HappyHorse-1.0 vs Seedance 2.0: Mana yang Unggul Saat Ini?
HappyHorse-1.0 mengungguli Seedance 2.0 dalam T2V dan I2V tanpa audio — namun tertinggal dalam audio dan belum memiliki API yang stabil. Inilah artinya bagi para developer.

Saya menghabiskan banyak waktu menyegarkan papan peringkat Artificial Analysis Video Arena. Hei, ini Dora! Sebuah model yang belum pernah saya dengar — HappyHorse-1.0 — muncul diam-diam pada akhir pekan dan mendorong Seedance 2.0 keluar dari posisi teratas di dua dari empat peringkat utama. Tidak ada yang tampaknya tahu siapa yang membuatnya. Artificial Analysis sendiri menyebutnya sebagai entri “pseudonim”. Dan linimasa saya dipenuhi setengah kegembiraan, setengah kebingungan.
Jadi saya menarik angka-angkanya, melacak jalur aksesnya, dan mencoba mencari tahu satu-satunya pertanyaan yang benar-benar penting bagi siapa pun yang membangun dengan model-model ini sekarang: mana yang bisa kamu gunakan untuk produksi hari ini?
Jawabannya tidak sejelas yang ditampilkan papan peringkat.
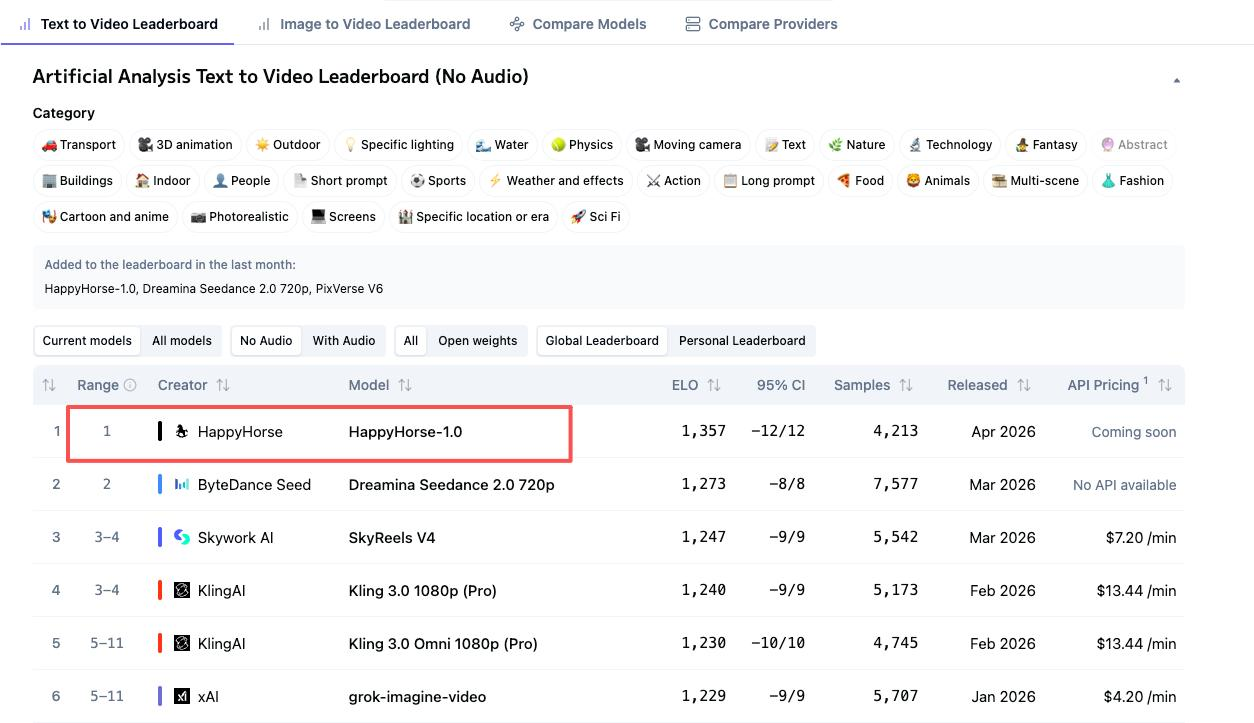
Empat Angka Papan Peringkat yang Penting
HappyHorse dan Seedance 2.0 berada di puncak empat peringkat Artificial Analysis yang terpisah. Namun posisi mereka bertukar tergantung pada apakah audio merupakan bagian dari evaluasi. Perbedaan itu lebih penting dari yang diakui sebagian besar perbandingan.
T2V Tanpa Audio: HappyHorse #1 (Elo 1333) vs Seedance 2.0 #2 (Elo 1273)
Ini adalah penampilan terkuat HappyHorse. Selisih Elo 60 poin dalam arena pemungutan suara buta sangat berarti — ini kira-kira berarti pengguna lebih memilih output HappyHorse sekitar 59% dari waktu dalam pertandingan head-to-head. Suara di sini menangkap kualitas gerak visual, kepatuhan prompt, dan koherensi adegan tanpa audio yang mempengaruhi persepsi.
T2V Dengan Audio: Seedance 2.0 #1 (Elo 1219) vs HappyHorse #2 (Elo 1205)
Begitu audio masuk, Seedance mengambil alih keunggulan dengan 14 poin. Dual-Branch Diffusion Transformer milik ByteDance menghasilkan video dan audio secara bersamaan dalam satu proses — satu cabang untuk frame video, satu untuk gelombang audio, dihubungkan oleh cross-attention. Pilihan arsitektur tersebut terbukti ketika efek suara dan dialog yang tersinkronisasi menjadi bagian dari penilaian.
I2V Tanpa Audio: HappyHorse #1 (Elo 1392) vs Seedance 2.0 #2 (Elo 1355)
Elo tertinggi HappyHorse di semua empat kategori. Keunggulan 37 poin pada image-to-video tanpa audio menunjukkan bahwa model ini sangat kuat dalam mengikuti komposisi gambar referensi — menjaga identitas subjek, framing, dan gaya visual tetap konsisten saat menghasilkan gerakan. Bagi tim yang mengerjakan animasi produk atau pekerjaan concept-to-motion, ini adalah angka yang penting.
I2V Dengan Audio: Seedance 2.0 #1 (Elo 1162) vs HappyHorse #2 (Elo 1161) — Hampir Seri
Satu poin. Itu masih dalam batas margin of error yang wajar. Tidak ada model yang memiliki keunggulan nyata di sini. Anggap kategori ini sebagai seri sampai lebih banyak suara terkumpul.
Apa yang Sebenarnya Diukur Elo — dan Batasannya untuk Keputusan Produksi
Skor Elo ini berasal dari suara pengguna buta dalam perbandingan berdampingan, menggunakan model Bradley-Terry yang diadaptasi dari peringkat catur. Pengguna melihat dua video yang dihasilkan secara anonim dari prompt yang sama dan memilih yang lebih mereka sukai. Ini adalah pendekatan terdekat yang kita miliki untuk “vibe check” dalam skala besar.
Namun Elo tidak mengukur keandalan API, kecepatan pembuatan, biaya per klip, stabilitas akses, atau apakah kamu benar-benar bisa memanggil model secara programatis. Peringkat papan peringkat adalah sinyal kualitas, bukan keputusan pengiriman.
Tabel Perbandingan Inti
| Dimensi | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| T2V Elo (tanpa audio) | 1333 (#1) | 1273 (#2) |
| T2V Elo (dengan audio) | 1205 (#2) | 1219 (#1) |
| I2V Elo (tanpa audio) | 1392 (#1) | 1355 (#2) |
| I2V Elo (dengan audio) | 1161 (#2) | 1162 (#1) |
| Pembuatan audio | Ada, tertinggal dari Seedance | Lebih kuat — sinkronisasi dual-branch native |
| Penyedia yang dikenal | Tidak — pseudonim | Ya — ByteDance |
| Arsitektur (diklaim) | Transformer 40-layer single-stream | Dual-Branch Diffusion Transformer |
| Bobot terbuka | Diklaim “segera hadir” | Tidak |
| API stabil | Tidak ada API publik yang tersedia | Akses konsumen melalui Dreamina; API resmi dijeda |
| Akses hari ini | Hanya situs demo | Dreamina, CapCut Pro, aplikasi China |
Di Mana HappyHorse Unggul
Kualitas gerak visual tanpa audio: apa yang ditangkap oleh suara buta
Selisih Elo pada peringkat tanpa audio — 60 poin pada T2V, 37 pada I2V — tidak bisa diabaikan. Pengguna dalam perbandingan buta secara konsisten memilih HappyHorse untuk apa yang digambarkan orang sebagai pergerakan kamera yang lebih natural, gerakan tubuh yang lebih halus, dan atmosfer adegan yang lebih kuat. Jika kasus penggunaan kamu adalah loop produk tanpa suara, klip sosial yang diedit dengan musik terpisah, atau B-roll yang dibunyikan dalam pasca-produksi, ini relevan.
Arsitektur Transformer single-stream (diklaim) vs pipeline multi-stream
Materi pemasaran HappyHorse menggambarkan Transformer self-attention 40-layer terpadu yang memproses token teks, video, dan audio dalam satu urutan — tanpa cross-attention antara cabang terpisah. Jika akurat, ini berbeda secara arsitektur dari pendekatan dual-branch Seedance. 4 lapisan pertama dan terakhir dilaporkan menggunakan proyeksi khusus modalitas sementara 32 lapisan tengah berbagi parameter di semua modalitas. Saya belum bisa memverifikasi klaim ini secara independen. GitHub dan model hub terdaftar sebagai “segera hadir”.
Klaim audio multibahasa
HappyHorse mengklaim dukungan native untuk tujuh bahasa — Inggris, Mandarin, Kanton, Jepang, Korea, Jerman, dan Prancis — dengan sinkronisasi bibir berkadar error kata yang rendah. Seedance 2.0 mendukung 8+ bahasa untuk sinkronisasi bibir tingkat fonem. Di atas kertas, mereka kompetitif. Dalam praktiknya, saya belum bisa menguji output multibahasa HappyHorse secara cukup untuk mengkonfirmasi kesetaraannya.
Di Mana Seedance 2.0 Mempertahankan Keunggulan
Pembuatan audio: masih memimpin di kedua papan peringkat dengan-audio
Seedance memegang posisi #1 pada T2V dan I2V dengan audio. Arsitektur dual-branch-nya — satu cabang menghasilkan frame video, yang lain menghasilkan gelombang audio, dihubungkan melalui cross-attention untuk sinkronisasi tingkat milidetik — dibangun secara khusus untuk ini. Ketika output kamu membutuhkan dialog, suara sekitar, atau foley yang akurat per frame, keputusan arsitektur Seedance untuk memperlakukan audio sebagai warga kelas pertama selama pembuatan (bukan langkah pasca-pemrosesan) memberikan keunggulan struktural.
Penyedia yang dikenal: ByteDance, identitas stabil, ekosistem yang mapan
Kamu tahu siapa yang membuat Seedance 2.0. Tim riset Seed ByteDance, dipimpin oleh Wu Yonghui (mantan Google Fellow, 17 tahun di Google termasuk Google Brain), memiliki silsilah terdokumentasi dari Pixeldance melalui Seedance 1.0, 1.5 Pro, dan sekarang 2.0. HappyHorse? Per tanggal publikasi, tidak ada yang secara publik mengkonfirmasi siapa yang membuatnya. Artificial Analysis menambahkannya sebagai entri pseudonim. Beberapa situs wrapper pihak ketiga muncul dalam beberapa jam setelah debut arena-nya, tetapi tidak ada yang mengklaim sebagai pengembang asli.
Untuk keputusan produksi, asal-usul itu penting. Kamu perlu tahu kepada siapa kamu bergantung untuk pembaruan model, kepatuhan, dan kesinambungan.
Jalur akses: Dreamina memiliki titik masuk publik
Seedance 2.0 dapat diakses hari ini melalui platform Dreamina milik ByteDance secara internasional, dengan paket berbayar mulai sekitar $18/bulan. Integrasi CapCut Pro diluncurkan di pasar pilihan pada akhir Maret 2026. Pengguna China dapat mengaksesnya melalui Jimeng dengan paket mulai sekitar 69 RMB/bulan (~$9,60 USD).
Meskipun demikian — API resmi Seedance 2.0 tetap dijeda sejak pertengahan Maret 2026 karena dilaporkan adanya sengketa hak cipta. Akses konsumen berfungsi. Akses API programatis pada skala produksi memerlukan verifikasi sebelum kamu berkomitmen membangun pipeline di sekitarnya. Penyedia pihak ketiga menawarkan Seedance v1.5 melalui API; ketersediaan API Seedance 2.0 melalui saluran resmi perlu konfirmasi pra-produksi.
Kesenjangan Akses Adalah Faktor Keputusan yang Sebenarnya
HappyHorse: tidak ada API stabil, tidak ada bobot publik, hanya demo per tanggal publikasi
Meski mengklaim rilis open-source, GitHub dan model hub HappyHorse keduanya terdaftar sebagai “segera hadir.” Beberapa situs demo dan wrapper ada, tetapi tidak ada yang menawarkan endpoint API terdokumentasi dengan SLA, batas laju, atau harga yang bisa kamu jadikan dasar produk. Saya tidak bisa menemukan satu pun penyedia API pihak ketiga yang saat ini melayani HappyHorse-1.0 melalui endpoint yang stabil dan terdokumentasi.
Jika kamu mengevaluasi untuk produksi, ini adalah faktor terbesar tunggal. Model yang tidak bisa kamu panggil secara andal bukanlah model yang bisa kamu kirimkan.
Seedance 2.0: dapat diakses melalui Dreamina — detail perlu verifikasi
Akses konsumen melalui Dreamina berfungsi. Platform ini mendukung rangkaian fitur lengkap termasuk sistem referensi @, pengeditan multi-shot, dan pembuatan audio-visual. Namun jika alur kerja kamu memerlukan integrasi tingkat API, lanskap yang ada kurang stabil. API BytePlus resmi untuk Seedance 2.0 telah dijeda sejak Maret. Penyedia pihak ketiga seperti fal.ai dan PiAPI telah menawarkan Seedance 1.5; akses programatis Seedance 2.0 dan struktur harganya harus dikonfirmasi langsung sebelum membangun ketergantungan produksi.
Mengapa “peringkat #1 di papan peringkat” dan “siap produksi” adalah pertanyaan yang berbeda
Saya terus kembali ke hal ini. Elo memberi tahu kamu model mana yang lebih disukai pengguna dalam perbandingan terkontrol. Itu tidak memberi tahu kamu apakah kamu bisa melewatkan 10.000 generasi melaluinya pada hari Selasa depan tanpa error 503. HappyHorse mungkin benar-benar menghasilkan video diam yang lebih baik. Tapi jika kamu tidak bisa memanggilnya secara andal, keunggulan kualitas itu hanya ada di arena, bukan di pipeline kamu.
Kerangka Keputusan
Kualitas audio tidak bisa dikompromikan → Seedance 2.0. Ini memimpin di kedua papan peringkat dengan-audio dan arsitektur dual-branch-nya menghasilkan suara tersinkronisasi secara native. Jika klip kamu membutuhkan dialog, audio sekitar, atau efek suara yang akurat per frame, Seedance adalah pilihan yang lebih kuat hari ini.
Fidelitas gerak visual adalah prioritas kamu dan kamu bersedia menunggu → Pantau HappyHorse. Keunggulan Elo tanpa audio adalah nyata. Jika bobot terbuka dan akses API terwujud seperti yang dijanjikan, HappyHorse bisa menjadi menarik untuk alur kerja yang mengutamakan tanpa suara. Namun “segera hadir” bukan SLA.
Kamu membutuhkan API produksi hari ini → Seedance 2.0 adalah pilihan yang lebih aman. Bukan karena sempurna — jeda API resmi adalah hambatan nyata — tetapi karena Dreamina menyediakan jalur akses yang berfungsi dengan harga terdokumentasi, dan penyedia pihak ketiga secara aktif mempersiapkan endpoint Seedance 2.0. HappyHorse belum memiliki infrastruktur yang setara.
FAQ
Apakah HappyHorse-1.0 benar-benar lebih baik dari Seedance 2.0?
Tergantung pada apa yang kamu ukur. HappyHorse memimpin dalam kualitas visual pada perbandingan tanpa audio (Elo 1333 vs 1273 untuk T2V, 1392 vs 1355 untuk I2V). Seedance memimpin ketika audio adalah bagian dari evaluasi. Tidak ada yang mendominasi semua empat kategori. “Lebih baik” hanya masuk akal relatif terhadap kasus penggunaan spesifik kamu dan apakah audio penting.
Mengapa HappyHorse unggul tanpa audio tetapi tertinggal dengan audio?
Kemungkinan karena arsitektur. HappyHorse mengklaim Transformer terpadu tunggal yang memproses semua modalitas dalam satu urutan. Seedance 2.0 menggunakan desain dual-branch yang dibangun khusus di mana cabang video dan audio terpisah dihubungkan oleh cross-attention. Cabang audio khusus tersebut tampaknya memberikan keunggulan Seedance ketika kualitas suara dan sinkronisasi dinilai bersama visual.
Bisakah saya mengakses HappyHorse-1.0 melalui API hari ini?
Tidak melalui endpoint yang stabil dan terdokumentasi yang bisa saya verifikasi per 8 April 2026. Beberapa situs wrapper menawarkan akses demo berbasis browser, tetapi tidak ada yang mempublikasikan dokumentasi API, batas laju, atau SLA kelas produksi. GitHub resmi dan model hub keduanya terdaftar sebagai “segera hadir.”
Seberapa andal papan peringkat Artificial Analysis untuk keputusan produksi?
Ini adalah sinyal crowdsourced paling kredibel untuk kualitas video yang dirasakan — suara buta, peringkat berbasis Elo, preferensi manusia nyata. Namun ini mengukur satu hal: output mana yang lebih disukai pengguna secara berdampingan. Ini tidak memperhitungkan kecepatan pembuatan, biaya, keandalan, uptime API, atau stabilitas akses. Gunakan sebagai input kualitas, bukan sebagai keputusan pengadaan yang lengkap.
Apakah HappyHorse-1.0 akan mendapatkan peningkatan audio di versi mendatang?
Tidak ada roadmap publik yang ada. Model ini muncul di arena kurang dari seminggu yang lalu dengan nama samaran. Jika rilis open-source “segera hadir” terjadi, kontribusi komunitas bisa meningkatkan kualitas audio. Tapi tidak ada jadwal, tidak ada tim pengembang yang dikonfirmasi, dan tidak ada rencana v2 yang diumumkan. Apa pun di luar yang saat ini ada di papan peringkat hanyalah spekulasi.
Ada sesuatu yang menarik terjadi dalam kesenjangan antara apa yang dikatakan papan peringkat dan apa yang sebenarnya bisa digunakan oleh pembangun. Angka-angka HappyHorse benar-benar mengesankan — tetapi angka tanpa akses hanyalah angka. Saya akan terus memantau repositori GitHub tersebut untuk aktif. Sampai saat itu, perbandingan ini sebenarnya bukan tentang model mana yang lebih baik. Ini tentang model mana yang tersedia.
Coba HappyHorse-1.0 di WaveSpeedAI
HappyHorse-1.0 kini tersedia di WaveSpeedAI:
Postingan sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
