Qu'est-ce que HappyHorse-1.0 ? Le mystérieux modèle IA vidéo n°1
HappyHorse-1.0 vient d'atteindre la première place sur Artificial Analysis sans équipe publique connue. Voici ce qui est confirmé et ce qui reste à vérifier.

Salut tout le monde. Ici Dora. Je consulte le classement de l’Artificial Analysis Video Arena presque chaque semaine — votes d’utilisateurs à l’aveugle, classements Elo, sans auto-déclaration des laboratoires. La semaine dernière, un nom que je n’avais jamais vu trônait en tête des classements texte-vers-vidéo et image-vers-vidéo. HappyHorse-1.0. Aucune équipe connue. Aucune marque. Des liens GitHub et HuggingFace affichant « bientôt disponible ».
Si vous évaluez des modèles vidéo avant de les intégrer dans un pipeline — et que vous avez appris à vous méfier du battage médiatique autour des classements — voici une analyse de ce qui est confirmé, de ce qui n’est que prétendu, et de ce que cet écart signifie pour les décisions à prendre maintenant.
Comment HappyHorse-1.0 est apparu sur le radar
Artificial Analysis Video Arena : ce qu’est ce classement et pourquoi il compte
Artificial Analysis gère une arène vidéo. Les utilisateurs soumettent une invite textuelle ou une image de référence. Le système génère des résultats à partir de deux modèles. Les utilisateurs voient les deux côte à côte, sans savoir quel modèle a produit lequel, et choisissent celui qu’ils préfèrent.
Ces votes alimentent un système de classement Elo — les mêmes mathématiques utilisées dans les classements d’échecs. Le score d’un modèle augmente quand les utilisateurs le choisissent, baisse quand ce n’est pas le cas, ajusté selon la force de l’adversaire. Le résultat est un classement basé entièrement sur la préférence humaine agrégée dans des conditions aveugles. Pas de soumissions de laboratoire triées sur le volet. Pas de benchmarks auto-déclarés.
Votes d’utilisateurs à l’aveugle et Elo : pas des benchmarks auto-déclarés
Tous les autres classements de modèles vidéo que j’ai vus ont le même problème — les personnes qui rapportent les chiffres sont celles qui ont construit le modèle. Artificial Analysis supprime cela. Le signal de qualité provient entièrement d’utilisateurs qui ne savent pas ce pour quoi ils votent.
Les différences Elo sont relatives. Un écart de 60 points signifie qu’un modèle gagne environ 58-59 % des confrontations directes. Un écart de 5 points est du bruit statistique.
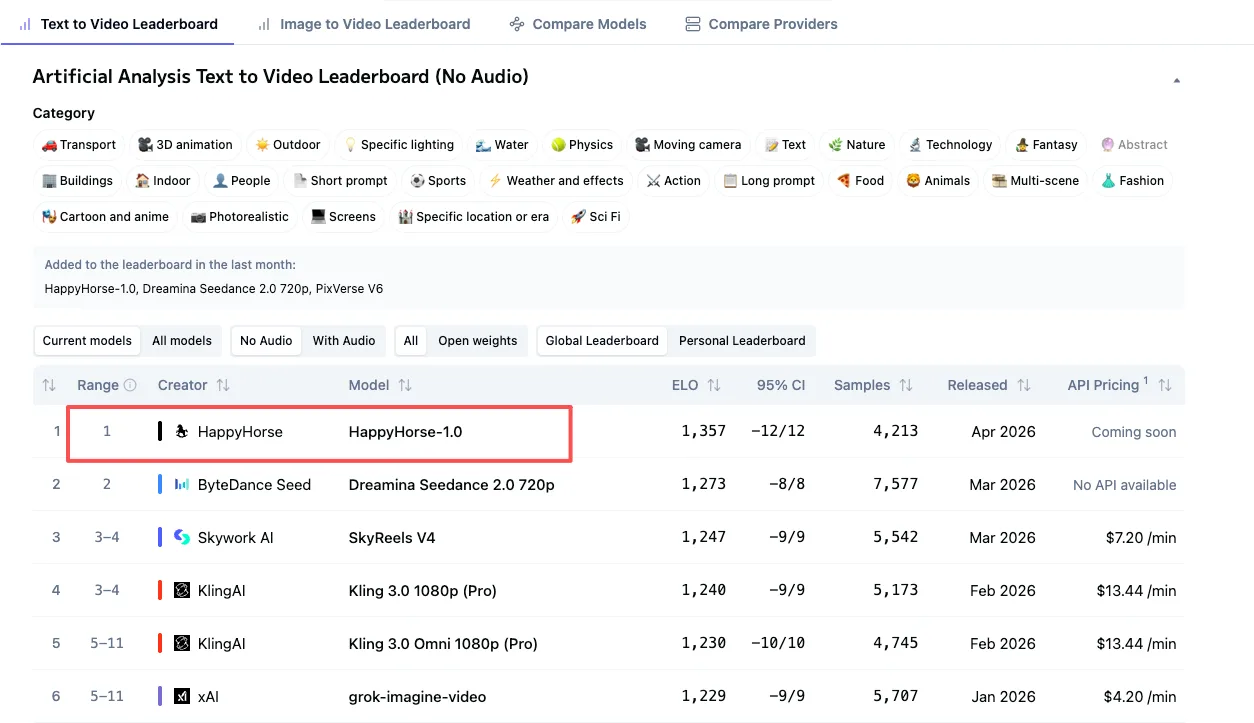
T2V #1 (Elo 1333), I2V #1 (Elo 1392) — ce que ces chiffres signifient en contexte
Début avril 2026, les positions de HappyHorse-1.0 sur le classement Artificial Analysis :
| Catégorie | Elo | Rang |
|---|---|---|
| Texte-vers-Vidéo (sans audio) | 1333 | #1 |
| Image-vers-Vidéo (sans audio) | 1392 | #1 |
| Texte-vers-Vidéo (avec audio) | 1205 | #2 |
| Image-vers-Vidéo (avec audio) | 1161 | #2 |
Le précédent #1 en T2V sans audio était Dreamina Seedance 2.0 à 1 273. Un écart Elo de 60 points n’est pas négligeable. Dans la catégorie I2V sans audio, HappyHorse devance Seedance 2.0 de 37 points.
Avec audio inclus, la situation s’inverse — Seedance 2.0 dépasse HappyHorse pour la première place. L’écart est étroit : 14 points en T2V avec audio, 1 point en I2V avec audio.
Une chose à garder à l’esprit : les scores Elo des modèles récemment ajoutés sont plus volatils que ceux des modèles établis. Seedance 2.0 compte plus de 7 500 échantillons de votes dans la catégorie T2V. Le nombre d’échantillons de HappyHorse n’est pas encore décomposé publiquement. Ces chiffres évolueront au fur et à mesure que les votes afflueront. La direction de cette évolution est inconnue. Cette conclusion a une date d’expiration — les modèles évoluent vite.
Ce que nous savons sur le modèle
Tout dans cette section provient de happyhorses.io. Je le signale d’emblée car aucune de ces affirmations techniques n’a été vérifiée indépendamment par un tiers à la date de publication de cet article (8 avril 2026).
Architecture Transformer à auto-attention unique, conception à 40 couches (affirmée par happyhorse-ai.com, non vérifiée)
Le site décrit un Transformer unifié unique à 40 couches. Les tokens de texte, un latent d’image de référence, et des tokens de vidéo et d’audio bruités sont — selon le site — conjointement débruités au sein d’une seule séquence de tokens. Les 4 premières et les 4 dernières couches utilisent apparemment des projections spécifiques à la modalité. Les 32 couches intermédiaires partagent des paramètres entre toutes les modalités. Pas d’attention croisée.
Un site marketing séparé (happy-horse.art) revendique 15 milliards de paramètres. Ce chiffre n’apparaît pas sur le domaine principal ni dans aucun rapport indépendant.
La description de l’architecture est suffisamment précise pour être réfutable — si et quand les poids deviennent disponibles, quelqu’un la vérifiera ou la contredira en quelques heures.
Génération audio-vidéo multilingue : chinois, anglais, japonais, coréen, allemand, français (affirmé)
Le site liste six langues nativement prises en charge pour la génération conjointe audio-vidéo : le chinois, l’anglais, le japonais, le coréen, l’allemand et le français. La page happy-horse.art ajoute le cantonais comme septième langue et mentionne « une synchronisation labiale ultra-faible WER ».
Je n’ai aucun moyen de tester ces affirmations. Pas de poids, pas d’API, pas de démo reproductible. Les sorties de l’arène visibles sur Artificial Analysis ne testent pas systématiquement les capacités audio multilingues.
Texte-vers-vidéo et image-vers-vidéo dans un seul pipeline (rapporté)
Le site décrit un pipeline unifié gérant à la fois T2V et I2V. C’est cohérent avec les données du classement — HappyHorse-1.0 apparaît dans les deux arènes sous le même nom de modèle, suggérant un modèle unique plutôt que des modèles spécialisés séparés.
Le site revendique également une synthèse audio conjointe — dialogues, sons ambiants et effets Foley générés en même temps que la vidéo en une seule passe. Les classements #2 dans les catégories « avec audio » suggèrent que la génération audio existe et est compétitive, même si elle n’est pas en tête.
Ce qui reste non vérifié
Identité de l’équipe : pseudonyme selon Artificial Analysis, supposée d’origine asiatique
Personne n’a publiquement revendiqué la paternité de HappyHorse-1.0. Artificial Analysis eux-mêmes ont utilisé le mot « pseudonyme » lors de l’annonce de l’ajout du modèle à l’arène — ce qui signifie qu’il a été soumis sans équipe ou organisation vérifiable attachée.
Les spéculations de la communauté sur X ont pointé vers une origine basée en Asie. Le raisonnement tient en partie aux capacités multilingues (langues CJK en vedette), en partie aux patterns temporels qui ressemblent aux lancements furtifs précédents des laboratoires d’IA chinois. Rien de tout cela ne constitue une confirmation. La spéculation sur l’origine n’est pas une identification de l’origine.
Affirmation open source : liens GitHub et HuggingFace marqués « bientôt disponible », inaccessibles à la date de publication
Le site happyhorse-ai.com indique : « Modèle de base, modèle distillé, modèle de super-résolution et code d’inférence — tous publiés. » Il indique également : « Tout est ouvert. »
Au 8 avril 2026, le lien GitHub et le lien Model Hub sur ce même site affichent tous deux « bientôt disponible ». Ils ne mènent nulle part. J’ai cherché des poids HappyHorse sur HuggingFace et GitHub. Rien.
Le site dit que tout est publié. Les liens disent que non. Cela ne correspondait pas à la documentation.
Nombre de paramètres et exigences matérielles : aucune confirmation indépendante
L’affirmation des 15 milliards de paramètres apparaît sur un site secondaire (happy-horse.art), pas sur le domaine principal. Le site principal mentionne des vitesses d’inférence — environ 2 secondes pour un clip de 5 secondes en 256p, environ 38 secondes pour du 1080p sur un H100 — mais ce sont des chiffres de fournisseur auto-déclarés. Aucun tiers n’a publié de benchmarks indépendants sur la vitesse d’inférence ou les exigences mémoire.
Sans poids téléchargeables, personne en dehors des créateurs du modèle ne peut vérifier le nombre de paramètres, les détails architecturaux ou les exigences matérielles. C’est là que mes données s’arrêtent.
Spéculation WAN 2.7 : ce qui la motive, pourquoi elle reste non confirmée
Certains membres de la communauté ont spéculé que HappyHorse-1.0 serait en réalité WAN 2.7 — une prochaine version de la famille de modèles vidéo WAN d’Alibaba — testé sous un pseudonyme avant le lancement officiel.
La logique : WAN 2.6 figure sur le classement Artificial Analysis à Elo 1 189 pour T2V (bien en dessous de HappyHorse). Les lancements anonymes avant les sorties officielles sont devenus un pattern dans l’écosystème d’IA chinois. La situation Pony Alpha de février 2026 est le précédent le plus clair — un modèle mystérieux est apparu sur OpenRouter, a déclenché un jeu de devinettes, et s’est avéré être GLM-5 de Z.ai faisant un test de charge furtif.
Mais des patterns parallèles ne prouvent pas l’identité. La description architecturale sur le site de HappyHorse ne correspond pas manifestement à l’architecture WAN publiquement connue. Aucune fuite de poids, aucune empreinte digitale d’API, aucune confirmation interne n’a relié les deux. Je ne sais pas. Mieux vaut cela qu’inventer quelque chose.
Pourquoi « l’origine mystérieuse » est pertinente pour les développeurs
L’Elo est aveugle — le signal de qualité est réel quelle que soit l’identité de l’équipe
Les utilisateurs qui ont voté pour les sorties de HappyHorse plutôt que pour Seedance 2.0 et Kling 3.0 ne savaient pas pour quoi ils votaient. Si le modèle gagne systématiquement des comparaisons à l’aveugle, cela vous dit quelque chose de réel sur la qualité des sorties — indépendamment de qui l’a construit.
Le signal de qualité ne nécessite pas de connaître l’équipe. Il nécessite de faire confiance à la méthodologie.
Incertitude d’accès : pas d’API stable ni de poids publics aujourd’hui
Signal de qualité et utilisabilité pratique sont deux choses différentes. À ce jour : pas d’API publique, pas de poids téléchargeables, pas de tarification documentée, pas de SLA.
Pour quiconque construit un pipeline ou déploie un produit, HappyHorse-1.0 n’existe pas encore comme option. Le rang dans le classement est réel. L’accès ne l’est pas.
Ce qu’il faut surveiller : publication GitHub, disponibilité des poids, signaux d’accès API
Trois choses feraient passer HappyHorse de « entrée dans un classement » à « option réelle » : un dépôt GitHub avec de vrais poids et du code d’inférence, une fiche de modèle HuggingFace avec des détails vérifiables et une licence, ou un endpoint API avec une tarification documentée.
Rien n’existe à l’heure où j’écris ces lignes.
Sa place dans le paysage actuel des modèles vidéo
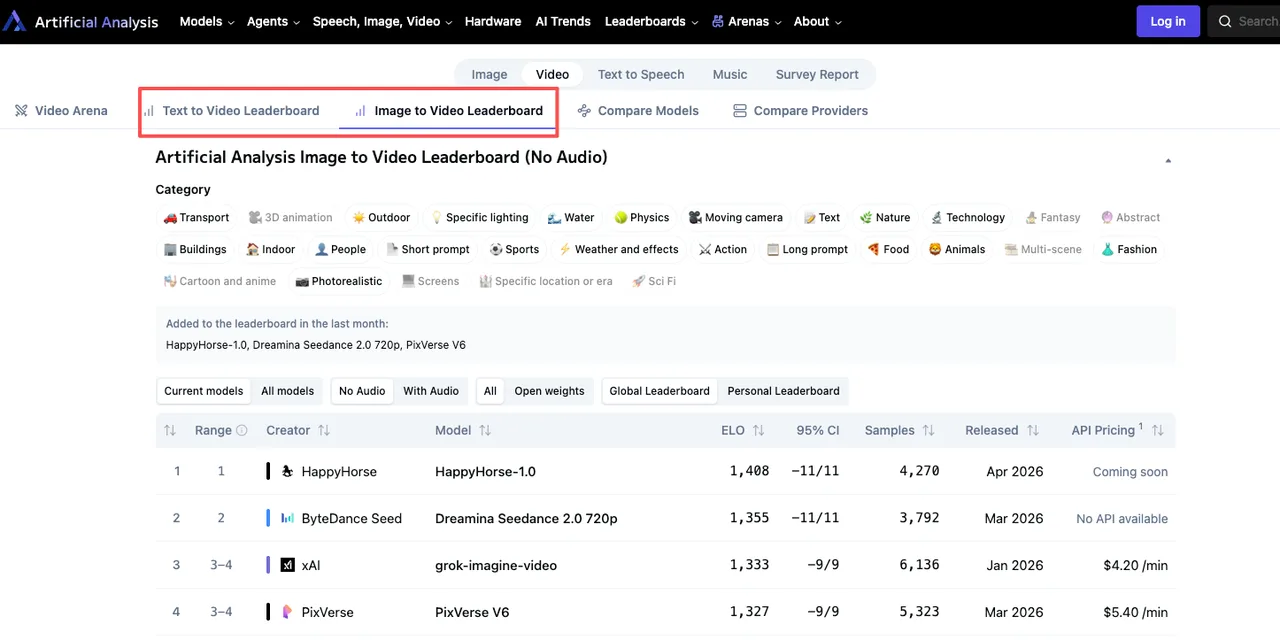
Contexte du classement T2V et I2V actuel
Haut du classement Artificial Analysis T2V (sans audio), début avril 2026 :
| Rang | Modèle | Elo | API disponible | Sorti |
|---|---|---|---|---|
| #1 | HappyHorse-1.0 | 1333 | Non | Avr 2026 |
| #2 | Seedance 2.0 720p | 1273 | Pas d’API publique | Mar 2026 |
| #3 | SkyReels V4 | 1245 | Oui (7,20 $/min) | Mar 2026 |
| #4 | Kling 3.0 1080p Pro | 1241 | Oui (13,44 $/min) | Fév 2026 |
| #5 | PixVerse V6 | 1240 | Oui (5,40 $/min) | Mar 2026 |
L’I2V (sans audio) suit le même schéma : HappyHorse à 1 392, Seedance 2.0 à 1 355, PixVerse V6 à 1 338, Grok Imagine Video à 1 333, Kling 3.0 Omni à 1 297.

Les deux modèles de plus haute qualité par Elo — HappyHorse et Seedance 2.0 — sont tous deux inaccessibles via une API publique. Les positions 3 à 5 en T2V sont séparées par 5 points Elo — une égalité statistique.
Pourquoi cela compte pour les équipes évaluant des stacks de génération vidéo
Deux questions distinctes. Quel modèle produit la meilleure sortie en comparaison à l’aveugle ? HappyHorse-1.0, sur la base des données actuelles. Quel modèle pouvez-vous réellement intégrer aujourd’hui ? Pas HappyHorse.
Le classement pratique commence à la position #3. SkyReels V4 offre le meilleur rapport qualité-prix parmi les options accessibles. Kling 3.0 Pro coûte plus cher mais tourne nativement en 1080p. PixVerse V6 est le moins cher par minute dans le tier supérieur.
Si HappyHorse publie des poids ou une API dans les semaines à venir, le calcul change. C’est une possibilité réelle — le lancement furtif puis la publication officielle s’est joué plusieurs fois cette année. Il est aussi possible que rien ne se matérialise pendant des mois.
FAQ
Qui a créé HappyHorse-1.0 ?
Inconnu. Artificial Analysis le décrit comme « pseudonyme ». Les spéculations de la communauté pointent vers une équipe basée en Asie, mais aucune organisation ne l’a revendiqué.
HappyHorse-1.0 est-il disponible à l’utilisation en ce moment ?
Pas de manière prête pour la production. Les liens GitHub et Model Hub indiquent « bientôt disponible ». Pas d’API publique, pas de poids téléchargeables, pas de tarification documentée au 8 avril 2026.
HappyHorse-1.0 est-il identique à WAN 2.7 ?
Non confirmé. La spéculation existe parce que les lancements anonymes avant les sorties officielles sont courants dans l’écosystème d’IA chinois — le précédent Pony Alpha / GLM-5 étant le plus récent. Aucune preuve directe ne relie HappyHorse à la famille WAN d’Alibaba.
Comment Artificial Analysis classe-t-il les modèles vidéo ?
Vote d’utilisateurs à l’aveugle. Les utilisateurs comparent deux vidéos issues du même prompt sans savoir quel modèle a produit lequel, puis choisissent leur préférence. Les votes alimentent un système de classement Elo.
Quand les poids de HappyHorse-1.0 seront-ils publiés ?
Aucun calendrier donné. « Bientôt disponible » pour GitHub et Model Hub. Aucun engagement public sur lequel s’appuyer.
Les chiffres du classement sont réels. Tout le reste — équipe, poids, accès, calendrier — est en attente. À vérifier.
Essayez HappyHorse-1.0 sur WaveSpeedAI
HappyHorse-1.0 est maintenant disponible sur WaveSpeedAI :
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir