HappyHorse-1.0 vs Seedance 2.0 : Lequel s'impose aujourd'hui ?
HappyHorse-1.0 surpasse Seedance 2.0 sur T2V et I2V sans audio — mais est en retrait sur l'audio et ne dispose pas d'API stable. Voici ce que cela signifie pour les développeurs.

J’ai passé une bonne partie de mon temps à actualiser le classement Artificial Analysis Video Arena. Salut, c’est Dora ! Un modèle dont je n’avais jamais entendu parler — HappyHorse-1.0 — était apparu discrètement pendant le week-end et avait délogé Seedance 2.0 de la première place dans deux des quatre principaux classements. Personne ne semblait savoir qui l’avait créé. Artificial Analysis lui-même l’a qualifié d’entrée “pseudonyme”. Et ma timeline était partagée entre enthousiasme et confusion.
J’ai donc compilé les chiffres, retracé les chemins d’accès, et essayé de répondre à la seule question qui compte vraiment pour ceux qui construisent avec ces modèles en ce moment : lequel pouvez-vous déployer aujourd’hui ?
La réponse n’est pas aussi nette que le classement le laisse entendre.
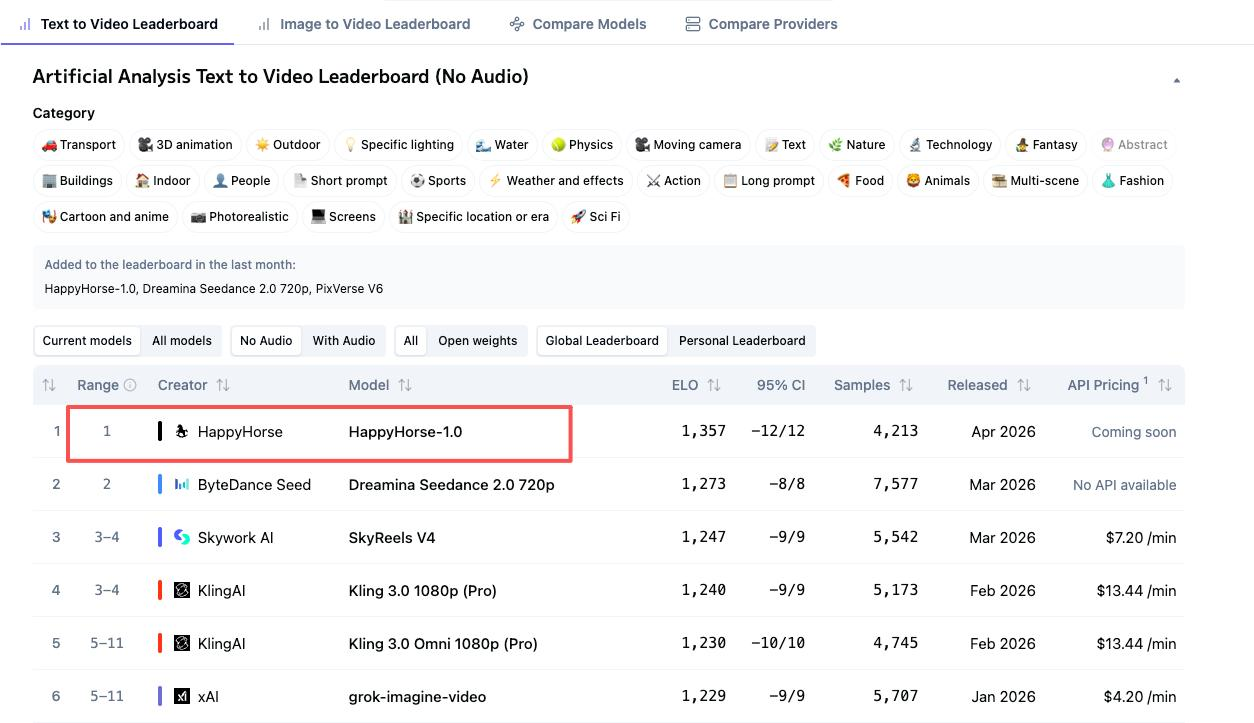
Les Quatre Chiffres du Classement Qui Comptent
HappyHorse et Seedance 2.0 occupent le sommet de quatre classements distincts d’Artificial Analysis. Mais leurs positions s’inversent selon que l’audio fait ou non partie de l’évaluation. Cette distinction importe plus que la plupart des comparaisons ne le reconnaissent.
T2V Sans Audio : HappyHorse n°1 (Elo 1333) vs Seedance 2.0 n°2 (Elo 1273)
C’est là que HappyHorse brille le plus. Un écart de 60 points Elo dans une arène de votes à l’aveugle est significatif — cela se traduit approximativement par une préférence des utilisateurs pour HappyHorse environ 59 % du temps lors de confrontations directes. Les votes capturent ici la qualité du mouvement visuel, l’adhérence aux instructions et la cohérence des scènes, sans qu’aucun audio n’influence la perception.
T2V Avec Audio : Seedance 2.0 n°1 (Elo 1219) vs HappyHorse n°2 (Elo 1205)
Dès que l’audio entre en jeu, Seedance prend la tête avec 14 points d’avance. Le Dual-Branch Diffusion Transformer de ByteDance génère vidéo et audio simultanément en une seule passe — une branche pour les images vidéo, une autre pour les formes d’onde audio, reliées par une attention croisée. Ce choix architectural porte ses fruits lorsque les effets sonores synchronisés et les dialogues font partie du jugement.
I2V Sans Audio : HappyHorse n°1 (Elo 1392) vs Seedance 2.0 n°2 (Elo 1355)
Le score Elo le plus élevé de HappyHorse dans les quatre catégories. Une avance de 37 points sur l’image-to-video sans audio suggère que le modèle excelle particulièrement à suivre la composition de l’image de référence — en préservant l’identité du sujet, le cadrage et le style visuel lors de la génération du mouvement. Pour les équipes travaillant sur l’animation de produits ou la conversion concept-en-mouvement, c’est le chiffre qui compte.
I2V Avec Audio : Seedance 2.0 n°1 (Elo 1162) vs HappyHorse n°2 (Elo 1161) — Quasi-Égalité
Un point. C’est dans la marge d’erreur raisonnable. Aucun modèle n’a de réel avantage ici. Considérez cette catégorie comme un match nul jusqu’à ce que nettement plus de votes s’accumulent.
Ce que l’Elo Mesure Réellement — et Ses Limites pour les Décisions en Production
Ces scores Elo proviennent de votes d’utilisateurs à l’aveugle lors de comparaisons côte à côte, utilisant un modèle Bradley-Terry adapté des classements d’échecs. Les utilisateurs voient deux vidéos générées anonymement à partir du même prompt et choisissent celle qu’ils préfèrent. C’est ce qui s’approche le plus d’un “contrôle de ressenti” à grande échelle.
Mais l’Elo ne mesure pas la fiabilité de l’API, la vitesse de génération, le coût par clip, la stabilité d’accès, ni si vous pouvez réellement appeler le modèle de façon programmatique. Un rang dans un classement est un signal de qualité, pas une décision de déploiement.
Tableau de Comparaison Principal
| Dimension | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| Elo T2V (sans audio) | 1333 (n°1) | 1273 (n°2) |
| Elo T2V (avec audio) | 1205 (n°2) | 1219 (n°1) |
| Elo I2V (sans audio) | 1392 (n°1) | 1355 (n°2) |
| Elo I2V (avec audio) | 1161 (n°2) | 1162 (n°1) |
| Génération audio | Présente, en retrait par rapport à Seedance | Plus forte — synchronisation native double branche |
| Fournisseur connu | Non — pseudonyme | Oui — ByteDance |
| Architecture (revendiquée) | Transformer unifié à 40 couches | Dual-Branch Diffusion Transformer |
| Poids ouverts | ”Bientôt disponible” revendiqué | Non |
| API stable | Pas d’API publique disponible | Accès grand public via Dreamina ; API officielle en pause |
| Accès aujourd’hui | Sites de démonstration uniquement | Dreamina, CapCut Pro, applications chinoises |
Là où HappyHorse Prend l’Avantage
Qualité du mouvement visuel sans audio : ce que les votes à l’aveugle capturent
Les écarts Elo sur les classements sans audio — 60 points en T2V, 37 en I2V — ne sont pas négligeables. Les utilisateurs lors de comparaisons à l’aveugle choisissent systématiquement HappyHorse pour ce que l’on décrit comme un glissement de caméra plus naturel, des mouvements corporels plus fluides et une atmosphère de scène plus forte. Si votre cas d’usage concerne des boucles de produits silencieuses, des clips sociaux montés avec une musique séparée, ou des plans B-roll qui seront mixés en post-production, c’est pertinent.
Architecture Transformer à flux unique (revendiquée) vs pipelines multi-flux
Les supports marketing de HappyHorse décrivent un Transformer auto-attentif unifié à 40 couches qui traite les tokens texte, vidéo et audio en une seule séquence — sans attention croisée entre des branches séparées. Si cela est exact, c’est architecturalement distinct de l’approche double branche de Seedance. Les 4 premières et dernières couches utiliseraient des projections spécifiques à chaque modalité, tandis que les 32 couches intermédiaires partagent les paramètres entre toutes les modalités. Je ne peux pas encore vérifier ces affirmations indépendamment. Le GitHub et le hub de modèles sont répertoriés comme “bientôt disponibles”.
Revendications audio multilingues
HappyHorse revendique la prise en charge native de sept langues — anglais, mandarin, cantonais, japonais, coréen, allemand et français — avec une synchronisation labiale à faible taux d’erreur sur les mots. Seedance 2.0 prend en charge 8+ langues pour la synchronisation labiale au niveau des phonèmes. Sur le papier, ils sont compétitifs. En pratique, je n’ai pas pu tester suffisamment la sortie multilingue de HappyHorse pour confirmer la parité.
Là où Seedance 2.0 Maintient l’Avantage
Génération audio : toujours en tête sur les deux classements avec audio
Seedance occupe la première place sur les classements T2V et I2V avec audio. Son architecture double branche — une branche générant les images vidéo, l’autre générant les formes d’onde audio, reliées par une attention croisée pour une synchronisation à la milliseconde — a été conçue spécifiquement pour cela. Lorsque votre sortie nécessite des dialogues, des sons ambiants ou un bruitage précis à l’image, le choix architectural de Seedance de traiter l’audio comme un élément de première classe pendant la génération (et non comme une étape de post-traitement) lui confère un avantage structurel.
Fournisseur connu : ByteDance, identité stable, écosystème établi
Vous savez qui a créé Seedance 2.0. L’équipe de recherche Seed de ByteDance, dirigée par Wu Yonghui (ancien Google Fellow, 17 ans chez Google dont Google Brain), a une lignée documentée allant de Pixeldance à Seedance 1.0, 1.5 Pro, et maintenant 2.0. HappyHorse ? À la date de publication, personne n’a publiquement confirmé qui l’a créé. Artificial Analysis l’a ajouté comme entrée pseudonyme. Plusieurs sites tiers sont apparus en quelques heures après ses débuts dans l’arène, mais aucun ne revendique être le développeur original.
Pour les décisions en production, la provenance compte. Vous devez savoir de qui vous dépendez pour les mises à jour du modèle, la conformité et la continuité.
Chemin d’accès : Dreamina dispose de points d’entrée publics
Seedance 2.0 est accessible aujourd’hui via la plateforme Dreamina de ByteDance à l’international, avec des abonnements payants commençant à environ 18 $/mois. L’intégration CapCut Pro a été déployée sur certains marchés fin mars 2026. Les utilisateurs chinois peuvent y accéder via Jimeng avec des abonnements à partir d’environ 69 RMB/mois (~9,60 USD).
Cela dit — l’API officielle de Seedance 2.0 reste en pause depuis mi-mars 2026 en raison de litiges de droits d’auteur signalés. L’accès grand public fonctionne. L’accès programmatique à l’API à l’échelle de la production nécessite une vérification avant de vous engager dans un pipeline autour de lui. Des fournisseurs tiers proposent Seedance v1.5 via API ; la disponibilité de l’API Seedance 2.0 via les canaux officiels doit être confirmée avant la mise en production.
L’Écart d’Accès Est le Véritable Facteur de Décision
HappyHorse : pas d’API stable, pas de poids publics, accès démo uniquement à la date de publication
Malgré les promesses d’une version open-source, le GitHub et le hub de modèles de HappyHorse sont tous deux répertoriés comme “bientôt disponibles”. Plusieurs sites de démonstration et d’encapsulation existent, mais aucun ne propose des endpoints API documentés avec des SLA, des limites de débit ou une tarification autour desquels vous pourriez construire un produit. Je n’ai pas trouvé un seul fournisseur d’API tiers proposant actuellement HappyHorse-1.0 via un endpoint stable et documenté.
Si vous évaluez pour la production, c’est le facteur le plus important. Un modèle que vous ne pouvez pas appeler de manière fiable n’est pas un modèle que vous pouvez déployer.
Seedance 2.0 : accessible via Dreamina — les détails nécessitent vérification
L’accès grand public via Dreamina est fonctionnel. La plateforme prend en charge l’ensemble des fonctionnalités, y compris le système de référence @, le montage multi-séquences et la génération audiovisuelle. Mais si votre flux de travail nécessite une intégration au niveau de l’API, le paysage est moins établi. L’API officielle BytePlus pour Seedance 2.0 est en pause depuis mars. Des fournisseurs tiers comme fal.ai et PiAPI ont proposé Seedance 1.5 ; l’accès programmatique à Seedance 2.0 et sa structure tarifaire associée doivent être confirmés directement avant de créer une dépendance en production.
Pourquoi “n°1 au classement” et “prêt pour la production” sont des questions différentes
Je reviens sans cesse à cela. L’Elo vous indique quel modèle les utilisateurs préfèrent dans une comparaison contrôlée. Il ne vous dit pas si vous pouvez en faire passer 10 000 générations le mardi suivant sans erreur 503. HappyHorse peut genuinement produire de meilleures vidéos silencieuses. Mais si vous ne pouvez pas l’appeler de manière fiable, cet avantage qualitatif reste dans l’arène, pas dans votre pipeline.
Cadre de Décision
La qualité audio est non négociable → Seedance 2.0. Il est en tête sur les deux classements avec audio et son architecture double branche génère du son synchronisé nativement. Si vos clips nécessitent des dialogues, de l’audio ambiant ou des effets sonores précis à l’image, Seedance est le choix le plus solide aujourd’hui.
La fidélité du mouvement visuel est votre priorité et vous êtes prêt à attendre → Surveillez HappyHorse. Les avances Elo sans audio sont réelles. Si les poids ouverts et l’accès API se concrétisent comme promis, HappyHorse pourrait devenir convaincant pour les flux de travail axés sur le silence. Mais “bientôt disponible” n’est pas un SLA.
Vous avez besoin d’une API en production aujourd’hui → Seedance 2.0 est le pari le plus sûr. Non pas parce qu’il est parfait — la pause de l’API officielle est une contrainte réelle — mais parce que Dreamina fournit un chemin d’accès fonctionnel avec une tarification documentée, et que des fournisseurs tiers préparent activement des endpoints Seedance 2.0. HappyHorse n’a pas encore d’infrastructure équivalente.
FAQ
HappyHorse-1.0 est-il vraiment meilleur que Seedance 2.0 ?
Cela dépend de ce que vous mesurez. HappyHorse est en tête sur la qualité visuelle dans les comparaisons sans audio (Elo 1333 vs 1273 pour T2V, 1392 vs 1355 pour I2V). Seedance est en tête lorsque l’audio fait partie de l’évaluation. Aucun modèle ne domine les quatre catégories. “Meilleur” n’a de sens que par rapport à votre cas d’usage spécifique et à l’importance que vous accordez à l’audio.
Pourquoi HappyHorse est-il en tête sans audio mais derrière avec audio ?
Probablement en raison de l’architecture. HappyHorse revendique un Transformer unifié unique traitant toutes les modalités en une seule séquence. Seedance 2.0 utilise une conception double branche spécialisée où des branches vidéo et audio séparées sont connectées par une attention croisée. Cette branche audio spécialisée semble donner à Seedance un avantage lorsque la qualité du son et la synchronisation sont jugées aux côtés des visuels.
Puis-je accéder à HappyHorse-1.0 via une API aujourd’hui ?
Pas via un endpoint stable et documenté que j’ai pu vérifier au 8 avril 2026. Plusieurs sites d’encapsulation proposent un accès de démonstration via navigateur, mais aucun ne publie de documentation API, de limites de débit ou de SLA de niveau production. Le GitHub officiel et le hub de modèles sont tous deux répertoriés comme “bientôt disponibles”.
Dans quelle mesure le classement Artificial Analysis est-il fiable pour les décisions en production ?
C’est le signal participatif le plus crédible pour la qualité vidéo perçue — votes à l’aveugle, classement basé sur l’Elo, préférences humaines réelles. Mais il mesure une seule chose : quelle sortie les utilisateurs préfèrent côte à côte. Il ne tient pas compte de la vitesse de génération, du coût, de la fiabilité, de la disponibilité de l’API ou de la stabilité d’accès. Utilisez-le comme un signal de qualité, pas comme une décision d’achat complète.
HappyHorse-1.0 bénéficiera-t-il d’améliorations audio dans les versions futures ?
Il n’existe pas de feuille de route publique. Le modèle est apparu dans l’arène il y a moins d’une semaine sous un pseudonyme. Si la version open-source “bientôt disponible” se concrétise, les contributions de la communauté pourraient améliorer la qualité audio. Mais il n’y a pas de calendrier, pas d’équipe de développement confirmée, et pas de plans v2 annoncés. Tout ce qui va au-delà de ce qui figure actuellement dans le classement est de la spéculation.
Il se passe quelque chose d’intéressant dans l’écart entre ce qu’un classement indique et ce qu’un développeur peut réellement utiliser. Les chiffres de HappyHorse sont genuinement impressionnants — mais des chiffres sans accès ne sont que des chiffres. Je continuerai à surveiller la mise en ligne de ce dépôt GitHub. En attendant, la comparaison ne porte pas vraiment sur quel modèle est le meilleur. Il s’agit de savoir quel modèle est disponible.
Essayez HappyHorse-1.0 sur WaveSpeedAI
HappyHorse-1.0 est maintenant disponible sur WaveSpeedAI :
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
