Guide de l'API GPT Image 2 pour la génération et l'édition
Un guide pratique de l'API GPT Image 2 pour les développeurs couvrant la génération, l'édition, la conception de workflows et les considérations courantes d'implémentation.

J’ai lancé une petite fonctionnalité produit la semaine dernière qui nécessitait de la génération d’images derrière un bouton. Deux jours après le début du développement, j’ai réalisé que les choix d’intégration que j’avais faits le premier jour allaient définir la quantité de douleur que j’allais porter pendant les six prochains mois. C’est la partie dont personne ne vous avertit avec l’API GPT Image 2. Le hello-world est facile. La posture en production, c’est là que ça devient intéressant.
Je m’appelle Dora. J’écris des notes de travail après avoir livré des choses, pas avant. Voici ce que j’ai appris en câblant OpenAI’s gpt-image-2 dans un vrai produit, et ce que je dirais à un autre développeur ou à une équipe d’ingénierie IA d’y réfléchir avant que la première requête soit envoyée.
Ce dont vous avez besoin avant d’utiliser l’API GPT Image 2
Accès au modèle, points de terminaison et documentation clé
GPT Image 2 a été lancé le 21 avril 2026. L’identifiant du modèle est gpt-image-2. Avant votre premier appel, vous devrez peut-être compléter la vérification de l’organisation API dans la console développeur — OpenAI conditionne la famille GPT Image à cette étape.
Vous avez trois surfaces au choix. L’API Image expose deux points de terminaison : images.generate pour le texte vers image et images.edit pour modifier des images existantes avec un prompt et un masque optionnel. La troisième surface est l’API Responses, qui expose la génération d’images comme un outil intégré pour les flux conversationnels ou multi-étapes.
Choisissez selon le besoin, pas selon la nouveauté. Si votre produit consiste à « l’utilisateur saisit un prompt, obtient une image », utilisez l’API Image. Si votre produit consiste à « l’utilisateur a une conversation en va-et-vient qui produit parfois des images », utilisez l’API Responses. Les mélanger parce que l’une semble plus sophistiquée que l’autre est un piège de maintenance.
Ce que GPT Image 2 supporte aujourd’hui
Deux choses à intégrer tôt.
Il ne supporte pas les arrière-plans transparents. Les requêtes avec background: "transparent" échoueront. Si vous avez besoin de PNG transparents, routez ces tâches vers gpt-image-1.5 et acceptez que vous mainteniez désormais deux chemins de modèle.
La fidélité d’entrée est fixe. Le paramètre input_fidelity existe sur les anciens modèles, mais gpt-image-2 traite toujours les entrées à haute fidélité. Omettez ce paramètre sinon votre requête échoue. L’implication sur les coûts : les requêtes d’édition avec des images de référence consomment plus de tokens d’entrée que vous ne l’attendiez peut-être de vos jours avec gpt-image-1.
Comment générer des images avec GPT Image 2
Structure de requête de base et choix de sortie
Une requête de génération prend un prompt, une taille, une qualité et un format de sortie. Le format par défaut est PNG ; vous pouvez demander JPEG ou WebP, et JPEG est plus rapide que PNG lorsque la latence est importante. La taille accepte des préréglages ou des dimensions personnalisées, avec la contrainte que les deux côtés doivent être des multiples de 16, le bord unique maximal est de 3840 px, le rapport d’aspect inférieur à 3:1, et le total de pixels entre 655 360 et 8 294 400.
Le paramètre n vous permet de générer plusieurs images en une seule requête. Utile lorsque vous avez besoin de variations à comparer. Moins utile lorsque vous payez par token de sortie — ce qui est le cas.
Gestion de la taille, de la qualité et des compromis de flux de travail
C’est là que la plupart des équipes brûlent de l’argent sans s’en rendre compte. GPT Image 2 est facturé par token, pas par image : entrée image à $8 par million de tokens, sortie image à $30 par million de tokens, entrée texte à $5 par million de tokens. Les entrées en cache sont moins chères. Le traitement par lots divise les tarifs standard par deux.
Ce que cela signifie en chiffres pratiques : à 1024x1024, la calculatrice d’OpenAI estime environ $0,006 pour la qualité basse, $0,053 pour la qualité moyenne, $0,211 pour la qualité haute. Les tailles rectangulaires comme 1024x1536 sont légèrement moins chères à $0,005, $0,041 et $0,165. Ce sont des estimations de sortie uniquement. Ajoutez par-dessus les tokens d’entrée et les tokens de référence d’édition.
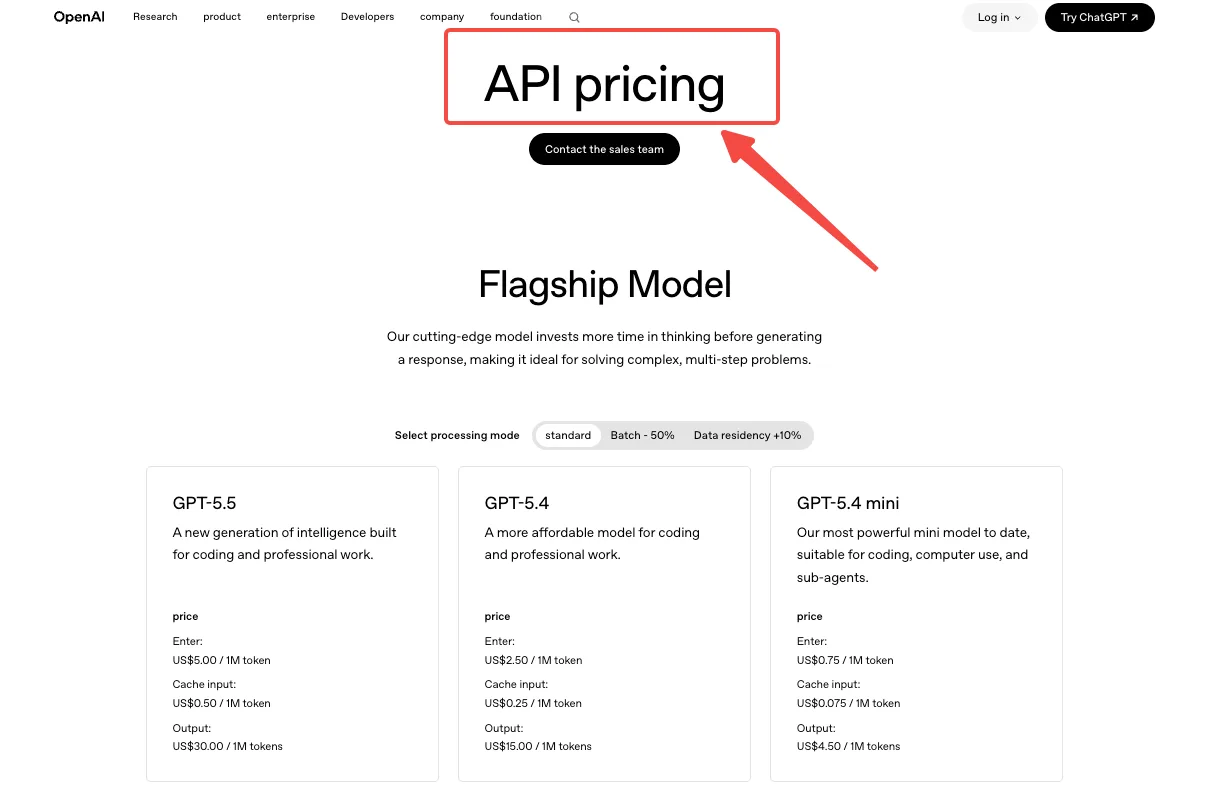
Donc la question de compromis n’est pas de savoir quelle qualité est la meilleure visuellement. C’est : à mon volume, quelle est la différence de coût entre qualité moyenne et haute, et mon utilisateur la perçoit-il réellement ? Pour une surface de vignettes, la qualité basse est souvent suffisante. Pour une image principale sur laquelle les utilisateurs vont s’attarder, la qualité haute vaut son prix. J’ai choisi la qualité moyenne comme valeur par défaut et exposé la haute qualité en option. Cette seule décision a modifié ma facture mensuelle projetée d’environ 4x.
Comment fonctionne l’édition d’images
Exigences d’entrée et scénarios d’édition courants
Le point de terminaison d’édition prend une image, un masque optionnel et un prompt décrivant le changement. Passez une image pour la modifier. Passez plusieurs images pour combiner sujets, styles ou références en une seule sortie. Le modèle gère l’inpainting et l’outpainting, et préserve les régions non masquées tout en appliquant votre prompt au reste.
Éditions courantes que j’ai validées : remplacement d’arrière-plan sur des photos de produits, suppression d’objets, transfert de style entre deux images de référence, et traduction de texte à l’intérieur d’une image. La promesse de cohérence de personnage — même personnage dans plusieurs scènes générées — fonctionne pour moi sur des sujets simples. Elle devient moins fiable à mesure que la complexité de la scène augmente.
Erreurs qui augmentent les coûts ou réduisent la cohérence
Envoyer des entrées surdimensionnées. Comme GPT Image 2 traite chaque image d’entrée à haute fidélité, une photo de référence en 4K coûte les mêmes tokens d’entrée que votre sortie soit une vignette ou une affiche. Réduisez les références à ce dont la tâche a réellement besoin.
Prompts d’édition vagues. « Améliorez-le » produit des changements imprévisibles et vous coûte souvent une nouvelle tentative. « Changez le chapeau rouge en velours bleu clair » préserve le reste de l’image et aboutit généralement en un seul essai.
n non borné. Demander n=4 pour « voir des options » semble anodin jusqu’à ce que vous réalisiez que vous venez de payer 4x pour une requête dont vous n’utiliserez qu’une seule sortie.
Traiter les éditions comme des générations pour l’estimation des coûts. Les éditions coûtent souvent plus cher que les générations de la même taille de sortie, car les images de référence ajoutent des tokens d’entrée. Intégrez cela dans votre modèle de tarification avant le lancement, pas après.
Considérations de production pour les équipes
Nouvelles tentatives, modération et garde-fous opérationnels
Trois choses qui ne sont pas optionnelles en production.
Nouvelles tentatives avec backoff exponentiel. La génération d’images peut prendre jusqu’à 2 minutes pour des prompts complexes, et vous allez atteindre des limites de débit. Les conseils d’OpenAI sont de réessayer avec un backoff exponentiel plus du jitter — le jitter est important car des tentatives synchronisées depuis une flotte heurtent le même plafond de débit au même moment.
Modération, en deux couches. Le point de terminaison de génération d’images dispose d’un paramètre moderation intégré (auto est la valeur par défaut ; low est permissif mais toujours filtré). Pour les prompts soumis par les utilisateurs, exécutez-les via le point de terminaison omni-moderation-latest gratuit avant de les envoyer à gpt-image-2 — il accepte à la fois texte et images, et arrête la plupart des requêtes violant les politiques avant que vous ne payiez pour la génération. La référence de l’API de modération contient la forme exacte de la requête.
Journalisation au bon niveau de granularité. Journalisez l’identifiant du modèle, la taille, la qualité, le nombre de tokens du prompt, le nombre de tokens de sortie, la latence, l’identifiant de requête et l’estimation du coût final par requête. Quand quelque chose se passe mal à grande échelle, ce sont les données qui vous permettent de diagnostiquer. Quand quelque chose se passe bien, ce sont les données qui vous permettent de décider si vous souhaitez aller plus loin. Épinglez à un instantané de modèle spécifique en production plutôt qu’à l’alias flottant, afin que le comportement ne dérive pas sous vos pieds. Le guide des meilleures pratiques de production couvre la rotation des clés, la surveillance et le reste de la couche opérationnelle.
Quand garder une intégration directe simple vs ajouter une couche de plateforme
C’est la question sur laquelle je me suis attardée le plus longtemps.
L’intégration directe OpenAI est la bonne réponse lorsque votre produit utilise un seul modèle d’image, que votre équipe a de l’expérience en opérations API, et que votre trafic est suffisamment prévisible pour que la gestion des limites de débit et la facturation en première partie comptent plus que la commodité.
Une couche de plateforme — et oui, je travaille sur l’une d’elles chez WaveSpeedAI — gagne sa place dans des situations différentes. Vous routez entre plusieurs modèles d’image (gpt-image-2 pour la typographie, un modèle différent pour les PNG transparents, un autre pour la vidéo). Vous avez besoin d’une tarification fixe par appel pour la prévisibilité budgétaire plutôt que de faire des calculs de tokens. Vous voulez une surface d’intégration unique qui résiste aux changements de fournisseur sans que vous réécriviez vos points d’appel.
Aucune réponse n’est universelle. Le test honnête : comptez combien de fournisseurs de modèles votre produit appelle aujourd’hui, multipliez par combien vous en appellerez dans douze mois, et demandez-vous si vous voulez maintenir autant d’intégrations vous-même.
FAQ
Quel point de terminaison les développeurs devraient-ils utiliser pour GPT Image 2 ?
Utilisez images.generate pour le texte vers image, images.edit pour modifier une image existante avec un prompt et un masque optionnel, et l’outil image de l’API Responses lorsque la génération doit s’inscrire dans une conversation multi-tours.
GPT Image 2 supporte-t-il les éditions d’images ?
Oui. Le point de terminaison images.edit accepte une ou plusieurs images de référence plus un prompt, et supporte l’inpainting masqué et l’outpainting. Toutes les images d’entrée sont automatiquement traitées à haute fidélité.
Que doivent journaliser et surveiller les équipes en production ?
Au minimum : l’identifiant de l’instantané du modèle, la taille, la qualité, les nombres de tokens d’entrée et de sortie, la latence, l’identifiant de requête, le nombre de nouvelles tentatives, le résultat de modération et le coût estimé final par requête. C’est ce qui vous permet de reconstituer tout incident et de prévoir les dépenses.
Quand une intégration API simple cesse-t-elle d’être suffisante ?
Quand vous appelez plus d’un fournisseur d’images, quand les modes de défaillance nécessitent un basculement entre fournisseurs, ou quand les finances demandent une tarification prévisible par appel plutôt qu’une variabilité basée sur les tokens. En deçà de ces seuils, l’intégration directe reste le choix le plus propre.
Comment empêcher l’injection de prompts et les sorties non sécurisées de se retrouver en production ?
Exécutez les prompts utilisateurs via le point de terminaison de modération avant la génération, définissez le paramètre moderation de l’API image sur auto, journalisez chaque requête signalée, et suivez les meilleures pratiques de sécurité d’OpenAI — y compris la révision humaine pour les surfaces à enjeux élevés et le red-teaming avant le lancement.
Conclusion
L’API GPT Image 2 n’est pas difficile à câbler. La première requête prend une après-midi. Les décisions qui comptent — les valeurs par défaut de qualité, la modélisation des coûts d’édition, la stratification de la modération, le comportement de nouvelles tentatives, l’ajout ou non d’une couche de plateforme — sont celles qui s’accumulent silencieusement pendant des mois après la livraison. Choisissez-les délibérément. Exécutez d’abord le petit pilote. Le reste suit.
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir