Claude Mythos vs Claude Opus 4.6 : Ce que la fuite révèle aux développeurs
Claude Mythos vs Opus 4.6 : ce que la fuite suggère sur l'écart de capacités, et si les développeurs devraient attendre ou construire maintenant.

En plein milieu d’un sprint sur une intégration Claude Code la semaine dernière, la fuite Mythos est apparue dans mon fil d’actualité. Trois messages Slack en dix minutes, toutes des variations de la même question : “Devrions-nous mettre le développement en pause ?” C’est Dora, l’enthousiaste de l’IA, qui suit cette actualité de près depuis — et je pense que la réponse est plus nuancée que le battage médiatique ne le laisse entendre.
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. Claude Opus 4.6 API → · Claude Opus 4.7 API → · Ouvrir le Playground →
Laissez-moi vous expliquer ce que dit réellement la fuite, ce que Opus 4.6 vous offre actuellement, et comment prendre une vraie décision concernant le timing.
Point de départ : Ce que Claude Opus 4.6 offre actuellement aux développeurs
Avant de plonger dans les spéculations sur Mythos, ancrons-nous sur ce qui est réellement disponible et documenté aujourd’hui.
Performances en codage et en tâches agentiques
Claude Opus 4.6 atteint 65,4 % sur Terminal-Bench 2.0 et 72,7 % sur OSWorld, ce qui en fait le modèle le plus puissant d’Anthropic disponible publiquement pour les tâches de codage et d’utilisation des ordinateurs. Ce score sur Terminal-Bench n’est pas qu’un simple trophée de benchmark — il représente une véritable capacité agentique : débogage multi-étapes, refactorisation à grande échelle, et chaînage autonome d’outils sur des workflows étendus.
Le modèle est conçu pour des agents qui opèrent sur des workflows entiers plutôt que sur des invites uniques, ce qui le rend particulièrement efficace pour les grandes bases de code, les refactorisations complexes et le débogage multi-étapes qui se déroule dans le temps. Si vous construisez des agents de codage ou des pipelines agentiques, c’est le modèle qui résout réellement les problèmes et livre du code à la qualité de production.
Ce qui compte opérationnellement : Opus 4.6 décompose les tâches complexes en sous-tâches indépendantes, exécute des outils et des sous-agents en parallèle, et identifie les blocages avec une précision réelle. C’est ce comportement qui fait la différence dans les automatisations réelles adjacentes au CI/CD, pas seulement dans les environnements de démonstration.
Disponibilité de l’API, tarification et documentation
Voici la partie qui importe pour votre calendrier de décision. Claude Opus 4.6 offre un raisonnement de pointe à 5 $ d’entrée / 25 $ de sortie par million de tokens — une réduction de 67 % par rapport à l’ère Opus 4.1 à 15 $/75 $. La documentation complète de l’API Claude est publique, versionnée et stable. Vous pouvez y accéder via claude-opus-4-6 dès aujourd’hui.
Une caractéristique remarquable de la génération 4.6 est que la fenêtre de contexte complète d’un million de tokens est incluse au tarif standard, éliminant les suppléments pour le contexte long qui s’appliquaient aux modèles précédents. Pour les équipes gérant l’ingestion de grandes bases de code ou de longs workflows de recherche, c’est une réduction de coûts significative par rapport aux générations précédentes.
Leviers d’optimisation des coûts entièrement documentés et disponibles dès maintenant :
Ce que la fuite de Claude Mythos révèle sur l’écart
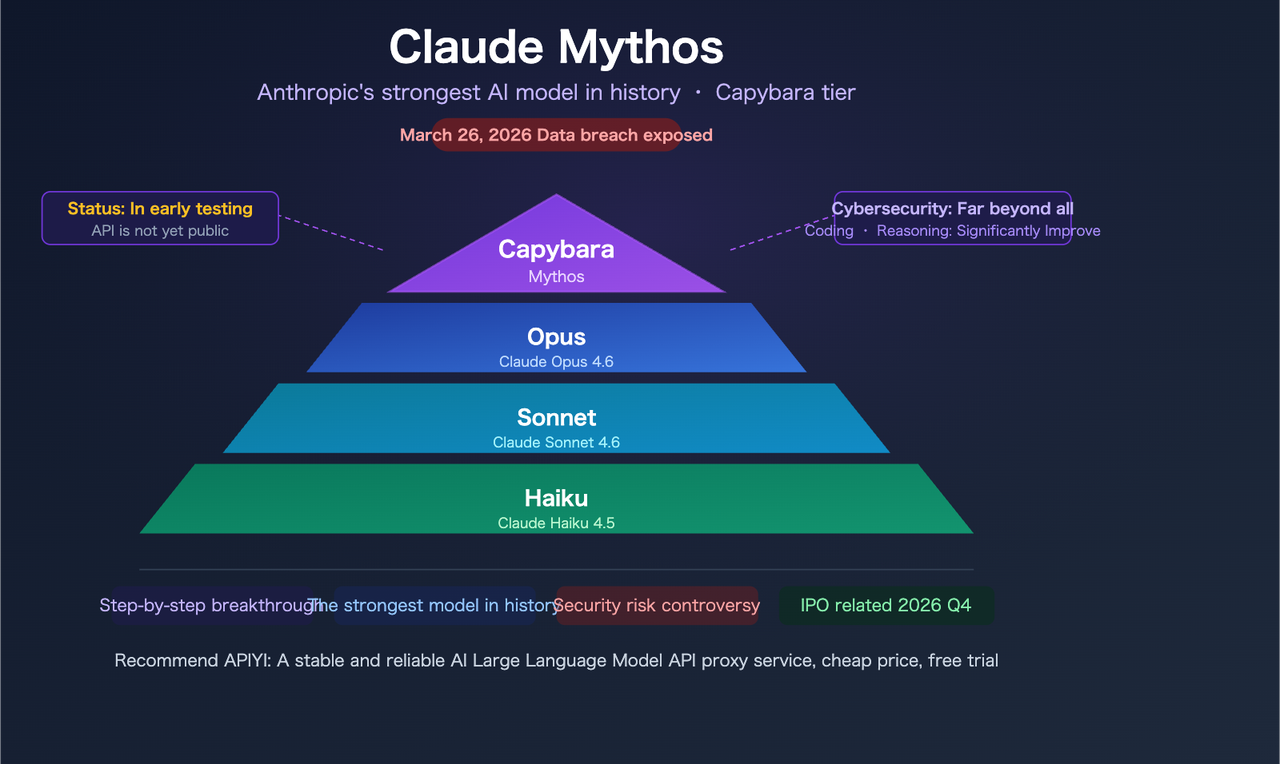
Plus tôt ce mois-ci, Fortune a rapporté qu’Anthropic avait accidentellement exposé près de 3 000 fichiers internes dans un stockage de données mal configuré et consultable publiquement. Parmi eux : un brouillon de billet de blog sur un modèle appelé Claude Mythos — également nommé en interne “Capybara.”
Mise en contexte importante avant de plonger : tout ce qui suit provient d’un brouillon non vérifié, pas d’une publication officielle. Aucun benchmark public, aucun accès API, aucune page de tarification. Anthropic a confirmé l’existence du modèle et son test en accès limité. Tout le reste n’est encore qu’un brouillon.
Codage — “Des scores dramatiquement plus élevés” décryptés
Le billet de blog divulgué indique : “Par rapport à notre meilleur modèle précédent, Claude Opus 4.6, Capybara obtient des scores dramatiquement plus élevés sur les tests de codage logiciel, de raisonnement académique et de cybersécurité, entre autres.” Ce langage est significatif dans un document interne — “dramatiquement plus élevés” n’est pas une formulation marketing atténuée, c’est une affirmation interne forte.
Ce que nous n’avons pas : des chiffres spécifiques. Aucun score précis n’a été publié au-delà du langage qualitatif dans le brouillon. Quiconque cite des chiffres de benchmark exacts pour Mythos en ce moment les invente. La lecture honnête ici est que l’évaluation interne d’Anthropic a montré un écart suffisamment large pour justifier un nouveau niveau de produit — ce qui est en soi un signal significatif, mais pas la même chose que d’avoir des données vérifiées.

Améliorations du raisonnement académique
Le brouillon divulgué regroupe le raisonnement académique avec le codage comme capacité différenciée clé. Anthropic décrit Mythos comme “un modèle à usage général avec des avancées significatives en raisonnement, codage et cybersécurité.” Pour les développeurs créant des assistants de recherche, des pipelines d’analyse de documents ou des workflows de raisonnement juridique/financier, cela mérite attention — Opus 4.6 atteint déjà 90,2 % sur BigLaw Bench, et si Mythos repousse encore cette limite, la surface des cas d’usage s’élargit considérablement.
Capacités en cybersécurité : Un nouveau territoire
C’est la dimension de capacité qui reçoit le plus de couverture médiatique — et pour cause. Le brouillon divulgué décrit le modèle comme “actuellement bien en avance sur tout autre modèle d’IA en matière de capacités cyber” et avertit qu’il “préfigure une vague prochaine de modèles capables d’exploiter des vulnérabilités d’une manière qui dépasse largement les efforts des défenseurs.”
Les documents internes divulgués avertissent que le modèle pourrait considérablement accroître les risques de cybersécurité en trouvant et exploitant rapidement des vulnérabilités logicielles, accélérant potentiellement une course aux armements cyber. C’est pourquoi le déploiement initial d’Anthropic est limité aux organisations axées sur la cyberdéfense — une décision inhabituelle qui signale une préoccupation sincère concernant les abus, pas seulement un exercice de sécurité de façade.
La tension à double usage ici est réelle. L’actuel Opus 4.6 d’Anthropic a déjà démontré une capacité à faire remonter des vulnérabilités inconnues dans des bases de code en production, une capacité que l’entreprise a reconnue comme à double usage — aidant aussi bien les hackers que les défenseurs. Mythos semble pousser cette capacité encore plus loin, ce qui explique le déploiement prudent.
C’est un nouveau niveau, pas une simple mise à jour de version — Pourquoi ça compte
Capybara au-dessus d’Opus structurellement
Le brouillon divulgué indique : “Capybara est un nouveau nom pour un nouveau niveau de modèle : plus grand et plus intelligent que nos modèles Opus — qui étaient, jusqu’à présent, nos plus puissants.” C’est structurellement différent d’Opus 4.5 → Opus 4.6. Anthropic a actuellement trois niveaux : Haiku, Sonnet, Opus. Capybara en ajouterait un quatrième au-dessus de tous.
Cela importe dans la façon dont vous architecturez vos systèmes. Si vous construisez en supposant qu’Opus est toujours le plafond, un nouveau niveau au-dessus signifie des améliorations de capacités qui ne sont pas de simples ajustements incrémentaux — elles représentent une classe différente de taux de réussite des tâches.
Tarification : Plus cher par conception
Aucune tarification officielle n’existe encore, mais le signal structurel est clair. Le brouillon de blog note que le modèle est coûteux à faire fonctionner et pas encore prêt pour une diffusion générale. Étant donné que Capybara se situe au-dessus d’Opus dans un nouveau niveau, attendez-vous à une tarification au-dessus des 5 $/25 $ actuels par million de tokens pour Opus 4.6. De combien exactement, c’est genuinement inconnu — mais planifiez qu’elle sera significativement plus élevée, pas seulement un léger incrément.
Ce n’est pas nécessairement une mauvaise nouvelle. La réduction de prix de 67 % d’Opus 4.1 à Opus 4.6 montre qu’Anthropic a appris à faire baisser les prix phares au fil des générations. Un lancement de Capybara à prix premium aujourd’hui ne signifie pas qu’il y restera dans 12 mois. Le schéma suggère que la vraie question de ROI est de savoir si le saut de capacité justifie le coût sur votre distribution de tâches spécifique.

Votre équipe devrait-elle attendre Claude Mythos ?
C’est la vraie décision pour laquelle vous êtes ici. Voici le cadre honnête.
Si vous construisez des agents de codage ou des workflows agentiques
Construisez maintenant avec Opus 4.6. L’écart de capacité peut être réel, mais attendre un modèle non publié sans calendrier public n’est pas une stratégie produit. Opus 4.6 est déjà le modèle le plus puissant disponible publiquement pour le codage agentique — Terminal-Bench 2.0 à 65,4 % est une base significative qui soutient les cas d’usage en production aujourd’hui.
Le point le plus important : les décisions architecturales que vous prenez maintenant — stratégie de mise en cache des invites, orchestration des sous-agents, schémas d’utilisation des outils — se transféreront directement à Mythos lors de son lancement. Construisez sur Opus 4.6, concevez pour un routage agnostique au modèle, et vous serez en bien meilleure position pour migrer que les équipes qui ont attendu et ont dû repartir de zéro.
Si votre priorité est l’efficacité des coûts à grande échelle
Construisez définitivement maintenant. Mythos devrait être plus cher qu’Opus 4.6, et rien n’indique un niveau budget équivalent au lancement. Si vous gérez des charges de travail à volume élevé où 5 $/25 $ par million de tokens nécessite déjà une optimisation soigneuse avec le traitement par lots et la mise en cache des invites, Mythos ne sera probablement pas votre modèle par défaut — même après qu’il soit disponible publiquement. Utilisez le temps pour optimiser vos workflows Opus 4.6 ; ces économies sont réelles et disponibles aujourd’hui.
Le calcul à faire : une équipe dépensant 2 500 $/mois sur Opus 4.6 standard peut réalistement atteindre ~250 $/mois avec le mélange de modèles, le traitement par lots et la mise en cache. Cette réduction de 90 % se cumule considérablement sur les mois que vous passeriez à attendre.
Si votre cas d’usage implique la recherche de vulnérabilités ou la sécurité
C’est le seul cas où attendre a du sens — mais vous n’aurez peut-être pas le choix. Le groupe d’accès initial pour Mythos est axé sur les chercheurs en sécurité et les défenseurs — l’objectif est de préparer les défenses avant que les capacités offensives du modèle ne deviennent largement disponibles. Si votre équipe travaille dans la recherche en sécurité offensive ou l’outillage défensif, la bonne décision est de faire une demande d’accès anticipé via les canaux d’Anthropic et de continuer à construire sur Opus 4.6 en attendant.
Pour l’outillage de sécurité d’entreprise général (analyse de code, conformité, triage des vulnérabilités), Opus 4.6 est déjà capable et entièrement disponible. Mythos étend probablement le plafond, pas le plancher.
Que faire pendant que Mythos n’est pas disponible publiquement
Concrètement, voici comment éviter les efforts gaspillés tout en restant bien positionné pour adopter Mythos efficacement :
Concevez pour un routage agnostique au modèle. Abstraire vos appels de modèle derrière une couche de routage afin que remplacer claude-opus-4-6 par une future chaîne de modèle claude-capybara-* soit un changement de configuration, pas une réécriture architecturale. C’est une bonne pratique indépendamment de Mythos — cela vous permet également de router les tâches sensibles au coût vers Sonnet 4.6 aujourd’hui.
# Exemple : wrapper de routage agnostique au modèle
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # remplacer ici lors du lancement de Mythos
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)Implémentez la mise en cache des invites maintenant. Selon la documentation de mise en cache des invites d’Anthropic, les écritures de cache entraînent un supplément de 25 % à la première utilisation, puis se lisent avec une remise de 90 % lors des utilisations suivantes. Pour les workflows agentiques avec des invites système répétées ou de grands blocs de contexte, c’est la seule optimisation de coûts avec le plus fort effet de levier disponible — et elle fonctionnera de la même façon sur Mythos.
Suivez le calendrier de publication officiel. Anthropic a confirmé les tests avec des clients en accès anticipé. Le modèle de déploiement progressif qu’Anthropic utilise — partenaires de sécurité d’abord, puis accès plus large — suggère que la disponibilité générale de l’API est probablement à des semaines ou des mois, pas à des jours.
Évaluez honnêtement votre distribution de tâches. Si 80 % de vos appels API sont de la synthèse de documents, des Q&R ou de l’extraction structurée, les avancées de Mythos en codage et cybersécurité ne feront peut-être pas une grande différence pour vous. Opus 4.6 est déjà suffisamment puissant pour ces charges de travail. Réservez votre évaluation de Mythos pour les tâches où vous atteignez actuellement le plafond d’Opus.
FAQ
Q : Puis-je utiliser Claude Mythos aujourd’hui ?
Non. Fin mars 2026, Claude Mythos (Capybara) n’est disponible que pour un petit groupe de clients en accès anticipé, spécifiquement ceux travaillant sur des applications de cyberdéfense. Il n’y a pas d’API publique, pas de documentation, et aucune date de lancement annoncée. Claude Opus 4.6, accessible via claude-opus-4-6 sur l’API Anthropic, reste le modèle le plus puissant disponible publiquement.
Q : Opus 4.6 est-il toujours le meilleur modèle Claude public ?
Oui. Claude Opus 4.6 et Sonnet 4.6 restent les modèles Claude publics les plus capables — et ils sont déjà remarquablement puissants pour le codage, le raisonnement et les tâches complexes. Opus 4.6 domine les classements publics pour le codage agentique et est entièrement documenté avec un accès API stable sur la plateforme d’Anthropic, AWS Bedrock, Google Vertex AI et Microsoft Foundry.
Q : Combien plus cher sera Claude Mythos ?
Inconnu. Le brouillon divulgué confirme que le modèle est “coûteux à faire fonctionner,” et le nouveau niveau Capybara se situant structurellement au-dessus d’Opus implique un premium de prix au-dessus des 5 $/25 $ actuels par million de tokens pour Opus 4.6. Aucune tarification officielle n’a été publiée. Le précédent historique montre qu’Anthropic réduit les prix phares au fil des générations de modèles, donc le prix de lancement initial ne reflètera peut-être pas le coût à long terme.
Articles précédents :
- Claude Sonnet 4.6 : Un modèle de travail “sans accaparer la vedette”
- GLM-5 vs DeepSeek V3 vs GPT-5 : Vitesse et coût pour les développeurs
- GLM-5 vs GLM-4.7 : Devriez-vous mettre à jour ? (Benchmarks)
- Qu’est-ce que GLM-5 ? Architecture, vitesse et accès API
- Démarrage rapide avec l’API GLM-5 sur WaveSpeed (Exemples de code)
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
