Performa Coding Claude Mythos: Apa Artinya bagi Alur Kerja Pengembangan AI
Claude Mythos dilaporkan mendapatkan skor jauh lebih tinggi dalam coding dibanding Opus 4.6. Ini artinya bagi para pengembang yang membangun agen coding AI di tahun 2026.

Semua orang terfokus pada kekhawatiran keamanan siber ketika Fortune merilis judul berita tebal yang langsung ke inti: Anthropic secara tidak sengaja membiarkan hampir 3.000 file internal terekspos, termasuk draf posting blog yang mempromosikan model mereka yang belum dirilis. Tapi sebagai seseorang yang setiap hari membangun dengan Claude, yang menarik perhatian saya bukan kebocoran itu sendiri — melainkan klaim-klaim diam-diam namun mengejutkan yang terpendam dalam draf tersebut tentang performa coding.
Tersedia di WaveSpeedAI — harga per-token transparan, endpoint kompatibel OpenAI. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Buka Playground →
Dalam tulisan ini, kalian dan saya, Dora, tidak akan mengejar hype atau kepanikan keamanan, melainkan langsung ke inti hal yang benar-benar penting bagi para developer dan tim yang merilis produk nyata — dengan memaparkan secara tepat apa yang kita ketahui (dan apa yang tidak kita ketahui) tentang kemampuan coding Claude Mythos / Capybara.
Apa yang Dikatakan Draf yang Bocor tentang Performa Coding Claude Mythos
Klaim tepat dari draf yang bocor: “Dibandingkan dengan model terbaik kami sebelumnya, Claude Opus 4.6, Capybara mendapatkan skor yang jauh lebih tinggi pada pengujian coding perangkat lunak, penalaran akademik, dan keamanan siber, di antara lainnya.”
Itulah keseluruhan yang Anthropic tulis tentang performa coding. Tidak ada persentase SWE-bench, tidak ada skor Terminal-Bench, tidak ada tabel perbandingan. Frasa “jauh lebih tinggi” adalah sinyal nyata — samar, tapi tidak tanpa makna.

Sebagai konteks, Opus 4.6 saat ini memimpin model yang tersedia secara publik pada SWE-bench Verified (~80,8%), Terminal-Bench 2.0, dan Humanity’s Last Exam. Juru bicara resmi Anthropic mengonfirmasi bahwa model ini mewakili “kemajuan bermakna dalam penalaran, coding, dan keamanan siber.” Pelatihan telah selesai, pengujian akses awal sedang berjalan, dan coding secara eksplisit adalah salah satu dari tiga dimensi kemampuan utama. Selebihnya adalah inferensi.
Mengapa Coding Adalah Kemampuan Terpenting untuk Tingkat Model Ini
Konteks Terminal-Bench 2.0 dan Skor Opus 4.6 Saat Ini
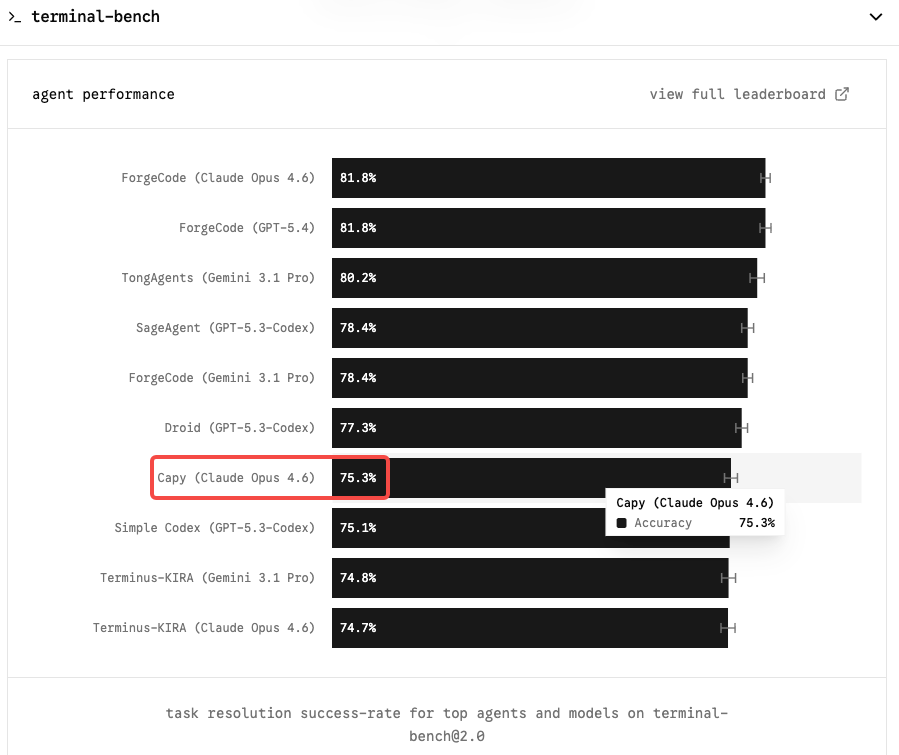
Terminal-Bench 2.0 adalah benchmark yang paling penting untuk alur kerja coding agentik. Tidak seperti SWE-bench yang menguji penyelesaian issue GitHub secara terisolasi, Terminal-Bench mengevaluasi tugas nyata dalam lingkungan terminal yang disandbox — administrasi sistem, DevOps, alur kerja CLI multi-langkah. Ini lebih sulit, lebih mewakili penggunaan produksi, dan kurang rentan terhadap inflasi yang didorong oleh scaffold.
Claude Opus 4.6 memegang posisi teratas dengan 65,4% pada Terminal-Bench 2.0 dan 72,7% pada OSWorld. Model tingkat Capybara yang menggerakkan angka tersebut ke kisaran 75–85% akan menjadi perubahan nyata bagi tim mana pun yang menjalankan agen coding otonom.
Pada SWE-bench Verified, gambarannya lebih padat: enam model kini mendapat skor dalam jarak 0,8 poin satu sama lain. Opus 4.6 berada di 80,8%; Gemini 3.1 Pro memberikan 80,6% dengan harga $2/$12 per juta token. SWE-bench mentah tidak lagi menjadi pembeda yang bermakna. Terminal-Bench dan koherensi konteks panjang adalah tempat Opus 4.6 mendapatkan premiumnya — dan di situlah Mythos kemungkinan akan membuat kasusnya paling jelas.
Apa Arti Struktural “Jauh Lebih Tinggi”
Dalam draf tersebut, “jauh lebih tinggi” muncul bersamaan dengan “perubahan langkah” — frasa yang sama yang digunakan juru bicara Anthropic secara publik. Tidak ada istilah yang kasual. Lompatan dari Opus 4.1 ke Opus 4.6 adalah peningkatan generasional dalam tingkat yang sama. “Perubahan langkah” mengimplikasikan sesuatu yang berbeda secara jenis — lebih seperti kesenjangan antara Sonnet dan Opus daripada antara dua versi Opus berturut-turut.
Model yang secara bermakna mengungguli Opus 4.6 dalam coding akan menjadi alat signifikan untuk pengembangan perangkat lunak, debugging, dan alur kerja agentik. Pertanyaan terbuka adalah kapan tersedia dan dengan biaya berapa. Itulah kerangka yang jujur. Klaim performa ini kredibel mengingat rekam jejak Anthropic baru-baru ini. Validasinya saja yang belum ada.
Implikasi untuk Alur Kerja Coding Agentik
Tugas Kode Konteks Panjang
Implikasi praktis paling langsung dari model tingkat Capybara untuk tim coding bukanlah skor benchmark mentah — melainkan apa yang dilakukan penalaran yang lebih baik dalam skala besar.
Jendela konteks 1 juta token Claude Code kini sudah GA untuk Opus 4.6, menyediakan ~830 ribu token yang dapat digunakan setelah kompaksi — cukup untuk seluruh monorepo dan set dokumentasi lengkap. Model yang secara dramatis mengungguli Opus 4.6 dalam coding, diterapkan pada jendela yang sama, berarti pemahaman arsitektur yang lebih baik di seluruh codebase besar dan lebih sedikit kesalahan penalaran dalam refaktor multi-file. Jendela konteksnya tidak berubah. Kualitas penalaran di dalamnya yang akan meningkat.
Untuk tim yang melakukan analisis codebase besar saat ini — jenis pekerjaan di mana Anda memuat 50 ribu+ baris sumber dan meminta model memahami gambaran lengkap — ini adalah jalur upgrade praktis yang paling penting.
Agen Debugging Multi-Langkah
Anthropic merilis Agent Teams sebagai fitur eksperimental bersama rilis Opus 4.6, menandai langkah signifikan dalam alur kerja agentik. Satu sesi bertindak sebagai ketua tim — mengkoordinasikan pekerjaan, menugaskan tugas, dan mensintesis hasil. Anggota tim bekerja secara independen, masing-masing dalam jendela konteksnya sendiri, dan berkomunikasi langsung satu sama lain.
Agen debugging multi-langkah adalah tempat nilai gabungan dari model dasar yang lebih baik menjadi paling jelas. Dalam pengaturan multi-agen, kualitas perencanaan ketua tim menentukan seberapa baik seluruh operasi berjalan. Model yang lebih kuat membuat keputusan dekomposisi tugas yang lebih baik, menulis spesifikasi tugas yang lebih jelas untuk subagen, dan mendeteksi kesalahan integrasi lebih awal.
Draf yang bocor secara khusus menyebutkan coding perangkat lunak bersama keamanan siber sebagai domain di mana Capybara “secara dramatis” mengungguli Opus 4.6. Jika kesenjangan itu nyata dan substansial pada tugas bergaya Terminal-Bench, hal itu akan langsung diterjemahkan menjadi agen debugging multi-langkah yang lebih andal yang membutuhkan lebih sedikit intervensi manusia untuk pulih dari asumsi yang salah.
Eksplorasi Codebase yang Diarahkan Sendiri
Ini adalah kasus penggunaan yang paling membuat saya penasaran dalam praktiknya. Claude Code menelusuri masalah melalui codebase Anda, mengidentifikasi akar penyebab, dan mengimplementasikan perbaikan. Kualitas penelusuran itu adalah fungsi dari kedalaman penalaran, bukan hanya ukuran jendela konteks.
Dalam alur kerja tipikal 2026, seorang developer mungkin menyajikan persyaratan tingkat tinggi dan agen utama akan mendekomposisi ini menjadi tugas-tugas berbeda, dengan anggota tim menggunakan Model Context Protocol untuk mengakses alat eksternal, menjalankan pengujian, dan melakukan audit keamanan secara bersamaan. Model tingkat Capybara yang berjalan sebagai orkestrator dalam pengaturan semacam itu akan membuat seluruh alur kerja lebih otonom — artinya lebih sedikit permintaan klarifikasi, dekomposisi tugas awal yang lebih baik, dan koreksi diri yang lebih andal ketika subagen menghadapi kondisi yang tidak terduga.
Apa yang Harus Dilakukan Builder Sekarang Selama Mythos Belum Tersedia
Cara Melakukan Benchmark Opus 4.6 untuk Kasus Penggunaan Anda Saat Ini
Hal paling berguna yang bisa Anda lakukan sekarang adalah menjalankan evaluasi Anda sendiri pada Opus 4.6 — bukan terhadap benchmark, tetapi terhadap beban kerja Anda yang sebenarnya. Benchmark generik seperti SWE-bench menguji penyelesaian issue terisolasi dengan scaffolding yang distandarisasi. Agen coding produksi Anda memiliki struktur codebase yang spesifik, serangkaian tugas yang spesifik, dan mode kegagalan yang spesifik. Itulah yang penting.
Evaluasi dasar praktis untuk agen coding mungkin terlihat seperti ini:
# Pelacakan tingkat keberhasilan tugas sederhana
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Jalankan 20-30 tugas representatif yang sama melalui Opus 4.6
# Lacak: apakah berhasil pada percobaan pertama? Berapa banyak giliran?
# Berapa fraksi jendela konteks 1 juta yang dikonsumsi?
# Di mana gagal — kesalahan penalaran, penggunaan alat, atau luapan konteks?Alasan ini penting: ketika Mythos tersedia, Anda akan memiliki baseline nyata untuk mengevaluasi apakah peningkatan kemampuan membenarkan premium biaya untuk alur kerja spesifik Anda. “Jauh lebih tinggi” pada suite pengujian internal Anthropic mungkin atau mungkin tidak diterjemahkan menjadi perbedaan bermakna dalam struktur codebase dan distribusi tugas Anda yang spesifik.
‘Model terbaik’ adalah yang cocok dengan cara Anda berkomunikasi dengannya. Model tingkat menengah dalam harness yang bagus mengalahkan model frontier dalam harness yang buruk. Kualitas harness Anda — rekayasa prompt, konfigurasi alat, struktur CLAUDE.md — adalah variabel yang bisa Anda tingkatkan sekarang. Mythos tidak akan memperbaiki arsitektur agen yang dirancang buruk.
Keputusan Arsitektur yang Akan Skalabel dengan Model yang Lebih Mampu
Kabar baiknya adalah arsitektur agentik yang dirancang dengan baik bersifat model-agnostik di lapisan routing. Pola yang layak dibangun sekarang:
Pisahkan orkestrasi dari eksekusi. Agen orkestrator yang mendekomposisi tugas, menugaskan file, dan meninjau output — didukung oleh subagen khusus untuk implementasi — dapat menukar model dasarnya dengan satu perubahan parameter. Bangun pemisahan ini sekarang dan upgrade Mythos menjadi pembaruan konfigurasi, bukan refaktor arsitektur.
Gunakan CLAUDE.md sebagai konteks runtime, bukan prompting khusus sesi. File CLAUDE.md berfungsi sebagai “konstitusi” untuk agen AI dalam repositori — menyediakan konteks yang diperlukan tentang arsitektur proyek, standar coding, dan perintah build yang memungkinkan agen beroperasi tanpa manajemen mikro manusia. CLAUDE.md yang terstruktur dengan baik mengurangi biaya eksplorasi per tugas pada Opus 4.6 hari ini dan akan memperkuat keuntungan dari model yang lebih kuat besok.
Rancang untuk jendela konteks 1 juta, bukan melawannya. Tim yang telah merestrukturisasi strategi pemuatan file, logika chunking, dan manajemen konteks mereka untuk bekerja dalam jendela 1 juta token akan diposisikan untuk memanfaatkan sepenuhnya kemampuan penalaran Mythos di seluruh jendela yang sama. Jangan bangun solusi sementara untuk batas konteks yang mengasumsikan batas atas tidak akan meningkat.
Apa yang Perlu Diperhatikan saat Peluncuran untuk Tim yang Berfokus pada Coding
Sinyal yang paling penting bagi developer berbeda dari sinyal enterprise umum. Khusus untuk tim yang berfokus pada coding:
Skor SWE-bench dan Terminal-Bench saat peluncuran. Anthropic secara historis menerbitkan ini bersamaan dengan rilis model. Jika Mythos memenuhi klaim “jauh lebih tinggi”, Anda akan mengharapkan skor Terminal-Bench 2.0 bergerak secara bermakna di atas 65,4% Opus 4.6. Lompatan ke 75%+ akan memvalidasi klaim untuk alur kerja agentik.
Pembaruan string model Claude Code. Periksa dokumen Claude Code dan ikhtisar model API untuk alias model baru. Claude Code secara historis memperbarui model defaultnya dalam beberapa hari setelah rilis flagship baru. Jika Mythos dikirim ke API publik, di sinilah pertama kali akan muncul untuk tim coding.
Pengumuman kompatibilitas Agent Teams. Agent Teams dikirim sebagai eksperimental bersama Opus 4.6. Apakah Mythos terintegrasi secara native dengan Agent Teams saat peluncuran — atau memerlukan konfigurasi terpisah — akan menentukan seberapa cepat tim dapat memindahkannya ke alur kerja multi-agen.
Changelog Anthropic dan dokumentasi harga. Dua halaman ini adalah sinyal yang paling awal dan dapat diandalkan sebelum pengumuman pers apa pun. String model baru dan baris harga baru akan muncul di sini terlebih dahulu.
FAQ
Apakah Claude Mythos tersedia untuk tugas coding sekarang?
Tidak. Hingga awal April 2026, tidak ada endpoint API publik untuk Claude Mythos atau tingkat Capybara. Claude Mythos / Capybara hanya tersedia untuk sekelompok kecil pelanggan akses awal yang dipilih oleh Anthropic, tanpa API publik, tanpa harga yang diumumkan, dan tanpa tanggal rilis yang dikonfirmasi. Claude Opus 4.6 — 80,8% pada SWE-bench Verified, 65,4% pada Terminal-Bench 2.0 — tetap menjadi pilihan terbaik yang tersedia secara publik.
Apakah Claude Mythos akan bekerja dengan Claude Code?
Hampir pasti ya, pada akhirnya. Arsitektur Claude Code bersifat model-agnostik; beralih ke flagship baru adalah perubahan parameter tunggal. Tapi ini tidak dikonfirmasi untuk Mythos saat peluncuran.
Haruskah saya menunggu Mythos untuk membangun alat coding AI saya?
Tidak. Anthropic telah menyatakan perlu menjadi “jauh lebih efisien sebelum rilis umum apa pun.” Membangun di atas Opus 4.6 sekarang berarti arsitektur Anda tervalidasi produksi ketika Mythos tiba. Upgrade akan berupa penggantian string model. Tim yang menunggu akan tertinggal.
Posting Sebelumnya:
Artikel Terkait
Memperkenalkan ByteDance Seedance 2.0 Mini di WaveSpeedAI

Penjelasan Fallback Claude Fable 5 ke Opus 4.8

API GLM-5.2: Harga, Konteks 1M, dan Perutean Produksi

Harga GPT-5.4 Mini: Biaya Input, Cache & Output

API MAI-Image-2.5: Yang Perlu Diketahui Para Developer
