Muse Spark vs Llama 4 : le virage stratégique de Meta
Meta a abandonné Llama open-weight au profit de Muse Spark en source fermée. Ce qui a changé, pourquoi cela compte pour les développeurs, et si des versions open source futures sont réalistes.

Meta vient de lancer une nouvelle série de modèles. Si vous avez développé quoi que ce soit sur Llama 4 au cours de l’année passée, vous vous demandez probablement s’il vaut mieux continuer ou commencer à planifier une migration.
Je suis Dora. J’ai passé hier à lire toute la documentation publiée par Meta, à croiser les benchmarks tiers et à essayer de comprendre ce que cela signifie concrètement pour les personnes ayant Llama dans leur stack. Cet article détaille ce qui a changé, ce qui n’a pas changé, et où en sont les développeurs aujourd’hui.
Ce qui a changé entre Llama 4 et Muse Spark
Architecture : Neuf mois, repartie de zéro
Meta Superintelligence Labs — l’unité formée après qu’Alexandr Wang a rejoint l’entreprise en tant que directeur de l’IA à la mi-2025 — a reconstruit toute la stack IA depuis zéro. Nouvelle infrastructure, nouvelle architecture, nouveaux pipelines de données. Ce n’est pas du marketing ; c’est ce qu’affirme le blog technique de Meta. Muse Spark est le premier modèle issu de cette reconstruction.
Llama 4 utilisait une architecture Mixture-of-Experts avec des poids ouverts. Muse Spark est un modèle de raisonnement nativement multimodal — ce qui signifie que la vision n’a pas été ajoutée après coup, elle a été intégrée dès le départ. Il prend en charge l’utilisation d’outils, le raisonnement visuel en chaîne et l’orchestration multi-agents. Llama 4 ne disposait d’aucune de ces capacités de manière native.
Le modèle introduit également des modes de raisonnement hiérarchisés : Instant pour les requêtes légères, Thinking pour le travail étape par étape, et un mode Contemplating qui exécute plusieurs sous-agents en parallèle. Ce dernier est la réponse de Meta à Gemini Deep Think et au raisonnement étendu de GPT Pro.
Efficacité : une affirmation de Meta, pas une conclusion indépendante
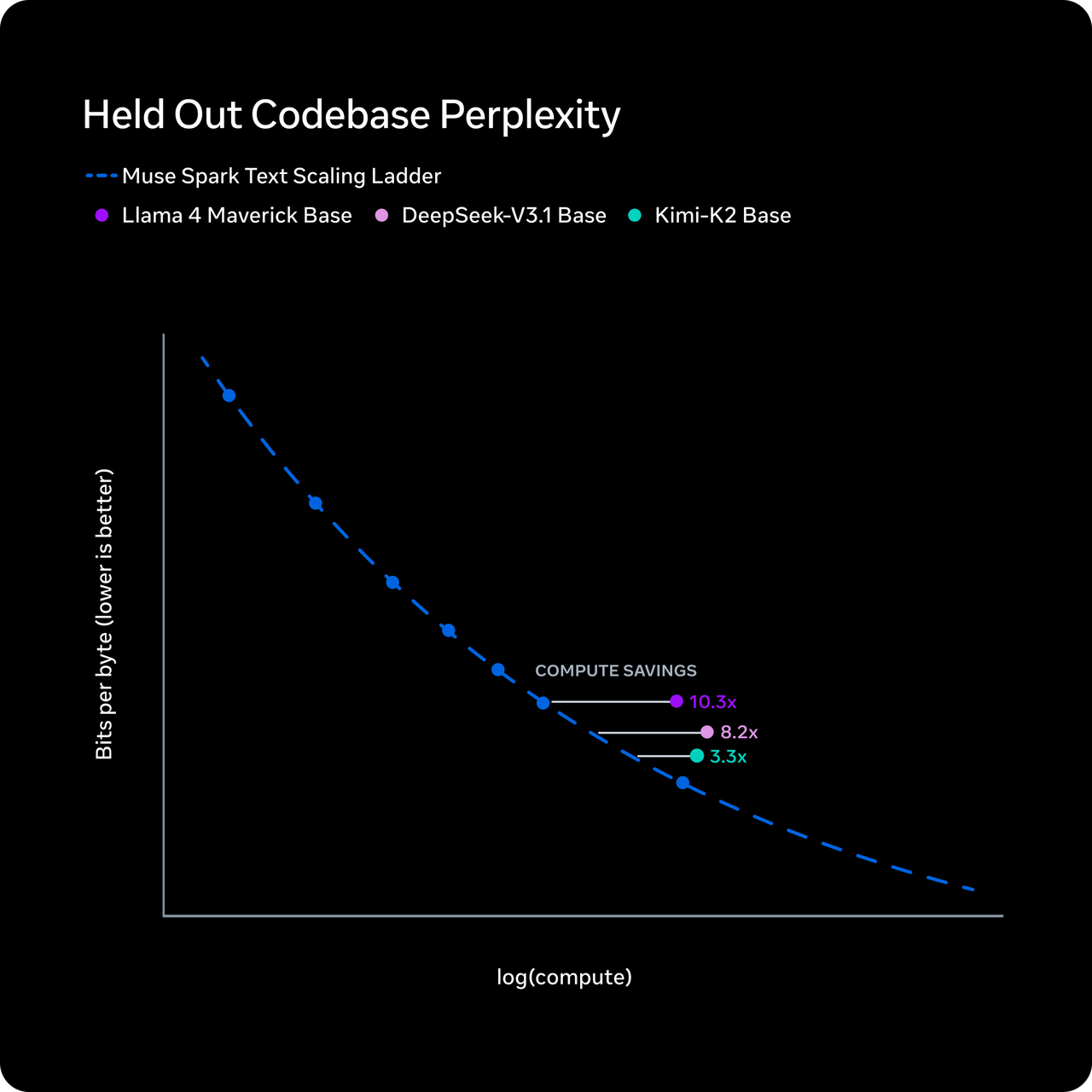
Meta affirme que Muse Spark atteint le niveau de capacité de Llama 4 Maverick en utilisant plus de dix fois moins de calcul. Le mécanisme qu’ils décrivent est la « compression de la pensée » — lors de l’apprentissage par renforcement, le modèle est pénalisé pour un temps de réflexion excessif, ce qui le force à raisonner avec moins de tokens sans perte de précision.
Je veux être précis ici : il s’agit d’une affirmation de Meta. Elle n’a pas été reproduite de manière indépendante. Les chiffres d’efficacité en tokens d’Artificial Analysis montrent que Muse Spark a utilisé 58 millions de tokens de sortie pour exécuter leur Intelligence Index complet — comparable aux 57 millions de Gemini 3.1 Pro et bien en dessous des 157 millions de Claude Opus 4.6 ou des 120 millions de GPT-5.4. Donc l’argument sur l’efficacité bénéficie d’un certain soutien indépendant, du moins côté sortie.
Écart dans les benchmarks : de 18 à 52
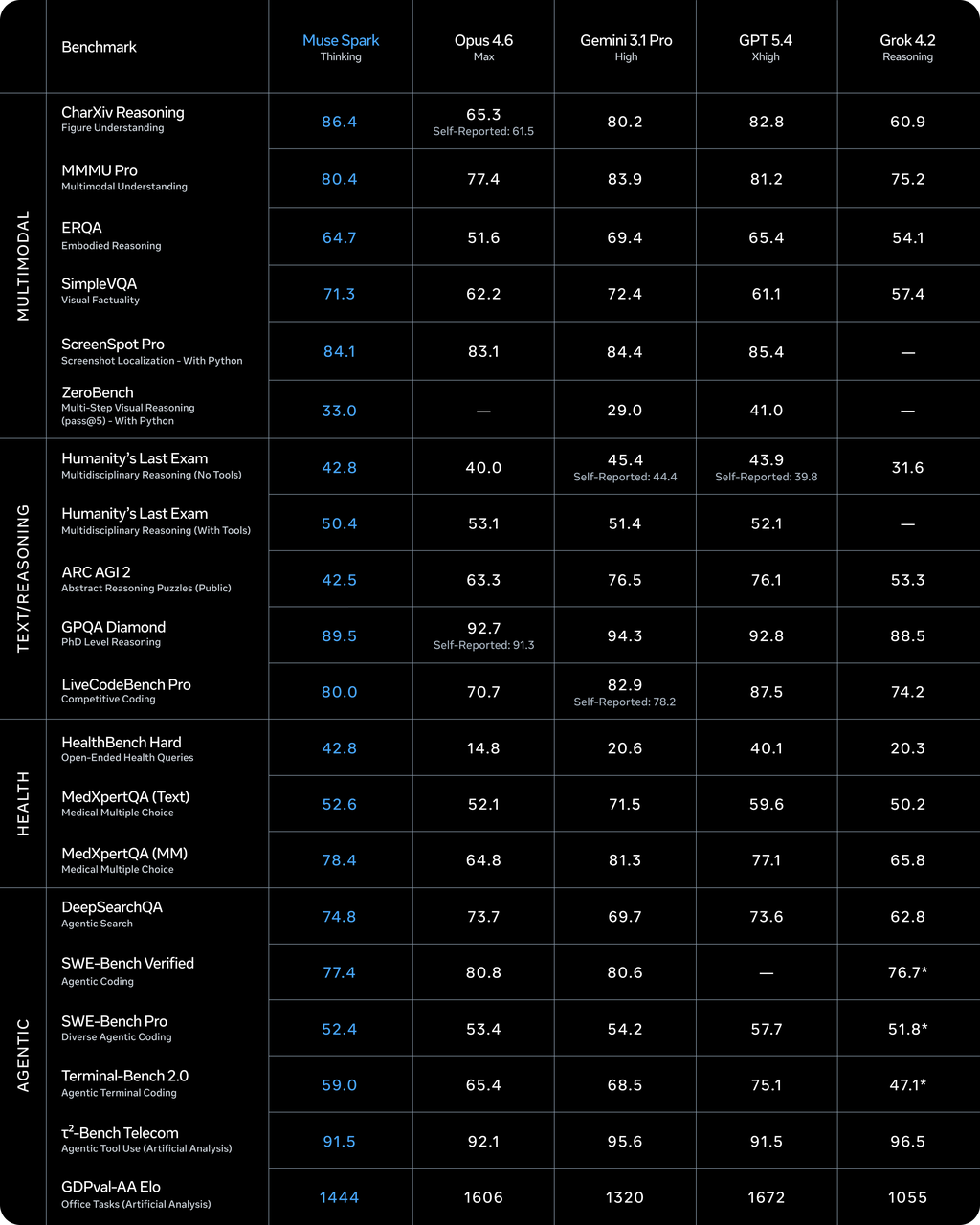
Selon Artificial Analysis, Llama 4 Maverick a obtenu un score de 18 sur l’Intelligence Index à son lancement. Muse Spark en obtient 52. Cela le place quatrième au classement général — derrière Gemini 3.1 Pro Preview et GPT-5.4 (tous deux à 57) et Claude Opus 4.6 (53).
Une mise en garde importante : Artificial Analysis a reçu un accès anticipé de Meta pour évaluer le modèle. Ils ont mené leurs propres évaluations de manière indépendante, mais l’accès lui-même provenait de Meta. Ce ne sont pas encore des benchmarks publics totalement neutres. Les scores sont utiles comme orientation, pas comme vérité absolue.
Où Muse Spark est en tête : les benchmarks de santé (42,8 sur HealthBench Hard, devant les 40,1 de GPT-5.4), le raisonnement visuel (80,5 % sur MMMU-Pro, deuxième après Gemini 3.1 Pro), et la compréhension des graphiques.
Où il est en retard : le code (Terminal-Bench Hard, derrière Claude Sonnet 4.6 et GPT-5.4), les tâches agentiques (GDPval-AA à 1 427 ELO contre 1 676 pour GPT-5.4), et le raisonnement abstrait (ARC-AGI-2 à 42,5 contre 76+ pour les meilleurs concurrents). Meta a explicitement reconnu ces lacunes dans son blog technique, indiquant qu’ils continuent d’investir dans « les systèmes agentiques à long horizon et les flux de travail de codage ».
Le passage de l’ouvert au fermé
Le modèle Llama : poids ouverts, écosystème communautaire
La proposition de valeur de Llama était simple. Téléchargez les poids, exécutez-les sur votre propre matériel, affinez-les pour votre cas d’usage, ne payez que le calcul. L’approche open-weight a construit un écosystème — des milliers de variantes affinées sur Hugging Face, des déploiements auto-hébergés dans des startups et des entreprises, toute une industrie artisanale de modèles quantifiés tournant sur des GPU grand public. Llama 4 Scout tient sur un seul H100. Maverick fonctionne sur une RTX 5090 avec quantification.
Cet écosystème existe toujours. Ces modèles n’ont pas été retirés.
Le modèle Muse Spark : fermé, aperçu API privé uniquement
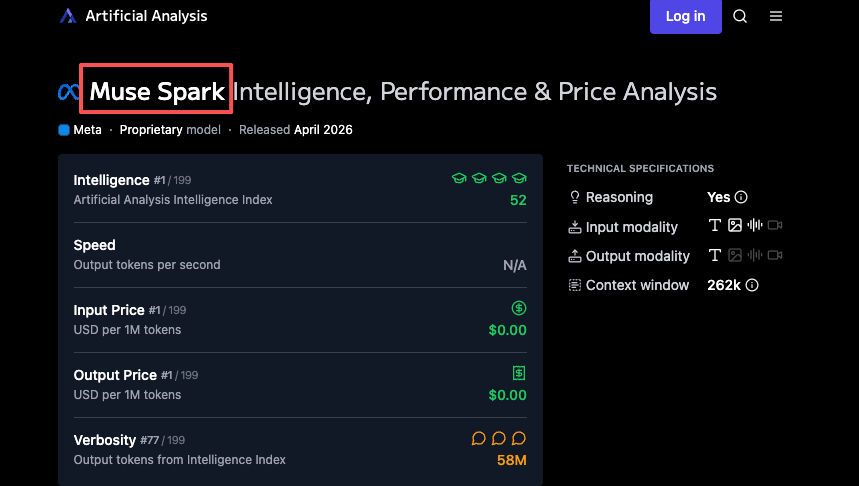
Muse Spark est propriétaire. Pas de poids téléchargeables. Pas d’auto-hébergement. En ce moment, il alimente Meta AI dans toutes les applications de l’entreprise — le site web Meta AI, et bientôt WhatsApp, Instagram, Facebook, Messenger et les lunettes Ray-Ban AI. Les développeurs externes peuvent demander un accès à un aperçu API privé. C’est tout.
C’est plus restrictif que les modèles d’OpenAI ou d’Anthropic, qui offrent au moins un accès API public. Comme l’a noté Fortune dans sa couverture, Muse Spark est « encore plus propriétaire que les modèles propriétaires payants proposés par les concurrents de Meta ».

« Nous espérons rendre open-source les versions futures »
Le billet de blog de Meta contient cette phrase. Zuckerberg a écrit sur Threads à propos de plans pour publier « des modèles de plus en plus avancés qui repoussent les frontières de l’intelligence et des capacités, y compris de nouveaux modèles open source ». Wang a mentionné la mise en open source de versions futures sur X.
Pas de calendrier. Pas d’engagement spécifique sur quel modèle ni quand. Aucune indication sur le fait que « versions futures » signifie que Muse Spark lui-même sera éventuellement ouvert, ou si une branche open-weight distincte continuera en parallèle.
Comparez cela au manifeste de Zuckerberg de 2024 intitulé « L’IA open source est la voie de l’avenir », dans lequel il arguait que l’ouverture de Llama ne nuit pas aux revenus de Meta. C’était il y a dix-huit mois. Le calcul stratégique a clairement évolué. Comme l’analyse de The Next Web l’a formulé, la fermeture est un signal que Meta se considère désormais dans une course où céder des innovations architecturales coûte plus que cela ne rapporte.
Voilà où s’arrêtent mes données. Que les futurs modèles Muse soient réellement ouverts ou non relève de la spéculation. Je ferai une mise à jour dès qu’il y aura quelque chose de concret.
Ce que cela signifie pour les développeurs utilisant actuellement Llama
Llama auto-hébergé : toujours viable, pas déprécié
Quand VentureBeat a directement demandé à Meta si le développement de Llama était terminé, un porte-parole a déclaré : « Nos modèles Llama actuels continueront d’être disponibles en open source. » Cette phrase est soigneusement formulée. Elle confirme que les modèles existants restent disponibles. Elle ne dit rien sur le développement futur de Llama.
Si vous faites tourner Llama 4 Scout ou Maverick en production aujourd’hui, rien n’a changé opérationnellement. Les poids sont toujours sur Hugging Face. Les affinements communautaires fonctionnent toujours. Votre infrastructure n’a pas besoin de bouger.
Compromis opérationnels : aujourd’hui contre demain
Voici la situation pratique. Si vous avez un déploiement Llama fonctionnel — pipeline d’inférence optimisé, coûts prévisibles, équipe familiarisée avec les paramètres — vous avez une quantité connue. Le prix de l’API Muse Spark n’a pas été annoncé. L’accès API public n’a pas été annoncé. L’aperçu privé est sur invitation uniquement.
Passer d’un modèle open-weight auto-hébergé à une API fermée signifie abandonner le contrôle sur la latence, la disponibilité, la structure des coûts et le traitement des données. Pour certaines équipes, ce compromis a du sens. Pour d’autres, non. Le fait est que vous ne pouvez même pas évaluer le compromis pour l’instant, car les conditions d’utilisation de l’API Muse Spark n’existent pas publiquement.
Flux de travail de codage : la lacune reconnue
Si votre déploiement Llama gère la génération de code, la révision de code, ou toute tâche orientée développeur, il n’y a aucune raison de regarder Muse Spark maintenant. Meta l’a dit eux-mêmes — le codage est une faiblesse actuelle. Sur Terminal-Bench Hard, Muse Spark est derrière Claude Sonnet 4.6 et GPT-5.4. Sur GDPval-AA, qui mesure les tâches réelles, il obtient 1 427 ELO contre 1 648 pour Claude Sonnet 4.6.
Cela correspond à ma fréquence d’utilisation. La vôtre peut différer. Mais les données sont claires sur ce point.
Pourquoi Meta a fait ce choix
Llama 4 : un faux pas reconnu
Llama 4 a été lancé en avril 2025 avec une réception mitigée. La controverse sur les benchmarks — Meta a utilisé une « version expérimentale de chat » spécialisée et non publiée pour gonfler les scores sur LMArena — a nui à la crédibilité. Les modèles eux-mêmes étaient solides pour leur catégorie de poids, mais n’ont pas déplacé la frontière. À la mi-2025, le narratif était que Meta avait pris du retard sur OpenAI, Anthropic et Google.
Le mandat de Wang
En juin 2025, Meta a dépensé 14,3 milliards de dollars pour acquérir une participation minoritaire de 49 % sans droit de vote dans Scale AI et a recruté le co-fondateur Alexandr Wang en tant que directeur de l’IA. Le mandat était explicite : rattraper. Meta Superintelligence Labs a été créé. Des chercheurs ont été recrutés chez OpenAI, Anthropic et Google avec des packages de rémunération atteignant prétendument des centaines de millions avec l’équité incluse.
Neuf mois plus tard, Muse Spark est le premier résultat. Que cela justifie l’investissement dépend de ce qui vient ensuite — ce modèle est délibérément petit et rapide, avec des versions plus grandes déjà en développement.
Pression concurrentielle
Le calcul est simple. OpenAI et Anthropic sont collectivement valorisés à plus de 1 000 milliards de dollars. Gemini de Google a gagné du terrain sur les marchés grand public et développeur. Meta dépensait 72 milliards de dollars en infrastructure IA en 2025, devant atteindre 115 à 135 milliards en 2026 selon les prévisions, et n’avait pas de modèle compétitif à la frontière à montrer. Quelque chose devait changer.
Cadre de décision pour les développeurs
Restez avec Llama si :
Vous avez besoin de poids ouverts — pour l’auto-hébergement, l’affinage, la conformité sur site ou le contrôle des coûts. Vous exécutez des flux de travail intensifs en codage où Muse Spark présente des lacunes reconnues. Vous avez besoin d’une infrastructure prévisible et auto-gérée qui ne dépend pas d’une liste d’attente API privée. Vous avez déjà investi dans des outils spécifiques à Llama (pipelines de quantification, adaptateurs LoRA, évaluations personnalisées).
Surveillez Muse Spark si :
Vous développez dans l’écosystème produit de Meta — tout ce qui s’intègre avec Instagram, WhatsApp, Facebook ou Messenger. Vous avez besoin d’une forte compréhension multimodale, notamment le raisonnement visuel ou les tâches liées à la santé. Vous êtes prêt à attendre l’accès API public et pouvez évaluer une fois la tarification et les conditions disponibles.
Aucun des deux ne couvre :
La génération d’images. La génération de vidéos. Ce sont des catégories de modèles distinctes. Muse Spark est uniquement en sortie texte, et Llama 4 est uniquement en sortie texte. Si vous avez besoin de capacités de génération, vous regardez des outils entièrement différents.
FAQ

Puis-je toujours utiliser Llama 4 après le lancement de Muse Spark ?
Oui. Llama 4 Scout et Maverick restent disponibles sur Hugging Face et via les partenaires API de Meta. Rien n’a été déprécié ou retiré.
Meta publiera-t-il les poids de Muse Spark ?
Meta a déclaré qu’il « espère rendre open-source les versions futures du modèle ». Il n’y a pas de calendrier, pas d’engagement spécifique concernant Muse Spark lui-même, et aucune indication sur ce que signifient « versions futures » en pratique. Traitez cela comme une aspiration, pas un plan.
Muse Spark est-il meilleur que Llama 4 pour le codage ?
Non. Meta reconnaît explicitement le codage comme une lacune actuelle. Sur les benchmarks spécifiques au codage, Muse Spark est derrière Claude Sonnet 4.6 et GPT-5.4. Si le codage est votre cas d’usage principal, Llama 4 Maverick avec affinage ou un modèle de codage dédié est une meilleure option aujourd’hui.
Quand le prochain modèle Muse arrive-t-il ?
Meta a décrit Muse Spark comme « la première étape » avec « des modèles plus grands déjà en développement ». Pas de dates. Pas de noms. Pas de spécifications au-delà de la confirmation qu’ils existent.
Cela affecte-t-il l’écosystème IA open source plus large ?
C’est un signal, pas un coup fatal. Les modèles Llama open-weight de Meta restent disponibles. D’autres organisations — Mistral, DeepSeek, Qwen d’Alibaba — continuent de publier des modèles ouverts. Mais Meta était le plus grand bailleur de fonds corporate des modèles open-weight à la frontière. Si leur investissement à la frontière se déplace définitivement vers des modèles fermés, l’écosystème perd son contributeur le mieux financé. Cela compte sur des années, pas des semaines.
C’est tout. Plus d’informations quand l’API sera rendue publique.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
