Pourquoi HappyHorse-1.0 est-il soudainement #1 du classement vidéo ?
HappyHorse-1.0 a atteint la première place sur Artificial Analysis sans équipe publique. Voici pourquoi l'Elo récompense la qualité vidéo plutôt que la marque — et ce que cela signifie pour les développeurs.

Hey, les amis. C’est Dora. J’ai compté le nombre de fois où quelqu’un dans mon fil cette semaine a posé une version de la question « c’est quoi ce HappyHorse, bordel ? ». Six. Six fils distincts. Et chacun avait une rumeur légèrement différente associée — c’est WAN 2.7, c’est un lancement furtif de ByteDance, c’est quelque chose sorti d’Alibaba. Personne ne sait avec certitude. Ce sur quoi tout le monde s’accorde : il est apparu sur le classement vidéo d’Artificial Analysis vers le 7–8 avril 2026, et a immédiatement pris la 1ère place en Text-to-Video et Image-to-Video.
C’est le fait. Tout ce qui suit — qui l’a construit, quand les poids seront disponibles, s’il restera en tête — reste non résolu.
Cet article porte sur ce que le classement mesure réellement, pourquoi un modèle inconnu peut légitimement se retrouver en tête, et ce que vous devriez et ne devriez pas faire de cette information en tant que développeur.
Comment fonctionne la Video Arena d’Artificial Analysis
Avant de faire confiance à un classement, vous devez comprendre ce qu’il mesure. La Video Arena d’Artificial Analysis n’est pas un benchmark où le développeur soumet ses propres scores — c’est un système de vote aveugle par les utilisateurs.
Ce que les utilisateurs voient (et ne voient pas)
Vous accédez à l’arène, on vous montre deux vidéos générées à partir du même prompt textuel ou de la même image d’entrée, et vous choisissez celle que vous préférez. Vous ne savez pas quel modèle a créé quelle vidéo. Pas d’étiquettes. Pas de contexte. Juste deux clips.
C’est ainsi qu’Artificial Analysis le décrit directement : « Les utilisateurs comparent deux vidéos générées à partir du même prompt textuel sans savoir quel modèle a créé chaque vidéo. » C’est la partie qui compte. Il n’y a pas d’auto-déclaration, pas de benchmarks fournis par les développeurs, pas de page marketing influençant le résultat.
Elo : signal fiable, mais pas infaillible
Le classement utilise un système Elo — la même approche empruntée aux échecs compétitifs. Chaque fois que deux modèles s’affrontent dans un vote, le gagnant gagne des points Elo et le perdant en perd. Un modèle avec un Elo élevé a systématiquement remporté plus d’affrontements contre d’autres modèles qu’il n’en a perdu.
Des scores Elo plus élevés indiquent qu’un modèle est préféré plus souvent. C’est un vrai signal. Il est basé sur des milliers de vrais choix humains, pas des tests synthétiques, pas des exemples sélectionnés à la main, pas une fiche produit.
Nombre de votes et taille d’échantillon : la partie que les gens ignorent
Voilà le problème avec l’Elo pour les nouveaux entrants. Les modèles établis comme Seedance 2.0 ont des milliers de votes derrière leurs scores — Seedance 2.0 a plus de 7 500 échantillons de votes dans la catégorie T2V. Le nombre d’échantillons de HappyHorse n’est pas encore détaillé publiquement. Plus de votes = score plus stable. Un modèle plus récent avec moins d’affrontements peut varier plus dramatiquement à chaque nouveau vote.

Ces chiffres vont évoluer à mesure que davantage de votes arrivent. La direction de ce changement est inconnue. Gardez cela à l’esprit avant de construire des décisions de pipeline autour d’un chiffre qui a deux jours.
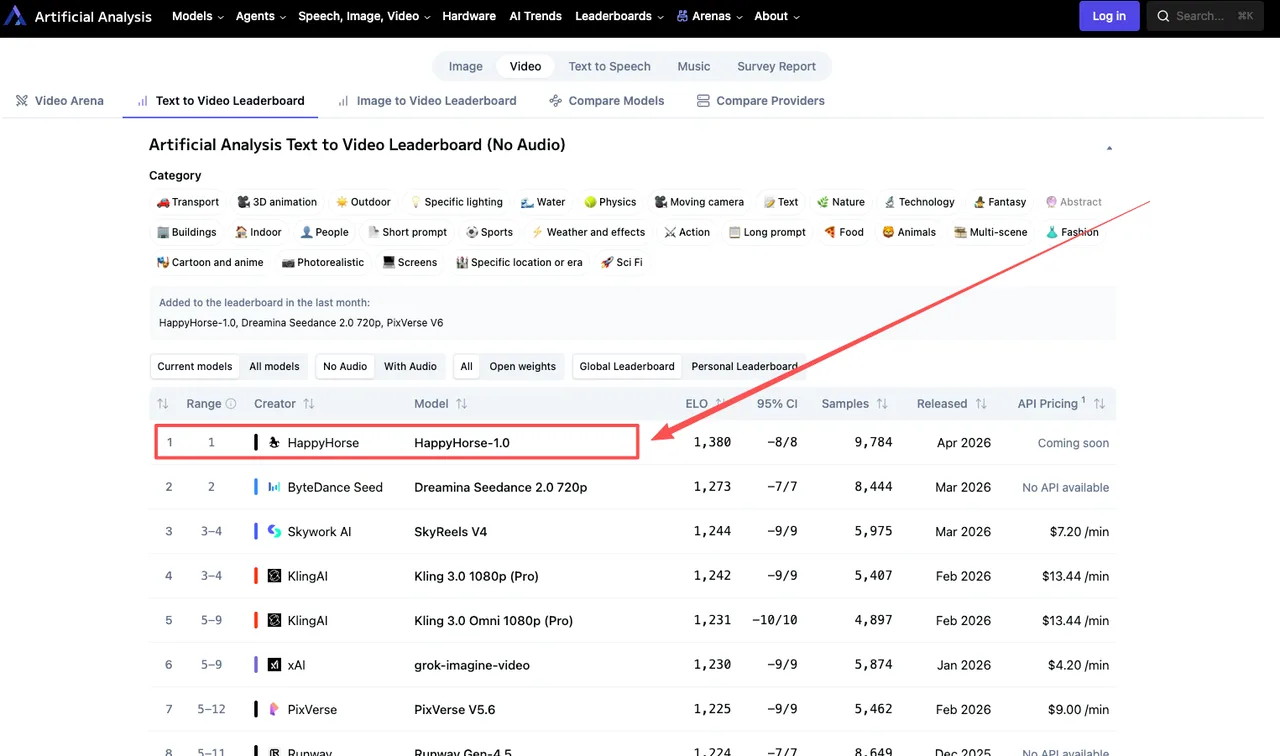
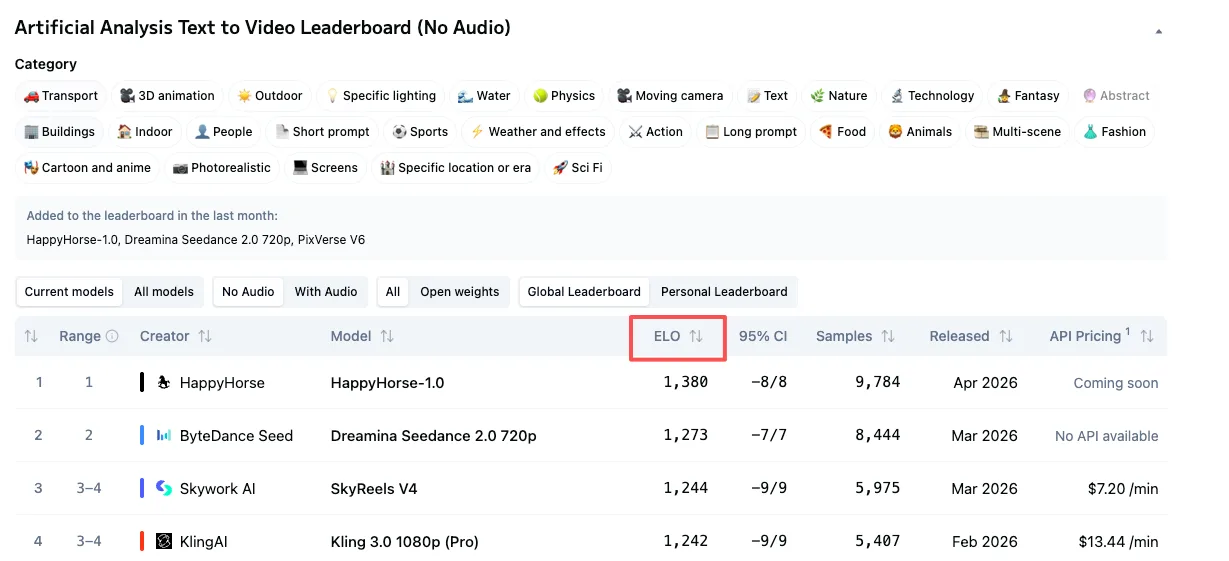
Ce que HappyHorse-1.0 score réellement
Les chiffres actuels, extraits du classement en direct début avril 2026 :
T2V (sans audio) : HappyHorse-1.0 mène avec un score Elo de 1357, devant Dreamina Seedance 2.0 à 1273, SkyReels V4 à 1244, et Kling 3.0 Pro à 1243.
I2V (sans audio) : HappyHorse-1.0 mène avec un Elo de 1402, avec Seedance 2.0 à 1355 et Grok Imagine Video à 1331.
Cet écart de 84 points en I2V sans audio n’est pas négligeable. Un écart Elo de 60 points signifie qu’un modèle gagne environ 58–59 % des affrontements en aveugle — significatif. Un écart de 80+ points est encore plus fort.
La question de l’audio s’inverse
Pour l’Image-to-Video avec audio, HappyHorse-1.0 mène actuellement avec un score Elo de 1160, Dreamina Seedance 2.0 étant à 1158. Un écart de 2 points est du bruit statistique. Et en T2V avec audio, Seedance 2.0 mène à 1220 avec HappyHorse à 1215.
Le tableau est donc plus nuancé que « HappyHorse est #1 partout. » Il est #1 par une marge significative quand l’audio est exclu. Quand la qualité audio entre en jeu, il est essentiellement à égalité avec Seedance 2.0.
Ce que disent les affirmations sur l’architecture (et ce qu’elles ne prouvent pas)
Plusieurs sites décrivant HappyHorse indiquent qu’il tourne sur une architecture Transformer à flux unique avec environ 15 milliards de paramètres, avec des vitesses de génération annoncées d’environ 38 secondes pour un clip 1080p sur un seul H100. Au 8 avril 2026, les liens GitHub et Hugging Face sur ces sites HappyHorse pointent vers des pages « bientôt disponible » ou renvoient des erreurs 404. Les poids ne sont pas téléchargeables publiquement.
Ces affirmations architecturales sont plausibles — mais elles ne sont pas vérifiées. Aucun audit technique indépendant n’a confirmé le nombre de paramètres, le type d’architecture ou les vitesses d’inférence. Traitez-les comme des affirmations, pas des confirmations.
Pourquoi des modèles inconnus peuvent gagner sur Elo
C’est ce qui perturbe les gens qui supposent que les classements récompensent la notoriété de la marque.
L’Elo ne se soucie pas de qui a construit le modèle. Il ne sait pas si vous êtes Google ou un laboratoire de trois personnes. La Video Arena d’Artificial Analysis utilise le système de notation Elo et repose entièrement sur des votes en aveugle d’utilisateurs réels. Il ignore les paramètres, les publications et le battage médiatique — il ne se soucie que d’une question : « Quelle vidéo avez-vous préféré après avoir regardé les deux ? »
C’est en fait une fonctionnalité. C’est l’un des rares systèmes d’évaluation où une marque bien financée ne peut pas acheter un meilleur résultat en publiant un article favorable.
Ce schéma s’est déjà produit
Les lancements anonymes en pré-lancement sont devenus un schéma dans l’écosystème IA chinois. La situation Pony Alpha de février 2026 est le précédent le plus clair — un modèle mystérieux est apparu sur OpenRouter, a déclenché un jeu de devinettes, et s’est avéré être le GLM-5 de Z.ai faisant un test de charge furtif. HappyHorse correspond à ce modèle : nom inconnu, pas d’attribution d’équipe au lancement, page d’accueil avec des liens GitHub « bientôt disponible », sorties solides.
Qu’il s’agisse d’un grand laboratoire effectuant une vérification silencieuse des capacités ou d’une nouvelle équipe — c’est encore non résolu. Mais le score Elo lui-même est réel quelle que soit la situation.
La limitation que l’Elo ne peut pas cacher
L’Elo mesure une chose : quelle vidéo les utilisateurs réels ont préférée lors d’une comparaison en aveugle. Il ne mesure pas les performances du modèle dans des exécutions par lots. Il ne mesure pas la disponibilité de l’API, la latence sous charge, ni si la qualité des sorties se maintient quand vous générez à grande échelle par rapport à des exemples sélectionnés pour l’arène.
Un modèle peut avoir d’excellents résultats en test aveugle et être complètement inutilisable en production. Ce sont des questions distinctes.
Ce que « #1 au classement » ne signifie pas pour les développeurs
C’est là où je ralentirais si vous êtes sur le point de prendre une décision d’outil basée sur le classement actuel de HappyHorse.
Pas d’API, pas d’accès en production
Trois choses feraient passer HappyHorse de « entrée au classement » à « option réelle » : un dépôt GitHub avec des poids réels et du code d’inférence, une fiche de modèle HuggingFace avec des détails vérifiables et une licence, ou un point de terminaison API avec une tarification documentée. Aucun n’existe au moment de cet écrit.
Si vous ne pouvez pas l’appeler, vous ne pouvez pas l’utiliser. La position au classement est une information sur la qualité des sorties, pas sur la disponibilité.
Les performances audio changent le calcul
Si votre flux de travail nécessite de l’audio — voix off, son ambiant, synchronisation labiale — l’avance de HappyHorse disparaît essentiellement. L’écart entre lui et Seedance 2.0 dans les catégories avec audio est de 5 points en T2V et 2 points en I2V. Ce sont des égalités dans la variance normale de l’Elo.
Pour les cas d’usage nécessitant de l’audio, le champ pratique ressemble actuellement à une égalité Seedance/HappyHorse en tête, avec SkyReels V4 un cran en dessous.
Responsabilité de l’équipe : inconnue
Artificial Analysis a décrit HappyHorse comme « pseudonyme » quand il a ajouté le modèle à l’arène. Un ensemble de sites connectés au modèle affirme qu’il a été construit par l’équipe Future Life Lab chez Taotian Group (Alibaba), dirigée par Zhang Di, ancien responsable de Kling AI. Une autre analyse l’a relié à un projet open-source de Sand.ai appelé daVinci-MagiHuman, qui partage des spécifications presque identiques. Aucun n’a été officiellement confirmé.
Pour un outil de production, la responsabilité de l’équipe compte pour les corrections de bugs, les mises à jour du modèle et le support à long terme. Avec des modèles pseudonymes, vous n’avez pas cette clarté.
Comment lire le classement vidéo en tant que développeur
Un cadre concret, pas des abstractions.
Utilisez l’Elo comme signal de qualité, pas comme décision d’achat. Si un modèle gagne systématiquement des comparaisons en aveugle contre des concurrents bien financés, cela vous dit quelque chose de réel sur ce qu’il produit. C’est à noter. Cela ne vous dit rien sur les conditions d’API, la tarification, la latence, ni si l’équipe répond aux rapports de bugs.
Le classement pratique commence au #3. Les deux modèles de plus haute qualité par Elo — HappyHorse et Seedance 2.0 — sont tous deux inaccessibles via l’API publique. Le niveau suivant — SkyReels V4, Kling 3.0, PixVerse V6 — est là où les vraies décisions d’intégration se prennent actuellement.
Quand agir tôt sur un nouveau participant au classement. Si un modèle est en tête avec un écart Elo significatif, a une version GitHub vérifiée et que la documentation existe — vaut la peine de tester immédiatement. S’il est en tête mais que GitHub dit « bientôt disponible » — programmez un rappel pour vérifier dans deux semaines. Ne restructurez pas un pipeline autour de vapeur.
Consultez directement le classement en direct, pas les articles. Y compris celui-ci. Les scores Elo bougent quotidiennement. Les chiffres que j’ai référencés ici reflètent début avril 2026 et auront évolué au moment où vous lirez ceci.
FAQ
Depuis combien de temps HappyHorse-1.0 est-il sur le classement d’Artificial Analysis ?
Artificial Analysis l’a annoncé le 7 avril 2026, le décrivant comme un modèle pseudonyme nouvellement ajouté. Au moment de cet écrit, il est en ligne depuis environ 48 heures et les votes continuent de s’accumuler.
Un modèle peut-il rester #1 sur Elo indéfiniment ?
Pas habituellement. À mesure que de nouveaux modèles entrent dans l’arène et accumulent plus de votes, les classements évoluent. Un modèle qui domine le deuxième jour avec un petit échantillon peut se stabiliser plus bas à mesure que le pool de votes s’approfondit. Le score est toujours en direct — il reflète les données actuelles, pas un jugement permanent.
Artificial Analysis vérifie-t-il qui soumet des modèles à l’arène ?
Artificial Analysis n’a pas publié de politique de vérification formelle pour les soumissions de modèles. Ils ont décrit HappyHorse-1.0 comme « pseudonyme » lors de son annonce, ce qui suggère que l’identité de l’équipe leur est connue mais n’est pas divulguée publiquement. S’ils effectuent un audit technique des modèles soumis n’est pas documenté.
Devrais-je choisir un modèle basé sur le score Elo seul ?
Non. L’Elo vous renseigne sur la préférence visuelle dans des comparaisons en aveugle. Il ne dit rien sur la disponibilité de l’API, le coût par génération, la latence, la disponibilité, la politique de contenu, ou si le modèle existera dans trois mois. C’est un signal parmi plusieurs.
Quelles autres métriques comptent en parallèle des classements ?
L’accès à l’API et la documentation ; la tarification par génération ou par minute ; la latence et le comportement au démarrage à froid à votre fréquence d’utilisation ; le nombre d’échantillons derrière le score Elo (plus de votes = plus stable) ; et si l’équipe a un historique de maintenance et de mise à jour du modèle. La page de comparaison de modèles WaveSpeed suit plusieurs de ces dimensions pour les modèles accessibles si vous voulez un point de départ.
Voilà où en sont les choses. Un modèle avec une équipe inconnue et aucun poids public vient de dépasser le benchmark vidéo le plus crédible dont nous disposons, avec une marge difficile à ignorer. Qu’il devienne une vraie option de production dépend entièrement de ce qui sera publié dans les prochaines semaines.
À surveiller. Pas encore à exploiter.
La suite arrive.
Essayez HappyHorse-1.0 sur WaveSpeedAI
HappyHorse-1.0 est désormais disponible sur WaveSpeedAI :
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir