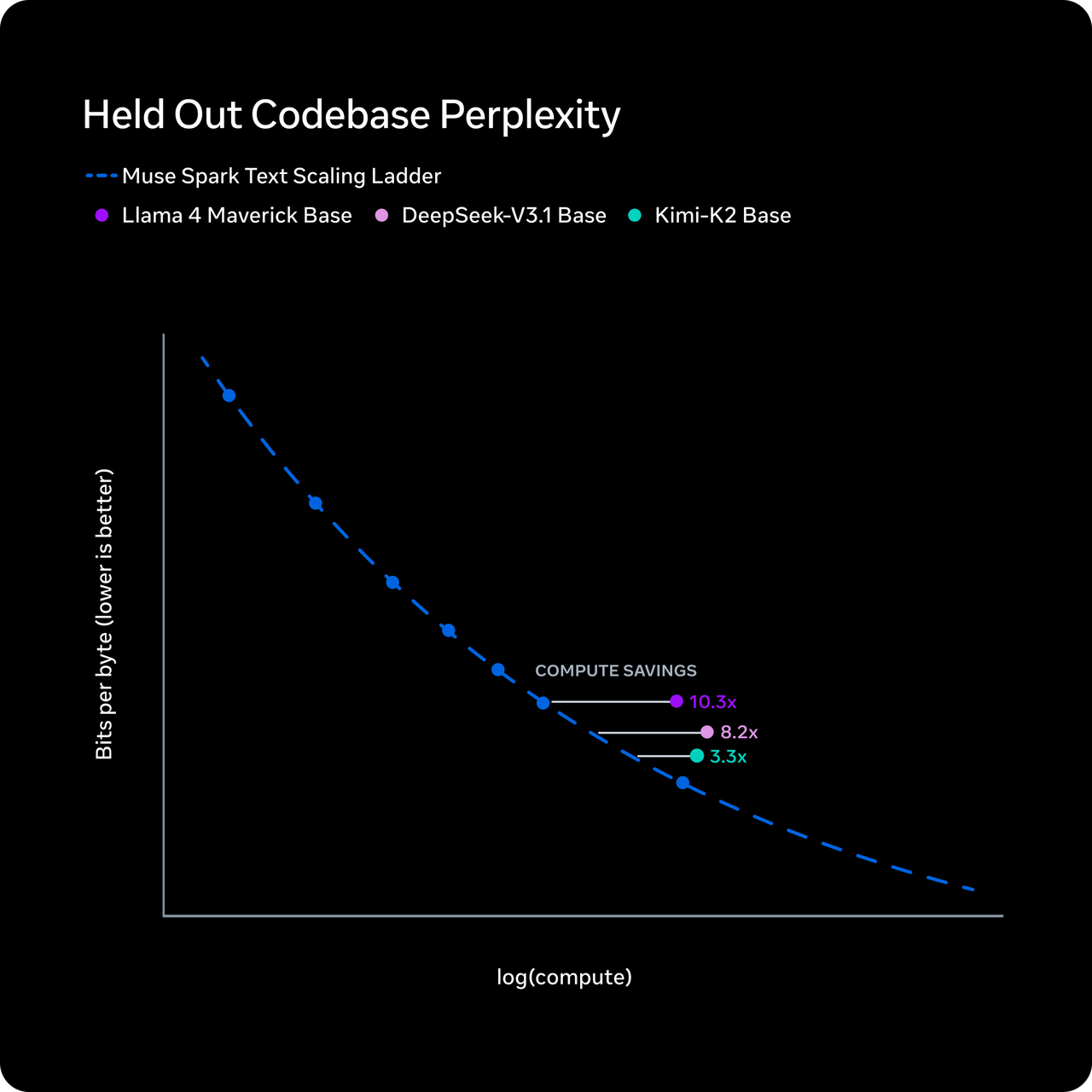
Meta mengatakan Muse Spark mencapai kemampuan setingkat Llama 4 Maverick menggunakan komputasi lebih dari sepuluh kali lebih sedikit. Mekanisme yang mereka jelaskan adalah “thought compression” — selama reinforcement learning, model dikenai penalti atas waktu berpikir yang berlebihan, memaksanya untuk bernalar dengan token lebih sedikit tanpa kehilangan akurasi.
Saya ingin menegaskan hal ini: ini adalah klaim Meta. Belum direplikasi secara independen. Angka efisiensi token dari Artificial Analysis memang menunjukkan Muse Spark menggunakan 58 juta output token untuk menjalankan seluruh Intelligence Index mereka — sebanding dengan 57 juta milik Gemini 3.1 Pro dan jauh di bawah 157 juta Claude Opus 4.6 atau 120 juta GPT-5.4. Jadi cerita efisiensi ini memiliki dukungan independen, setidaknya dari sisi output.
Kesenjangan Benchmark: 18 hingga 52
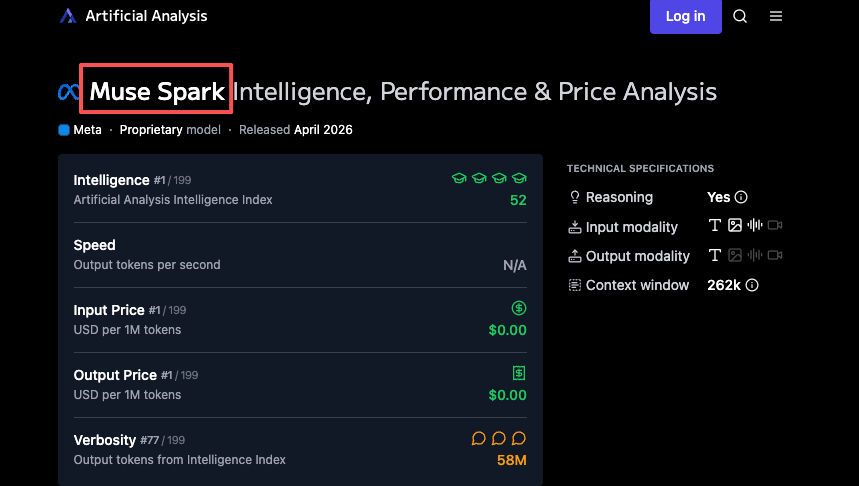
Menurut Artificial Analysis, Llama 4 Maverick mendapat skor 18 di Intelligence Index saat diluncurkan. Muse Spark mendapat skor 52. Ini menempatkannya di peringkat empat secara keseluruhan — di belakang Gemini 3.1 Pro Preview dan GPT-5.4 (keduanya di 57) serta Claude Opus 4.6 (53).
Satu catatan penting: Artificial Analysis mendapat akses awal dari Meta untuk melakukan benchmark model tersebut. Mereka menjalankan evaluasi mereka sendiri secara independen, tetapi aksesnya sendiri datang melalui Meta. Ini belum sepenuhnya merupakan benchmark publik yang sepenuhnya independen. Skornya berguna secara arah, bukan kebenaran mutlak.
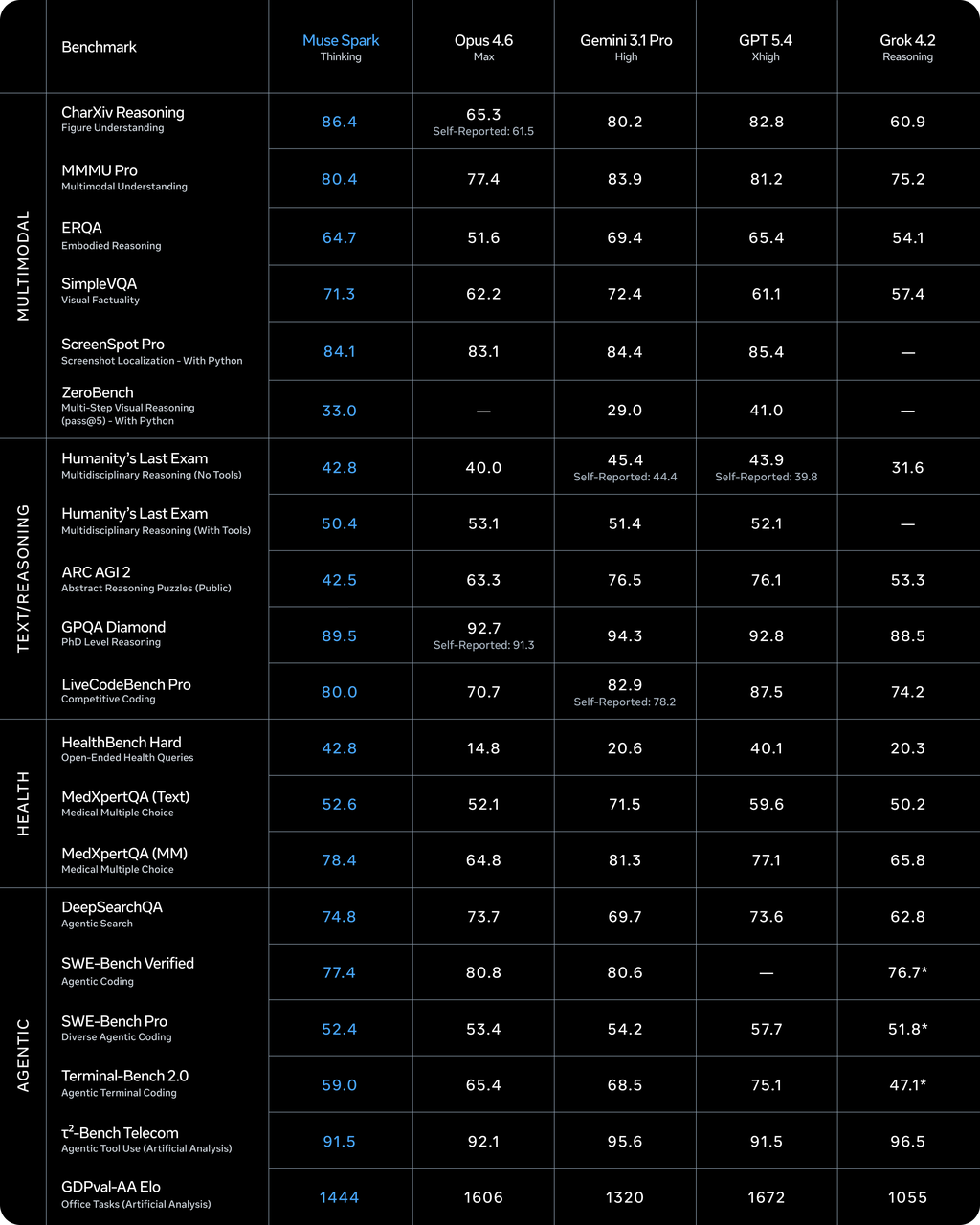
Di mana Muse Spark unggul: benchmark kesehatan (42,8 di HealthBench Hard, melampaui 40,1 milik GPT-5.4), penalaran visual (80,5% di MMMU-Pro, urutan kedua setelah Gemini 3.1 Pro), dan pemahaman grafik.
Di mana ia tertinggal: coding (Terminal-Bench Hard, di belakang Claude Sonnet 4.6 dan GPT-5.4), tugas agentic (GDPval-AA 1.427 ELO vs. 1.676 milik GPT-5.4), dan penalaran abstrak (ARC-AGI-2 di 42,5 vs. 76+ untuk kompetitor teratas). Meta secara eksplisit mengakui kesenjangan ini dalam blog teknis mereka, menyatakan bahwa mereka terus berinvestasi dalam “sistem agentic jangka panjang dan alur kerja coding.”
Pergeseran Open vs. Closed
Model Llama: Bobot Terbuka, Ekosistem Komunitas
Proposisi nilai Llama sangat jelas. Unduh bobotnya, jalankan di hardware milikmu sendiri, fine-tune untuk kasus penggunaanmu, bayar hanya untuk komputasi. Pendekatan bobot terbuka ini membangun ekosistem — ribuan varian fine-tuned di Hugging Face, deployment yang dihosting sendiri di seluruh startup dan perusahaan, seluruh industri kecil model terkuantisasi yang berjalan di GPU konsumen. Llama 4 Scout muat di satu H100. Maverick berjalan di RTX 5090 dengan kuantisasi.
Ekosistem itu masih ada. Model-model tersebut belum ditarik.
Model Muse Spark: Closed, Hanya Private Preview API
Muse Spark bersifat proprietary. Tidak ada bobot yang dapat diunduh. Tidak ada self-hosting. Saat ini ia menggerakkan Meta AI di seluruh aplikasi perusahaan — situs web Meta AI, dan segera di WhatsApp, Instagram, Facebook, Messenger, dan kacamata Ray-Ban AI. Pengembang eksternal dapat mendaftar untuk private preview API. Itu saja.
Ini lebih terkunci dibandingkan model OpenAI atau Anthropic, yang setidaknya menawarkan akses API publik. Seperti yang dicatat Fortune dalam liputannya, Muse Spark “bahkan lebih proprietary dari model proprietary berbayar yang ditawarkan oleh para pesaing Meta.”

“Kami Berharap Membuka Source Versi Masa Depan”
Postingan blog Meta menyertakan frasa ini. Zuckerberg menulis di Threads tentang rencana merilis “model yang semakin canggih yang mendorong batas inteligensi dan kemampuan, termasuk model open source baru.” Wang menyebut open-sourcing versi masa depan di X.
Tidak ada timeline. Tidak ada komitmen spesifik tentang model mana atau kapan. Tidak ada indikasi apakah “versi masa depan” berarti Muse Spark itu sendiri akhirnya dibuka, atau apakah cabang bobot terbuka yang terpisah akan terus berjalan secara paralel.
Bandingkan ini dengan manifesto Zuckerberg 2024 berjudul “Open Source AI is the Path Forward,” di mana ia berargumen bahwa membuka Llama tidak merusak pendapatan Meta. Itu delapan belas bulan yang lalu. Kalkulasi strategis jelas telah bergeser. Seperti yang diungkapkan analisis The Next Web, penutupan ini merupakan sinyal bahwa Meta kini menganggap dirinya berada dalam perlombaan di mana membagikan inovasi arsitektur berbiaya lebih tinggi daripada manfaatnya.
Di sinilah data saya berakhir. Apakah model Muse masa depan benar-benar dibuka adalah spekulasi. Saya akan memperbarui ketika ada sesuatu yang konkret.
Apa Artinya Bagi Para Pembangun yang Saat Ini Menggunakan Llama
Llama yang Dihosting Sendiri: Masih Layak, Tidak Dihentikan
Ketika VentureBeat bertanya langsung kepada Meta apakah pengembangan Llama telah berakhir, seorang juru bicara mengatakan: “Model Llama kami saat ini akan terus tersedia sebagai open source.” Kalimat itu dipilih dengan cermat. Ini mengonfirmasi bahwa model yang ada tetap tersedia. Tidak ada yang dikatakan tentang pengembangan Llama di masa depan.
Jika kamu menjalankan Llama 4 Scout atau Maverick dalam produksi hari ini, tidak ada yang berubah secara operasional. Bobotnya masih ada di Hugging Face. Fine-tune komunitas masih berfungsi. Infrastrukturmu tidak perlu dipindahkan.
Trade-off Operasional: Sekarang vs. Menunggu
Inilah situasi praktisnya. Jika kamu memiliki deployment Llama yang berjalan — pipeline inferensi yang sudah disetel, biaya yang dapat diprediksi, tim yang sudah familiar dengan parameternya — kamu memiliki sesuatu yang sudah diketahui. Harga API Muse Spark belum diumumkan. Akses API publik belum diumumkan. Preview privat hanya bersifat undangan.
Beralih dari model bobot terbuka yang dihosting sendiri ke API tertutup berarti melepaskan kendali atas latensi, uptime, struktur biaya, dan penanganan data. Untuk beberapa tim trade-off itu masuk akal. Untuk yang lain tidak. Intinya adalah kamu bahkan belum bisa mengevaluasi trade-off tersebut karena syarat API Muse Spark belum ada secara publik.
Alur Kerja Coding: Kesenjangan yang Diakui
Jika deployment Llama-mu menangani pembuatan kode, review kode, atau tugas apa pun yang menghadap developer, tidak ada alasan untuk melihat Muse Spark saat ini. Meta sendiri mengatakannya — coding adalah kelemahan saat ini. Di Terminal-Bench Hard, Muse Spark tertinggal dari Claude Sonnet 4.6 dan GPT-5.4. Di GDPval-AA, yang mengukur tugas kerja dunia nyata, ia mendapat skor 1.427 ELO dibandingkan 1.648 milik Claude Sonnet 4.6.
Sesuai dengan frekuensi saya. Milikmu mungkin berbeda. Tapi data sudah jelas untuk yang satu ini.
Mengapa Meta Melakukan Langkah Ini
Llama 4: Kegagalan yang Diakui
Llama 4 diluncurkan pada April 2025 dengan sambutan yang beragam. Kontroversi benchmark — Meta menggunakan “versi chat eksperimental” yang khusus dan belum dirilis untuk meningkatkan skor di LMArena — merusak kredibilitas. Model-modelnya sendiri solid untuk kelas beratnya tetapi tidak menggeser batas kemampuan. Pada pertengahan 2025, narasi yang beredar adalah bahwa Meta telah tertinggal dari OpenAI, Anthropic, dan Google.
Mandat Wang
Pada Juni 2025, Meta menghabiskan $14,3 miliar untuk mengakuisisi saham non-voting 49% di Scale AI dan membawa co-founder Alexandr Wang sebagai chief AI officer. Mandatnya eksplisit: kejar ketinggalan. Meta Superintelligence Labs dibentuk. Para peneliti direkrut dari OpenAI, Anthropic, dan Google dengan paket gaji yang dilaporkan mencapai ratusan juta dolar ketika ekuitas dimasukkan.
Sembilan bulan kemudian, Muse Spark adalah output pertama. Apakah ini membenarkan investasi tersebut tergantung pada apa yang akan datang selanjutnya — model ini sengaja dibuat kecil dan cepat, dengan versi yang lebih besar sudah dalam pengembangan.
Tekanan Kompetitif
Matematikanya sederhana. OpenAI dan Anthropic secara kolektif dinilai lebih dari $1 triliun. Gemini Google telah mendapatkan daya tarik di pasar konsumen dan developer. Meta menghabiskan $72 miliar untuk infrastruktur AI pada 2025, naik menjadi $115–135 miliar yang dipandu pada 2026, dan tidak memiliki model kompetitif di garis depan untuk ditunjukkan. Sesuatu harus berubah.
Kerangka Keputusan untuk Para Pembangun
Tetap Dengan Llama Jika:
Kamu membutuhkan bobot terbuka — untuk self-hosting, fine-tuning, kepatuhan on-premises, atau kontrol biaya. Kamu menjalankan alur kerja yang banyak menggunakan coding di mana Muse Spark memiliki kesenjangan yang diakui. Kamu membutuhkan infrastruktur yang dapat diprediksi dan dikelola sendiri yang tidak bergantung pada waitlist API privat. Kamu sudah berinvestasi dalam tooling khusus Llama (pipeline kuantisasi, adapter LoRA, evaluasi kustom).
Pantau Muse Spark Jika:
Kamu membangun dalam ekosistem produk Meta — apa pun yang terintegrasi dengan Instagram, WhatsApp, Facebook, atau Messenger. Kamu membutuhkan pemahaman multimodal yang kuat, terutama penalaran visual atau tugas-tugas terkait kesehatan. Kamu bersedia menunggu akses API publik dan dapat mengevaluasi setelah harga dan syarat tersedia.
Tidak Ada yang Mencakup:
Pembuatan gambar. Pembuatan video. Ini adalah kategori model yang terpisah. Muse Spark hanya menghasilkan teks, dan Llama 4 juga hanya menghasilkan teks. Jika kamu membutuhkan kemampuan generasi, kamu sedang melihat alat yang sepenuhnya berbeda.
FAQ

Bisakah saya masih menggunakan Llama 4 setelah Muse Spark diluncurkan?
Ya. Llama 4 Scout dan Maverick tetap tersedia di Hugging Face dan melalui mitra API Meta. Tidak ada yang dihentikan atau ditarik.
Apakah Meta akan merilis bobot Muse Spark?
Meta mengatakan “berharap untuk membuka source versi masa depan dari model.” Tidak ada timeline, tidak ada komitmen spesifik tentang Muse Spark itu sendiri, dan tidak ada indikasi apa arti “versi masa depan” dalam praktiknya. Perlakukan ini sebagai aspirasi, bukan rencana.
Apakah Muse Spark lebih baik dari Llama 4 untuk coding?
Tidak. Meta secara eksplisit mengakui coding sebagai kesenjangan saat ini. Pada benchmark khusus coding, Muse Spark tertinggal dari Claude Sonnet 4.6 dan GPT-5.4. Jika coding adalah kasus penggunaan utamamu, Llama 4 Maverick dengan fine-tuning atau model coding yang dirancang khusus adalah pilihan yang lebih baik saat ini.
Kapan model Muse berikutnya akan datang?
Meta menggambarkan Muse Spark sebagai “langkah pertama” dengan “model yang lebih besar sudah dalam pengembangan.” Tidak ada tanggal. Tidak ada nama. Tidak ada spesifikasi selain konfirmasi bahwa mereka ada.
Apakah ini memengaruhi ekosistem open-source AI yang lebih luas?
Ini adalah sinyal, bukan pukulan mematikan. Model Llama berbobot terbuka milik Meta tetap tersedia. Organisasi lain — Mistral, DeepSeek, Qwen milik Alibaba — terus merilis model terbuka. Namun Meta adalah pendukung korporat tunggal terbesar dari model bobot terbuka di garis terdepan. Jika investasi garis terdepan mereka beralih secara permanen ke model tertutup, ekosistem kehilangan kontributornya yang paling berdana besar. Itu penting selama bertahun-tahun, bukan minggu-minggu.
Sekian. Lebih lanjut akan datang ketika API dibuka untuk publik.
Postingan sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
