Godmod3 AI expliqué : le chat multi-modèles sans les restrictions
Godmod3 vous permet d'exécuter plus de 50 modèles d'IA en parallèle avec une seule clé OpenRouter — sans installation, sans serveur, sans compte. Voici ce que cela signifie en pratique.

J’ai construit un workflow autour avant de comprendre pleinement ce que c’était. C’est généralement comme ça que ça se passe.
La semaine dernière, j’avais trois onglets ouverts — Claude sur l’un, GPT-5 sur un autre, Gemini sur un troisième — en copiant-collant le même prompt dans chacun pour déterminer quel modèle gérait le mieux une comparaison technique nuancée. La friction était évidente : trois sessions de connexion, trois panneaux de paramètres, trois comptes de facturation, zéro format de sortie standardisé. Je suis Dora, qui a effectué ce type d’évaluation multi-modèles des dizaines de fois, et je tiens une note dans mon journal de travail : « le coût du changement est invisible jusqu’à ce que vous le fassiez cinquante fois par semaine. » Alors il devient très visible.
C’est le problème que godmod3.ai résout. Un seul prompt. Plusieurs modèles. Un seul gagnant noté. Voici ce que vous devez réellement savoir avant de décider si cela appartient à votre workflow.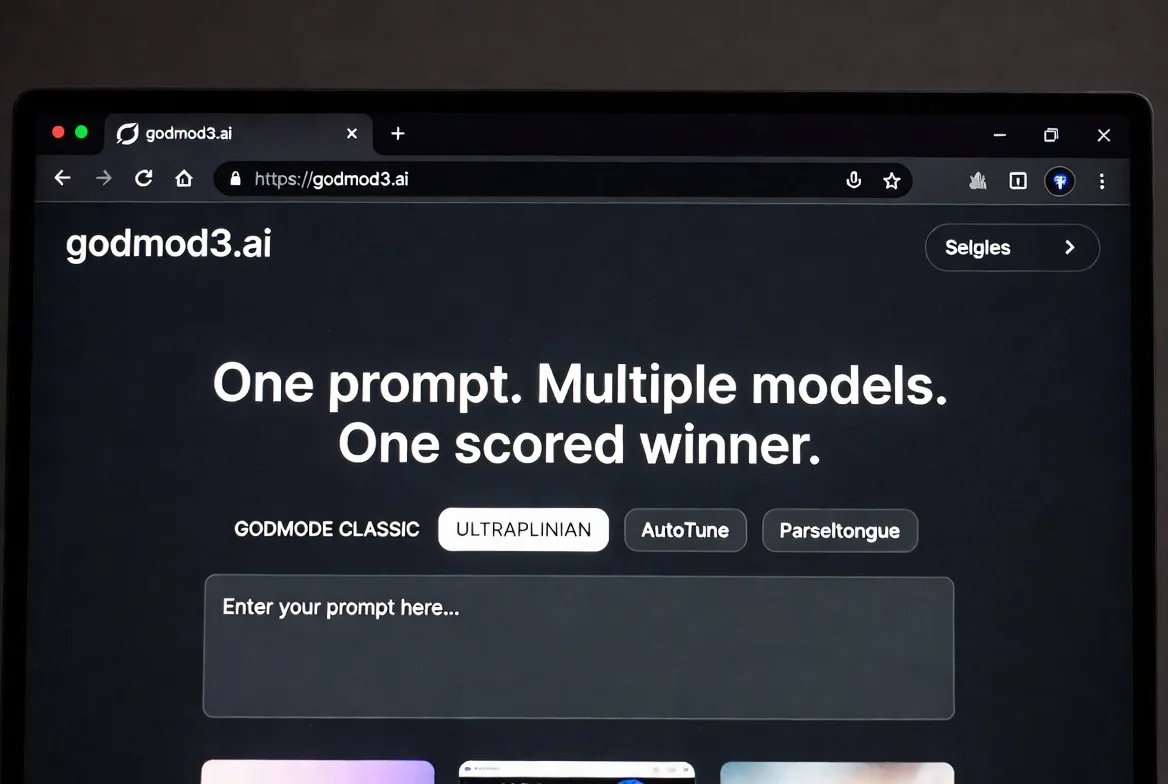
Godmod3 vs Votre Configuration AI Actuelle
Le problème du modèle unique : pourquoi passer d’un onglet à l’autre entre ChatGPT et Claude ne suffit pas
Le problème n’est pas que ChatGPT ou Claude sont mauvais. C’est qu’utiliser un modèle à la fois vous oblige à faire confiance au jugement de ce modèle sans point de comparaison. Vous tapez un prompt, obtenez une réponse, et soit vous l’acceptez soit vous la reformulez. Vous ne savez pas si un autre modèle l’aurait réussi du premier coup.
Changer d’onglet pour le découvrir est lent. Chaque plateforme a ses propres paramètres, son propre comportement de fenêtre de contexte, sa propre façon d’interpréter la même instruction. Le temps que vous ayez comparé trois sorties, vous avez passé plus de temps sur le processus que sur la tâche elle-même.
Ce que godmod3.ai vous offre : un seul prompt, plusieurs modèles, un seul gagnant
Godmod3 envoie votre prompt à plusieurs modèles simultanément et retourne les résultats côte à côte. Dans son mode ULTRAPLINIAN, il note les réponses sur une métrique composite de 100 points et fait remonter automatiquement la réponse la mieux classée. Vous ne parcourez pas cinq onglets — vous lisez le verdict.
L’interface entière est une application de navigateur monopage construite par Pliny (elder-plinius) sous licence AGPL-3.0. Aucun serveur backend requis pour la version hébergée de base. Votre clé API reste dans le localStorage de votre navigateur. Godmod3 ne stocke pas vos conversations sur aucun serveur — fermez l’onglet et elles disparaissent.
La dépendance OpenRouter expliquée simplement
Godmod3 ne se connecte pas directement à OpenAI, Anthropic ou Google. Il achemine tout via OpenRouter, une passerelle API unifiée qui donne accès à plus de 300 modèles de plusieurs fournisseurs avec une seule clé. Vous payez OpenRouter par token, pas godmod3. L’outil lui-même est gratuit. OpenRouter est à la fois la couche de facturation, le catalogue de modèles et l’infrastructure de routage.
Trois Façons d’Accéder à Godmod3
Version hébergée sur godmod3.ai — aucune installation, apportez votre clé OpenRouter
Rendez-vous sur godmod3.ai, collez votre clé API OpenRouter dans les paramètres, et commencez à envoyer des prompts. C’est tout. Pas de téléchargement, pas de Docker, pas de npm install. La version hébergée supprime entièrement la fonctionnalité optionnelle de collecte de données — c’est une interface de chat purement côté client.
Je l’utilisais dans les 60 secondes suivant l’arrivée sur la page. La friction était quasi nulle, ce qui est rare pour les outils AI open-source.
Fichier unique auto-hébergé — clonez et ouvrez index.html
L’application entière tient dans un seul fichier index.html. Clonez le dépôt GitHub, ouvrez index.html dans un navigateur, c’est fait. Ou lancez python3 -m http.server 8000 si vous voulez un serveur local. Aucune étape de compilation, aucune installation de dépendances, aucun fichier de configuration.
Cela importe si vous souhaitez inspecter exactement quel code s’exécute avant de coller une clé API. La licence AGPL-3.0 — reconnue par l’Open Source Initiative comme licence de logiciel libre — signifie que le code source est entièrement auditable.
Déploiement statique — GitHub Pages, Vercel ou Netlify en moins de 5 minutes
Comme il s’agit d’un seul fichier HTML, le déploiement sur n’importe quelle plateforme d’hébergement statique est trivial. Poussez vers un dépôt GitHub, activez GitHub Pages, et votre instance personnelle de godmod3 est en ligne à une URL que vous contrôlez. Pareil pour Vercel ou Netlify — importez le dépôt et déployez. Pas de fonctions serverless, pas de variables d’environnement (hormis votre clé API, qui reste côté client).
J’ai testé la voie GitHub Pages. Environ trois minutes du fork à l’URL en ligne.
Les Quatre Modes Expliqués
GODMODE CLASSIC — le mode course en parallèle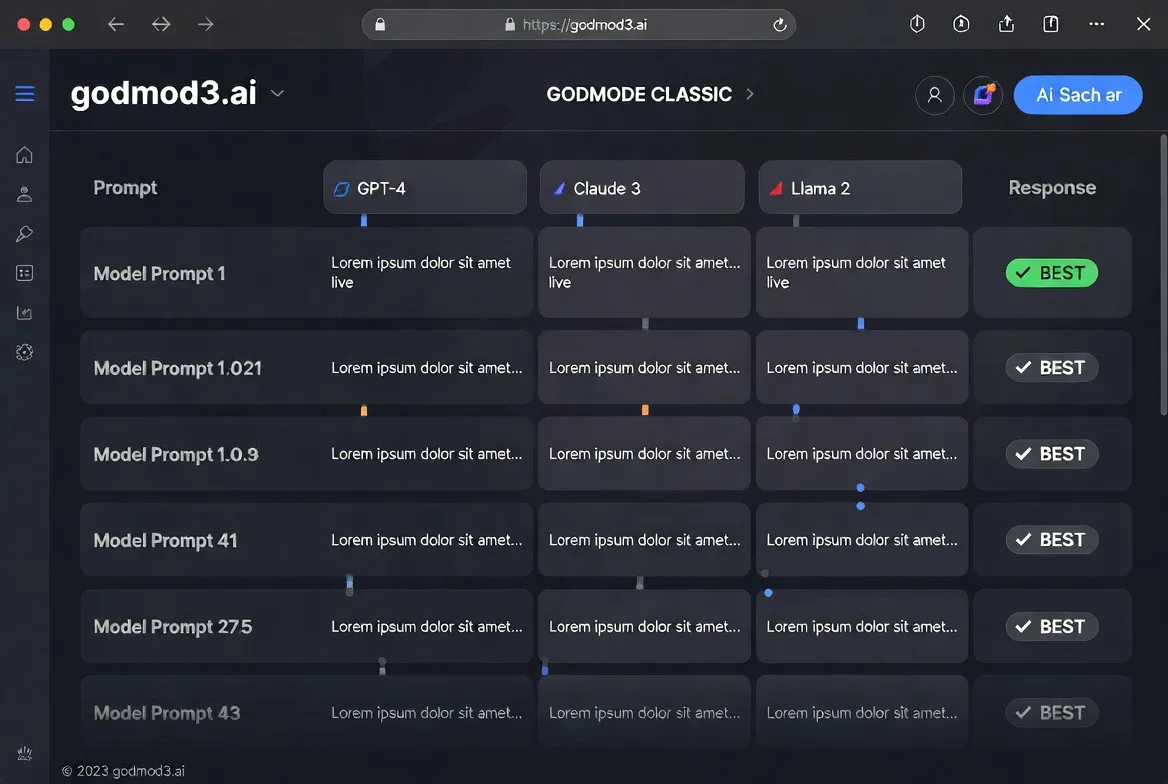
Le mode original. Cinq combinaisons modèle-prompt s’exécutent en parallèle, chacune associant un modèle spécifique à un prompt système ajusté. Les réponses s’affrontent, et l’interface fait remonter la meilleure. C’est rapide et opinioné — vous faites confiance aux configurations prédéfinies plutôt que de choisir vous-même les modèles.
Idéal pour des comparaisons rapides quand vous ne voulez pas réfléchir au réglage des paramètres. Moins utile quand vous avez besoin d’un contrôle précis des modèles.
ULTRAPLINIAN — évaluation multi-modèles approfondie pour des comparaisons sérieuses
C’est le mode qui m’a fait marquer une pause. Il peut interroger jusqu’à 51 modèles en parallèle, noter chaque réponse sur une métrique composite et les classer. Le scoring prend en compte la pertinence, la cohérence et la qualité de la réponse. Pour les ingénieurs de prompt testant comment différents modèles gèrent la même instruction, c’est là que réside la vraie valeur.
Pas bon marché, cependant. Lancer 51 modèles en parallèle signifie 51 appels API séparés, chacun facturé via OpenRouter. J’ai soumis un prompt de complexité moyenne à une configuration à 10 modèles et le coût était modeste — quelques centimes. À 51 modèles, ça s’accumule.
AutoTune — pourquoi vous n’avez plus besoin de régler manuellement la température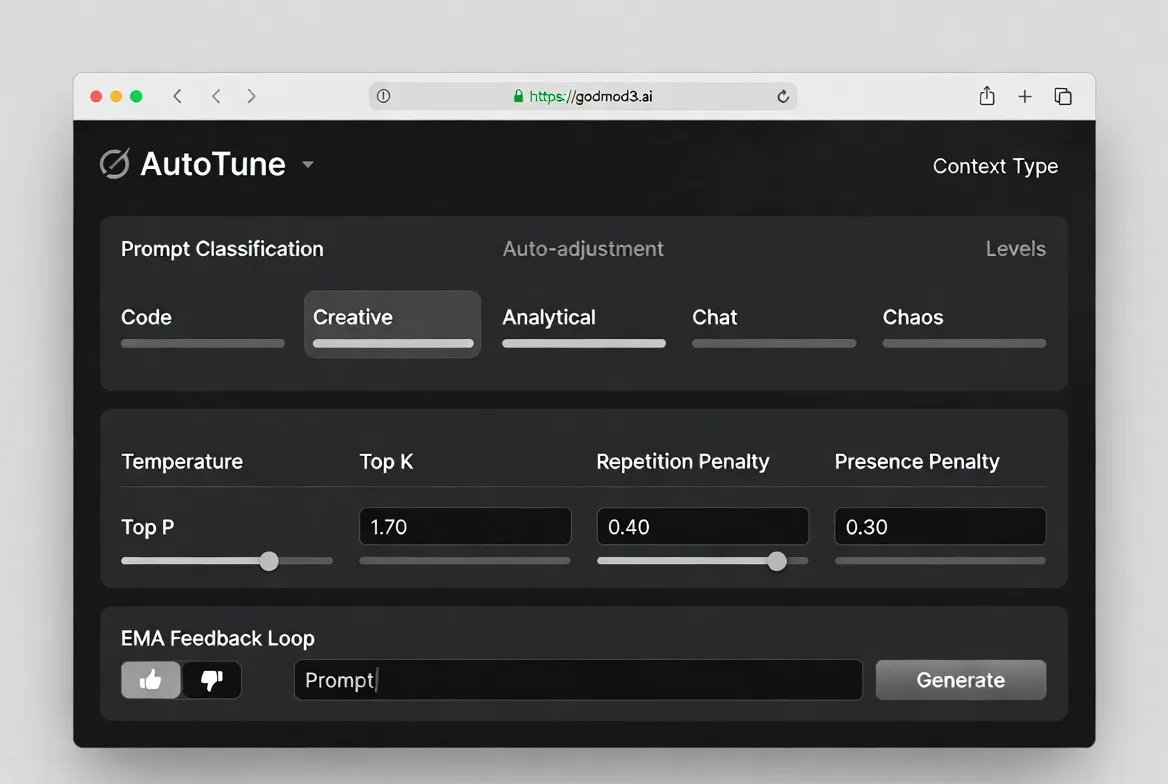
AutoTune classe votre prompt dans l’un des cinq types de contexte — code, créatif, analytique, conversation ou chaos — et ajuste automatiquement la température, top_p, top_k et les paramètres de pénalité. Il utilise une boucle de rétroaction basée sur EMA : un pouce vers le haut ou le bas sur une réponse affine la sélection future des paramètres.
Je ne suis toujours pas entièrement sûre de la différence que cela fait par rapport à régler manuellement la température à 0,7 et la laisser. Après une semaine d’utilisation, les choix de paramètres semblaient raisonnables mais pas significativement meilleurs que mes valeurs par défaut. Cette conclusion a une date d’expiration — la boucle de rétroaction a besoin de plus de données pour converger.
Parseltongue — perturbation d’entrée pour les chercheurs en sécurité (et ce à quoi ça ne sert pas)
Parseltongue est un module de recherche red-team. Il détecte les mots déclencheurs et applique des transformations au niveau des caractères — leetspeak, substitution Unicode, encodage phonétique — pour étudier comment les modèles répondent aux entrées adversariales. Le document de recherche du projet cadre cela explicitement comme un outil d’évaluation de la sécurité AI pour tester la robustesse des modèles au moment de l’inférence.
Ce n’est pas un outil de contournement de contenu. Il est conçu pour la recherche contrôlée sur la façon dont les couches de sécurité répondent à la perturbation des entrées. La distinction importe. Si votre cas d’utilisation est « je veux tromper une IA pour lui faire dire quelque chose qu’elle ne devrait pas », ce n’est pas pour ça que ce module est construit, et la documentation du projet le dit directement.
Accès aux Modèles via OpenRouter
Quels modèles sont disponibles
Via OpenRouter, godmod3 peut accéder à Claude, GPT-4o, Gemini, Grok, Mistral, Llama, DeepSeek, Qwen, et des dizaines d’autres. Le catalogue de modèles OpenRouter répertorie plus de 300 options auprès de plus de 60 fournisseurs en avril 2026. Tous ne sont pas utiles pour chaque tâche, mais la largeur signifie que vous êtes peu susceptible de rencontrer un mur « modèle non disponible ».
Réalité tarifaire : vous payez OpenRouter par token, pas godmod3
Godmod3 lui-même est gratuit. Vos coûts proviennent de la facturation par token d’OpenRouter, qui répercute les tarifs de chaque fournisseur à un niveau égal ou proche des taux d’API directs. Exécuter un prompt sur un modèle coûte pareil qu’appeler directement l’API de ce modèle. L’exécuter sur dix modèles coûte dix fois plus.
La page de tarification d’OpenRouter détaille les tarifs par token par modèle. Pas de frais mensuels, pas de dépense minimale. Vous ajoutez des crédits et ils se déplètent à l’utilisation.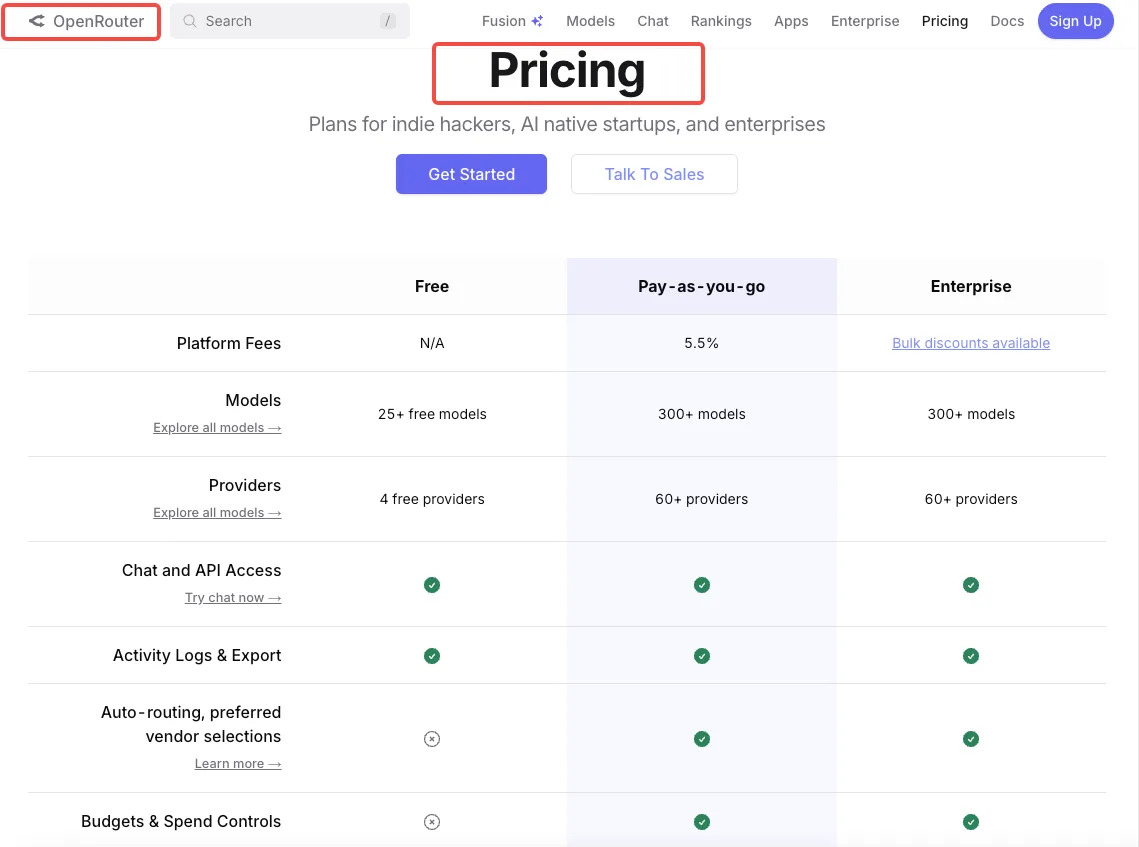
Modèles gratuits sur OpenRouter que vous pouvez utiliser avec godmod3 aujourd’hui
OpenRouter maintient une collection de modèles gratuits — actuellement environ 29 options dont DeepSeek R1, Llama 3.3 70B, Qwen3 Coder et plusieurs variantes Gemma. Les modèles gratuits ont des limites de débit (généralement 20 requêtes par minute, 200 par jour) mais ne nécessitent pas de crédits.
Pour tester si godmod3 convient à votre workflow avant d’engager de l’argent, le niveau gratuit est suffisant pour se forger une opinion.
Ce que Godmod3 n’Est Pas
Pas un backend — l’historique des chats vit uniquement dans votre navigateur
Il n’y a pas de compte, pas de synchronisation cloud, pas de stockage côté serveur. Effacez les données de votre navigateur et vos conversations disparaissent définitivement. Changez d’appareil et rien ne vous suit. Le mode navigation privée supprime tout à la fermeture de la fenêtre.
C’est une fonctionnalité de confidentialité, pas une limitation — mais cela signifie que godmod3 est un brouillon, pas une base de connaissances.
Pas un remplacement pour les API de production
Si vous construisez un produit qui appelle des LLM, vous avez besoin d’une intégration API directe avec une logique de retry, une gestion des erreurs et une gestion des limites de débit. Godmod3 est une interface de recherche et d’évaluation, pas une infrastructure de production. La propre documentation du projet est claire à ce sujet.
Pas un outil de contournement — l’objectif de Parseltongue dans la recherche en sécurité AI
Ça vaut la peine de répéter : Parseltongue existe pour étudier la robustesse des modèles dans des conditions contrôlées. Le projet se positionne dans le paysage plus large de la recherche en sécurité AI aux côtés de frameworks comme Constitutional AI et RLHF. Il fournit des outils d’évaluation au moment de l’inférence — pas des modifications au moment de l’entraînement. Le risque dual-use est reconnu dans la documentation, et les utilisateurs sont responsables de la conformité avec la loi locale.
Qui Tire le Plus de Valeur de Godmod3
Les ingénieurs de prompt qui ont besoin d’une comparaison rapide multi-modèles
Si vous testez comment un prompt fonctionne sur Claude, GPT-4o et Gemini avant de vous engager sur l’un d’eux, godmod3 compresse ce workflow de « trois onglets, trois connexions, comparaison manuelle » à « un prompt, un écran, résultats classés ». C’est la valeur fondamentale.
Les développeurs évaluant quel LLM correspond à leur cas d’usage avant de s’engager dans une API
Avant d’intégrer une API et de construire autour de ses particularités, vous voulez savoir : est-ce que ce modèle gère bien mon cas d’usage ? Exécuter les mêmes prompts de test sur 5 à 10 modèles en parallèle vous donne une matrice de comparaison en minutes, pas en jours.
Les chercheurs effectuant des études contrôlées sur le comportement des LLM
La combinaison d’AutoTune (variation de paramètres), Parseltongue (perturbation des entrées) et ULTRAPLINIAN (scoring multi-modèles) crée un pipeline d’évaluation structuré. Pour les chercheurs académiques ou industriels étudiant comment les modèles répondent dans différentes conditions, c’est une boîte à outils prête à l’emploi qui ne nécessite pas de construire une infrastructure personnalisée.
FAQ
Godmod3.ai est-il le même que G0DM0D3 sur GitHub ?
Oui. « Godmod3 » et « G0DM0D3 » désignent le même projet. La version hébergée sur godmod3.ai exécute la même base de code que le dépôt GitHub. La principale différence est que la version hébergée n’inclut pas la fonctionnalité optionnelle de collecte de données — celle-ci n’est disponible que lors de l’auto-hébergement avec le serveur API complet basé sur Docker.
Dois-je payer pour utiliser godmod3 ?
L’outil lui-même est gratuit. Vous avez besoin d’une clé API OpenRouter, et OpenRouter facture par token lors de l’utilisation de modèles payants. Vous pouvez utiliser des modèles gratuits sur OpenRouter à coût zéro, sous réserve de limites de débit. Pas d’abonnement, pas de frais de plateforme de la part de godmod3.
Ma clé API est-elle sécurisée sur godmod3.ai ?
Votre clé OpenRouter est stockée dans le localStorage de votre navigateur et envoyée directement à l’API d’OpenRouter. Elle ne touche jamais un serveur godmod3. Cela dit, vous faites confiance au code côté client pour ne pas l’exfiltrer — c’est pourquoi la base de code open-source importe. Vous pouvez l’auditer vous-même, ou vous auto-héberger pour un contrôle total.
Puis-je utiliser godmod3 sans compte OpenRouter ?
Non. OpenRouter est la couche de routage pour tout accès aux modèles. Vous avez besoin d’un compte OpenRouter et d’une clé API. La création de compte est gratuite et ne nécessite pas de carte de crédit si vous n’utilisez que des modèles gratuits.
Qu’arrive-t-il à mon historique de chat si je ferme le navigateur ?
Il reste dans localStorage jusqu’à ce que vous effaciez les données du navigateur. Mais il n’y a pas de sauvegarde, pas de synchronisation, pas de récupération. Si vous avez besoin de conserver une conversation, copiez-la manuellement avant de fermer l’onglet.
J’utilise godmod3 depuis environ dix jours maintenant. Il n’a pas remplacé mes abonnements directs à Claude ou GPT — ceux-ci comptent toujours pour les workflows conversationnels longs où la continuité du contexte importe. Mais pour la tâche spécifique « quel modèle gère le mieux ce prompt », il a réduit mon temps de comparaison de minutes à secondes.
C’est tout ce que je peux confirmer. Le reste, vous devrez le vérifier vous-même.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir