GPT-5.4 untuk Developer: Apa Arti Sinyal Bocoran bagi Alur Kerja AI
Mode cepat, peningkatan visi, dan sinyal agen pengkodean — inilah arti bocoran GPT-5.4 bagi para pembangun infrastruktur AI.

Hai, saya Dora. Saya tidak berencana untuk memantau GPT‑5.4. Saya hanya terus-menerus menemukan hambatan kecil dalam alur kerja agen saya, jeda yang cukup lama untuk membuat saya berpindah ke email, lalu lupa apa yang sedang saya kerjakan. Ketika sebuah model menjanjikan “Fast Mode” dan visi resolusi penuh, telinga saya langsung waspada, bukan karena saya ingin hal yang terbaru, melainkan karena saya ingin lebih sedikit gangguan kecil itu.
Tulisan ini ditujukan untuk para pengembang gpt 5.4, atau lebih tepatnya, para pengembang yang sedang memutuskan apakah dan bagaimana cara membangun di sekitarnya. Saya tidak di sini untuk menjual model ini. Saya di sini untuk berbagi di mana model ini mungkin mengurangi hambatan, di mana kemungkinan besar tidak, dan apa yang harus dibangun agar pekerjaan hari ini tetap bertahan dari catatan rilis esok hari.
Mengapa Para Pengembang Memperhatikan GPT-5.4 dengan Seksama
Pergeseran menuju model-as-infrastructure
Saya memperhatikan pergeseran yang lambat namun nyata: model kini lebih mirip “utilitas” yang Anda gunakan untuk merutekan tugas, bukan lagi “produk”. Setahun lalu, saya memperlakukan setiap model seperti sebuah kepribadian. Sekarang saya memperlakukan mereka seperti jalur di jalan raya: jalur akurasi tinggi, cepat, dan murah, dan saya mencoba berpindah di antara mereka dengan lancar.
Jika GPT‑5.4 menstabilkan pola jalur ganda (cepat/lambat atau cepat/berpikir), hal itu mendorong kita untuk merancang agen berdasarkan perutean, bukan taruhan tunggal. Itu terdengar abstrak sampai Anda men-debug tugas dengan 12 langkah dan menyadari langkah ke-3 hanya butuh klasifikasi cepat, tetapi langkah ke-8 butuh chain-of-thought yang cermat. Saya telah menyatukan logika itu secara manual di sistem saat ini. Rapuh. Jika infrastruktur sudah mengintegrasikannya, kita mendapatkan lebih sedikit titik rawan kesalahan.
Saya tidak terkesan oleh versi: yang saya pedulikan adalah apakah sebuah rilis memungkinkan saya mengurangi langkah atau menghapus kode perekat. GPT‑5.4, jika memang menuju ke arah yang diisyaratkan, bisa menjadi salah satunya.
Mengapa rilis inkremental itu penting
Kenaikan versi kecil terlihat membosankan, tetapi menghemat tim dari pembangunan ulang. Ketika model mempertahankan antarmuka yang stabil sambil meningkatkan latensi atau ketepatan visi, saya tidak perlu melatih ulang pengguna (atau diri saya sendiri). Nilainya muncul di tempat-tempat seperti: lebih sedikit percobaan ulang, prompt yang lebih ringkas, timeout yang lebih pendek.
Saya terus memantau dokumen OpenAI API dan halaman model untuk perubahan bentuk, bukan slogan. Jika GPT‑5.4 cocok di endpoint yang sudah ada dengan default yang lebih masuk akal dan perilaku sistem yang lebih jelas, itu adalah kemenangan. Lebih sedikit pergantian kode, log yang lebih dapat diprediksi. Dan bagi siapa pun yang memelihara agen dalam produksi, prediktabilitas mengalahkan kebaruan setiap hari.

Fast Mode — Apa yang Berubah untuk Alur Kerja Agen
Biaya penalaran saat ini dalam agen multi-langkah
Dalam pengujian saya selama sebulan terakhir dengan model generasi saat ini, agen multi-langkah tipikal (rencanakan → ambil → panggil alat → rangkum) membutuhkan 8–15 panggilan model. Setiap panggilan memiliki dua biaya: token dan perhatian. Token bisa dianggarkan. Perhatian adalah yang menguras Anda, jeda kecil, percobaan ulang parsial, momen saat Anda bertanya-tanya apakah prosesnya macet.
Bagi saya, tugas resolusi alat internal yang umum rata-rata memakan 20–45 detik dari ujung ke ujung. Sebagian besar bukan penalaran berat: melainkan pemeriksaan ringan dan pemformatan. Jika Fast Mode GPT‑5.4 memangkas latensi pada langkah-langkah ringan ini sambil menjaga akurasi tetap cukup baik, hal itu mengubah bentuk keseluruhan proses. Ekor panjang dari jeda-jeda kecil terpangkas. Itu tidak terlihat dramatis di atas kertas, tetapi terasa lebih baik dalam pekerjaan sehari-hari.
Inferensi dual-mode dan logika perutean
Yang saya pantau adalah apakah “Fast Mode” hanyalah model yang lebih kecil, atau benar-benar model yang dipasangkan dengan pemikir di dalam satu batasan. Jika API mengekspos petunjuk yang bersih, misalnya parameter atau aturan perutean di tingkat alat, saya bisa memusatkan keputusan: cepat untuk klasifikasi, penuh untuk sintesis. Tidak ada lagi percabangan khusus di setiap langkah agen.
Dalam pengujian dengan model saat ini, saya telah membuat prototipe perilaku dual-route dengan memeriksa niat dan kepercayaan diri langkah. Ini agak kikuk tapi berhasil: rute cepat untuk pola yang sudah dikenal, rute mendalam ketika ketidakpastian tinggi. GPT-5.4 kemungkinan akan melakukan hal yang sama jika API tidak melakukan auto-route. Jika melakukan auto-route, tugas bergeser ke penulisan guardrail yang masuk akal dan logging, sehingga Anda bisa melihat kapan model terlalu banyak menggunakan jalur lambat.
Bagaimanapun, logika adalah inti persoalannya. Fitur bernama “Fast” tidak membantu jika Anda tidak bisa tahu kapan fitur itu digunakan. Saya akan memilih parameter yang jelas dan trace yang baik daripada keajaiban yang tak terlihat.
Implikasi loop pemanggilan alat
Inilah yang penting dalam keseharian: loop alat. Ketika agen memanggil kalkulator, database, atau browser tiga kali berturut-turut, overhead menumpuk. Jika Fast Mode mengurangi biaya round-trip untuk penguraian niat dan pembangunan argumen fungsi, Anda memperkecil loop tersebut. Hal itu membebaskan anggaran untuk langkah-langkah yang benar-benar membutuhkan penalaran.
Tapi ada tangkapannya: jika jalur cepat salah merutekan bahkan 5–10% panggilan, Anda membayarnya kembali dalam bentuk percobaan ulang dan guardrail. Aturan praktis saya sederhana: ukur total loop yang diselesaikan per menit, bukan latensi per panggilan. Jika angka itu naik dengan Fast Mode aktif, pertahankan. Jika turun (lebih banyak percobaan ulang, lebih banyak koreksi), matikan untuk alur itu. Ini bukan soal kecepatan, melainkan soal throughput yang dapat diandalkan.
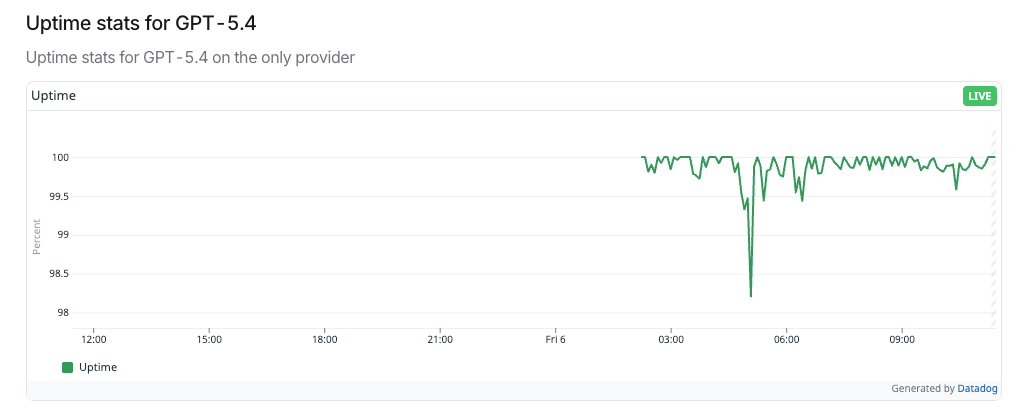
Visi Resolusi Penuh — Kasus Penggunaan di Dunia Nyata
Pipeline screenshot-to-code
Saya menjalankan pipeline screenshot-to-component kecil untuk alat internal. Saat ini, visi resolusi rendah melewatkan spasi kecil atau petunjuk status (hover vs. aktif). Visi resolusi penuh, jika nyata dan dapat diakses dengan biaya token yang wajar, mengubah ini. Model dapat melihat border 1 piksel dan bayangan halus yang menandakan elevasi.
Dalam praktiknya, saya akan mengkabelnya seperti ini: jalur resolusi tinggi untuk memberi label elemen UI atomik, kemudian jalur cepat hanya teks untuk merakit kode menggunakan peta library. Dua jalur, masing-masing unggul di bidangnya. Hasilnya bukan keajaiban “desain ke kode”, melainkan lebih sedikit koreksi manual. Pada dashboard sederhana, itu mungkin menghemat 10–15 menit dan beberapa kali bolak-balik ke Figma.
Alur kerja debugging UI
Kasus yang tidak terlalu mencolok namun berguna: reproduksi bug. Saya sering mendapatkan screenshot dengan toast error yang terpotong setengah atau overlay modal. Visi resolusi tinggi membantu model menalar z-index dan penumpukan tata letak tanpa saya harus menjelaskannya dengan kata-kata. Model dapat mencatat: tombol tutup toast tumpang tindih dengan navigasi: kemungkinan masalah penumpukan CSS. Saya tetap memverifikasi, tetapi memulai lebih dekat ke solusi adalah kelegaan.
Untuk tim, ini bisa masuk ke dalam triage: tempel screenshot, dapatkan daftar kemungkinan penyebab, plus selektor untuk diperiksa. Tidak ada yang ajaib, hanya loop yang lebih ketat.
Interpretasi aset desain
Desainer menyerahkan ekspor kepada saya dengan konvensi penamaan yang menyimpang akibat tekanan tenggat waktu, itu terjadi. Visi resolusi penuh plus konteks tentang sistem desain dapat memulihkan keteraturan. Model dapat memetakan token visual (spasi, radius, kontras warna) ke variabel sistem desain yang paling dekat.
Batasan tetap berlaku. Model tidak akan mengetahui selera tim Anda. Tetapi model dapat melakukan bagian yang membosankan: “12 ikon ini berukuran 20px, 3 ini berukuran 16px: kemungkinan ketidaksesuaian.” Itu tidak layak jadi berita utama, tetapi itulah jenis kebenaran kecil yang terakumulasi selama satu sprint.
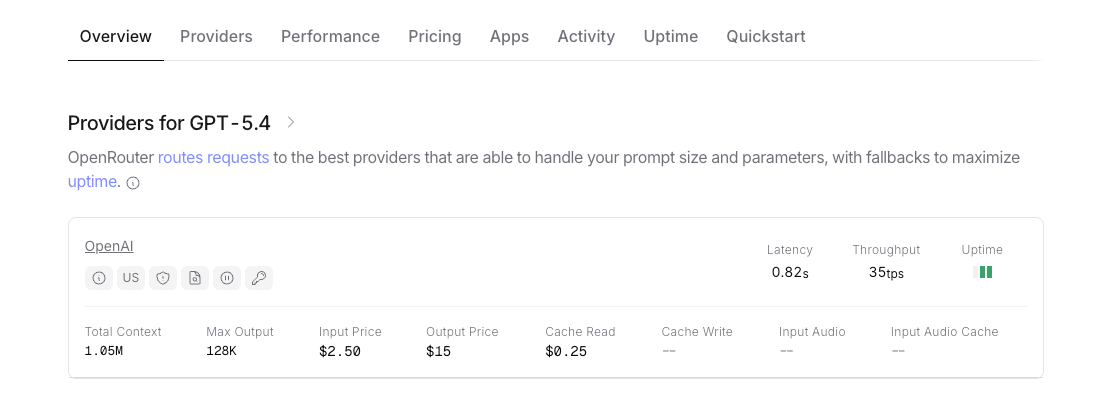
Sinyal Agen Coding dalam Konteks
Mengapa kebocoran muncul di repo Codex
Anda mungkin pernah melihat petunjuk, commit yang merujuk sinyal agen, atau konfigurasi dengan flag perutean yang tidak dapat dijelaskan. Saya tidak membaca terlalu banyak dari kebocoran, tetapi itu selaras dengan apa yang dibutuhkan pengembang: sinyal yang lebih jelas tentang kapan model sedang merencanakan, bertindak, atau merefleksi. Repo era Codex sebelumnya sering memalsukan ini dengan heuristik di sisi klien. Itulah mengapa konfigurasi bocor: logika harus hidup di luar model.
Jika GPT‑5.4 mengekspos sinyal status yang lebih tegas (bahkan yang sederhana seperti “perencanaan” vs “eksekusi”), para programmer dapat menyinkronkan UI dan logging tanpa mengurai nuansa dari teks.
Potensi pengeditan multi-file
Pengeditan multi-file adalah tempat agen coding mengalami kegagalan. Saat ini, saya membagi konteks, meminta rencana, kemudian menerapkan diff dengan linter dalam loop. Ini berhasil sampai tidak berhasil, biasanya ketika agen lupa file kecil atau mengganti nama sesuatu di tengah proses. Dukungan native yang lebih baik akan terlihat seperti: ajukan commit dengan peta file, sertakan alasan per file, dan biarkan saya menerima perubahan per file.
Bahkan tanpa primitif baru, penalaran yang ditingkatkan dari GPT‑5.4 (jika berhasil) ditambah pesan yang lebih ketat, “tunjukkan saya set patch, bukan prosa”, bisa mengurangi jebakan. Saya sudah punya beberapa keberhasilan dengan memaksa format patch dan menolak hal lainnya. Membosankan. Tapi membantu.
Peningkatan navigasi repo
Jendela konteks menjadi lebih besar, tetapi navigasi tetap penting. Pengujian coding terbaik yang saya lakukan di 2026 menggunakan pengindeks cepat yang membangun peta simbol dan grafik dependensi, kemudian hanya menyuplai irisan yang relevan. Jika GPT‑5.4 lebih baik dalam membaca peta ini, tabel cross-ref, ringkasan simbol, kita bisa menyampaikan konteks yang lebih tipis dan tajam.
Satu sinyal praktis untuk dipantau: seberapa sering agen meminta file yang sudah pernah dilihatnya. Lebih sedikit pengulangan biasanya berarti model membangun working set yang lebih baik. Saya mencatat itu. Jika Anda belum, mulailah sekarang: itu metrik yang mudah untuk dipantau tren lintas rilis.
Apa yang Harus Dibangun Pengembang Sekarang
Pola arsitektur model-agnostik
Saya berusaha menjaga model di balik port yang sempit. Broker memutuskan perutean: alat tetap stateless dan terlihat dalam log: prompt disimpan dalam file berversi dengan pengujian. Dengan begitu, jika GPT‑5.4 membuat Fast Mode layak digunakan, saya bisa berpindah jalur tanpa mengkabel ulang semuanya.
Dua pola yang bertahan lama bagi saya:
- Skema alat bertipe dengan validator ketat. Lebih sedikit tebak-tebakan, lebih sedikit panggilan yang buruk.
- Desain trace-first. Setiap langkah agen menulis trace ringkas yang bisa saya putar ulang. Ketika pembaruan model mengubah perilaku, saya bisa membandingkan jalannya lama vs. baru.
Keduanya tidak glamor. Keduanya adalah yang mencegah pengiriman terhenti saat model berubah.
Memantau saluran rilis model
Bahkan jika Anda tidak bergerak cepat, pantau salurannya. Saya berlangganan halaman model dan memindai daftar model dan catatan rilis. Saya menandai tiga hal per pembaruan: petunjuk latensi, harga token, dan switch tingkat sistem baru apa pun (mode, perutean, perilaku keamanan). Kemudian saya menjalankan kembali set benchmark kecil, 10–20 trace yang mewakili alur kerja nyata saya.
Butuh satu jam. Menghemat berhari-hari kemudian. Jika GPT‑5.4 diluncurkan secara bertahap (biasanya begitu), Anda akan melihat kasus tepi terlebih dahulu dalam trace, bukan di tiket dukungan. Itulah gunanya pemantauan: menangkap pergeseran dengan tenang, sebelum menjadi kebakaran.

Penafian Status
Saya tidak disponsori untuk menulis ini. Saya juga belum membuat taruhan produksi pada GPT‑5.4. Catatan saya di sini berasal dari eksperimen yang berdekatan dan pola yang bertahan dari pembaruan model sebelumnya. Jika dan ketika dokumen resmi mengklarifikasi mode atau detail visi, saya akan menautkannya dan menyesuaikan. Sampai saat itu, perlakukan ini sebagai catatan lapangan, semoga berguna, tetapi bersifat sementara.
Satu hal terakhir yang masih saya renungkan: jika Fast Mode membuat bagian-bagian yang tenang menjadi lebih cepat, apakah kita akan kurang menyadarinya, atau hanya kurang mengkhawatirkannya? Saya baik-baik saja dengan keduanya.
Artikel Terkait

Claude Fable 5 Telah Dirilis: 80,3% di SWE-Bench Pro, Harga 2× Opus 4.8, Gratis Hingga 22 Juni

Cara Memilih API Media AI untuk Aplikasi Codex (2026)

Hunyuan 3D API: Yang Perlu Diketahui para Developer

Hunyuan 3D vs Hyper3D vs Pixal3D

Membangun Aplikasi Video AI dengan Coding Agent
