Performance de codage de Claude Mythos : Ce que cela signifie pour les workflows de développement IA
Claude Mythos obtient apparemment des scores nettement supérieurs en codage par rapport à Opus 4.6. Voici ce que cela signifie pour les développeurs qui créent des agents de codage IA en 2026.

Tout le monde s’est concentré sur l’alerte cybersécurité lorsque Fortune a publié un titre en gras brut annonçant qu’Anthropic avait accidentellement exposé près de 3 000 fichiers internes, dont un brouillon de billet de blog vantant leur modèle non encore publié. Mais en tant que quelqu’un qui passe chaque jour à construire avec Claude, ce qui a retenu mon attention n’était pas la fuite elle-même — c’était les affirmations discrètes et explosives enfouies dans ce brouillon concernant les performances en codage.
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Ouvrir le Playground →
Dans cet article, vous et moi, Dora, n’allons pas courir après le battage médiatique ou la panique sécuritaire, mais aller droit au but sur ce qui compte vraiment pour les développeurs et les équipes qui livrent de vrais produits, en exposant exactement ce que nous savons (et ce que nous ne savons pas) sur les capacités de codage de Claude Mythos / Capybara.
Ce que le brouillon divulgué dit sur les performances de codage de Claude Mythos
La formulation précise tirée du brouillon divulgué : “Comparé à notre meilleur modèle précédent, Claude Opus 4.6, Capybara obtient des scores nettement plus élevés sur les tests de codage logiciel, de raisonnement académique et de cybersécurité, entre autres.”
C’est tout ce qu’Anthropic a mis par écrit concernant les performances de codage. Aucun pourcentage SWE-bench, aucun score Terminal-Bench, aucun tableau comparatif. La formulation “nettement plus élevés” est le vrai signal — vague, mais pas sans signification.

Pour context, Opus 4.6 est actuellement en tête des modèles disponibles publiquement sur SWE-bench Verified (~80,8%), Terminal-Bench 2.0 et Humanity’s Last Exam. Le porte-parole officiel d’Anthropic a confirmé que le modèle représente “des avancées significatives en raisonnement, codage et cybersécurité.” L’entraînement est terminé, les tests d’accès anticipé sont en cours, et le codage est explicitement l’une des trois dimensions de capacité principales. Tout le reste relève de l’inférence.
Pourquoi le codage est la capacité la plus importante pour ce niveau de modèle
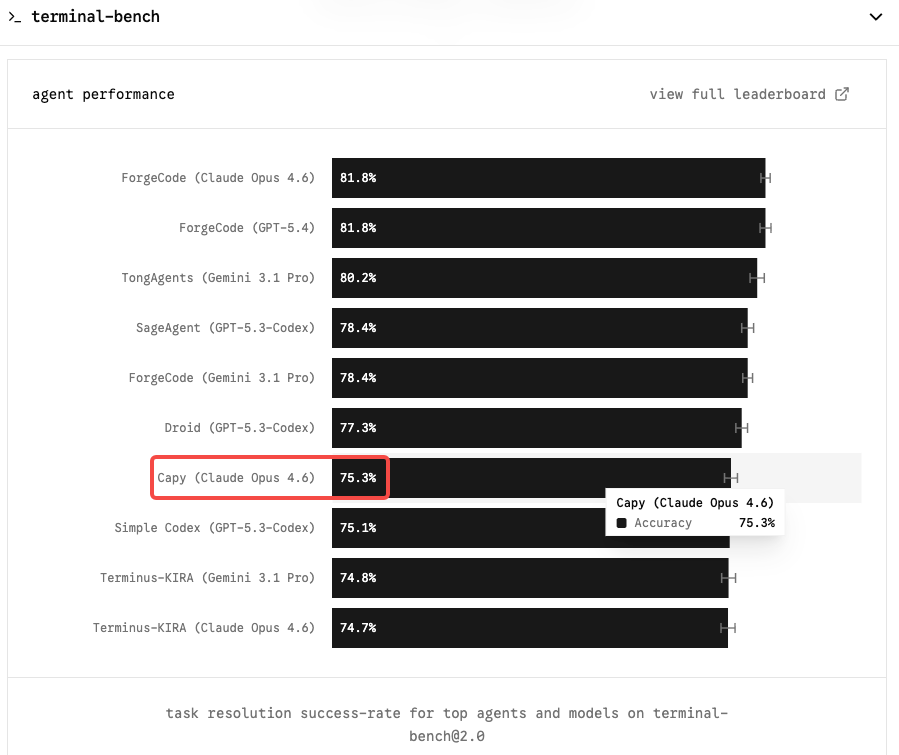
Contexte de Terminal-Bench 2.0 et scores actuels d’Opus 4.6
Terminal-Bench 2.0 est le benchmark qui compte le plus pour les workflows de codage agentique. Contrairement à SWE-bench, qui teste la résolution isolée de problèmes GitHub, Terminal-Bench évalue de vraies tâches dans un environnement terminal en bac à sable — administration système, DevOps, workflows CLI multi-étapes. C’est plus difficile, plus représentatif des usages en production, et moins susceptible d’être gonflé artificiellement par des échafaudages.
Claude Opus 4.6 détient la première place avec 65,4% sur Terminal-Bench 2.0 et 72,7% sur OSWorld. Un modèle de niveau Capybara faisant passer ce chiffre dans la plage 75–85% représenterait un vrai changement de dimension pour toute équipe gérant des agents de codage autonomes.
Sur SWE-bench Verified, le tableau est plus serré : six modèles obtiennent désormais des scores à moins de 0,8 points les uns des autres. Opus 4.6 est à 80,8% ; Gemini 3.1 Pro atteint 80,6% à 2 $/12 $ par million de tokens. Le SWE-bench brut n’est plus un différenciateur significatif. Terminal-Bench et la cohérence en contexte long sont là où Opus 4.6 justifie sa prime — et où Mythos fera probablement valoir son avantage le plus clairement.
Ce que “nettement plus élevés” signifie structurellement
Dans le brouillon, “nettement plus élevés” apparaît aux côtés de “changement de dimension” — la même formulation utilisée publiquement par le porte-parole d’Anthropic. Aucun de ces termes n’est anodin. Le saut d’Opus 4.1 à Opus 4.6 était une amélioration générationnelle au sein du même niveau. “Changement de dimension” implique quelque chose de différent en nature — davantage comme l’écart entre Sonnet et Opus que entre deux versions Opus consécutives.
Un modèle qui surpasse significativement Opus 4.6 en codage serait un outil majeur pour le développement logiciel, le débogage et les workflows agentiques. La question ouverte est de savoir quand il deviendra disponible et à quel coût. C’est le cadrage honnête. L’affirmation de performance est crédible au vu du bilan récent d’Anthropic. La validation n’est simplement pas encore là.
Implications pour les workflows de codage agentique
Tâches de code en contexte long
L’implication pratique la plus immédiate d’un modèle de niveau Capybara pour les équipes de codage n’est pas les scores de benchmark bruts — c’est ce qu’un meilleur raisonnement produit à grande échelle.
La fenêtre de contexte de 1M tokens de Claude Code est désormais en disponibilité générale pour Opus 4.6, offrant ~830K tokens utilisables après compaction — suffisant pour des monorepos entiers et des ensembles complets de documentation. Un modèle qui surpasse considérablement Opus 4.6 en codage, appliqué à cette même fenêtre, signifie une meilleure compréhension architecturale des grandes bases de code et moins d’erreurs de raisonnement sur la refactorisation multi-fichiers. La fenêtre de contexte ne change pas. La qualité du raisonnement en son sein, si.
Pour les équipes qui font de l’analyse de grande base de code aujourd’hui — le genre de travail où vous chargez plus de 50 000 lignes de source et demandez au modèle de comprendre l’image complète — c’est la voie d’amélioration pratique qui compte le plus.
Agents de débogage multi-étapes
Anthropic a livré Agent Teams comme fonctionnalité expérimentale avec la version Opus 4.6, marquant une étape significative dans les workflows agentiques. Une session agit comme chef d’équipe — elle coordonne le travail, attribue les tâches et synthétise les résultats. Les coéquipiers travaillent indépendamment, chacun dans sa propre fenêtre de contexte, et communiquent directement entre eux.
Les agents de débogage multi-étapes sont là où la valeur composée d’un meilleur modèle de base devient la plus évidente. Dans une configuration multi-agents, la qualité de planification du chef d’équipe détermine la bonne marche de toute l’opération. Un modèle plus puissant prend de meilleures décisions de décomposition des tâches, rédige des spécifications de tâches plus claires pour les sous-agents, et détecte les erreurs d’intégration plus tôt.
Le brouillon divulgué mentionnait spécifiquement le codage logiciel aux côtés de la cybersécurité comme domaines où Capybara surpasse “nettement” Opus 4.6. Si cet écart est réel et substantiel sur les tâches de style Terminal-Bench, il se traduirait directement par des agents de débogage multi-étapes plus fiables nécessitant moins d’intervention humaine pour se remettre d’hypothèses incorrectes.
Exploration autonome de base de code
C’est le cas d’usage qui m’intéresse le plus en pratique. Claude Code trace le problème dans votre base de code, identifie la cause racine et implémente un correctif. La qualité de ce traçage est une fonction de la profondeur du raisonnement, pas seulement de la taille de la fenêtre de contexte.
Dans un workflow typique de 2026, un développeur pourrait présenter une exigence de haut niveau et l’agent principal la décomposera en tâches distinctes, les coéquipiers utilisant le Model Context Protocol pour accéder aux outils externes, exécuter des tests et effectuer des audits de sécurité simultanément. Un modèle de niveau Capybara fonctionnant comme orchestrateur dans ce type de configuration rendrait l’ensemble du workflow plus autonome — signifiant moins de demandes de clarification, une meilleure décomposition initiale des tâches et une auto-correction plus fiable lorsqu’un sous-agent atteint un état inattendu.
Ce que les développeurs devraient faire maintenant pendant que Mythos n’est pas disponible
Comment évaluer Opus 4.6 pour votre cas d’usage actuel
La chose la plus utile que vous puissiez faire maintenant est d’effectuer votre propre évaluation d’Opus 4.6 — non pas par rapport aux benchmarks, mais par rapport à votre charge de travail réelle. Les benchmarks génériques comme SWE-bench testent la résolution isolée de problèmes avec un échafaudage standardisé. Votre agent de codage en production a une structure de base de code spécifique, un ensemble de tâches spécifiques et un mode d’échec spécifique. Ce sont ceux-là qui comptent.
Une évaluation de référence pratique pour un agent de codage pourrait ressembler à ceci :
# Suivi simple du taux de réussite des tâches
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Exécutez les mêmes 20-30 tâches représentatives avec Opus 4.6
# Suivez : a-t-il réussi au premier essai ? Combien de tours ?
# Quelle fraction de la fenêtre de contexte de 1M a-t-il consommée ?
# Où a-t-il échoué — erreur de raisonnement, utilisation d'outils, ou dépassement de contexte ?La raison pour laquelle cela compte : quand Mythos deviendra disponible, vous aurez une vraie référence pour évaluer si l’amélioration de capacité justifie la prime de coût pour votre workflow spécifique. “Nettement plus élevés” sur la suite de tests internes d’Anthropic peut ou non se traduire par une différence significative dans votre structure de base de code et distribution de tâches particulières.
Le “meilleur modèle” est celui qui correspond à la façon dont vous communiquez avec lui. Un modèle de niveau intermédiaire dans un excellent environnement d’exécution surpasse un modèle frontier dans un mauvais. La qualité de votre environnement — ingénierie des prompts, configuration des outils, structure CLAUDE.md — est une variable que vous pouvez améliorer maintenant. Mythos ne réparera pas une architecture d’agent mal conçue.
Décisions d’architecture qui évolueront avec un modèle plus capable
La bonne nouvelle est que les architectures agentiques bien conçues sont agnostiques au niveau de la couche de routage. Les patterns qui méritent d’être construits dès maintenant :
Séparez l’orchestration de l’exécution. Un agent orchestrateur qui décompose les tâches, attribue les fichiers et examine les sorties — soutenu par des sous-agents spécialisés pour l’implémentation — peut échanger son modèle de base avec un simple changement de paramètre. Construisez cette séparation maintenant et la mise à niveau vers Mythos deviendra une mise à jour de configuration, pas une refactorisation architecturale.
Utilisez CLAUDE.md comme contexte d’exécution, pas comme prompting spécifique à la session. Le fichier CLAUDE.md sert de “constitution” pour les agents IA au sein d’un dépôt — fournissant le contexte nécessaire sur l’architecture du projet, les standards de codage et les commandes de build qui permettent aux agents de fonctionner sans micro-management humain. Un CLAUDE.md bien structuré réduit les coûts d’exploration par tâche sur Opus 4.6 aujourd’hui et amplifiera les gains d’un modèle plus puissant demain.
Concevez pour la fenêtre de contexte de 1M tokens, pas contre elle. Les équipes qui ont déjà restructuré leur stratégie de chargement de fichiers, leur logique de découpage et leur gestion de contexte pour fonctionner dans la fenêtre de 1M seront positionnées pour tirer pleinement parti de la capacité de raisonnement de Mythos dans cette même fenêtre. Ne construisez pas de contournements pour les limites de contexte en supposant que le plafond ne montera pas.
Ce qu’il faut surveiller au lancement pour les équipes axées sur le codage
Les signaux qui comptent le plus pour les développeurs sont différents des signaux d’entreprise généraux. Pour les équipes axées sur le codage spécifiquement :
Les scores SWE-bench et Terminal-Bench au lancement. Anthropic a historiquement publié ces scores en même temps que les sorties de modèles. Si Mythos tient la promesse de “nettement plus élevés”, vous vous attendriez à ce que les scores Terminal-Bench 2.0 dépassent significativement les 65,4% d’Opus 4.6. Un saut à 75%+ validerait l’affirmation pour les workflows agentiques.
La mise à jour de la chaîne de modèle Claude Code. Vérifiez les docs Claude Code et la présentation des modèles API pour un nouvel alias de modèle. Claude Code a historiquement mis à jour son modèle par défaut dans les jours suivant la sortie d’un nouveau flagship. Si Mythos est livré à l’API publique, c’est là qu’il apparaîtra en premier pour les équipes de codage.
L’annonce de compatibilité Agent Teams. Agent Teams a été livré comme expérimental avec Opus 4.6. Que Mythos s’intègre nativement avec Agent Teams au lancement — ou nécessite une configuration séparée — déterminera la rapidité avec laquelle les équipes pourront l’intégrer dans des workflows multi-agents.
Le changelog Anthropic et la documentation de tarification. Ces deux pages sont le signal fiable le plus précoce avant toute annonce presse. Une nouvelle chaîne de modèle et une nouvelle ligne de tarification y apparaîtront en premier.
FAQ
Claude Mythos est-il disponible pour les tâches de codage maintenant ?
Non. Au début d’avril 2026, il n’existe pas d’endpoint API public pour Claude Mythos ou le niveau Capybara. Claude Mythos / Capybara n’est disponible qu’à un petit groupe de clients en accès anticipé sélectionnés par Anthropic, sans API publique, sans tarification annoncée et sans date de sortie confirmée. Claude Opus 4.6 — 80,8% sur SWE-bench Verified, 65,4% sur Terminal-Bench 2.0 — reste la meilleure option disponible publiquement.
Claude Mythos fonctionnera-t-il avec Claude Code ?
Presque certainement oui, éventuellement. L’architecture de Claude Code est agnostique au modèle ; passer à un nouveau flagship est un simple changement de paramètre. Mais cela n’est pas confirmé pour Mythos au lancement.
Dois-je attendre Mythos pour construire mon outil de codage IA ?
Non. Anthropic a déclaré qu’il doit devenir “beaucoup plus efficace avant toute sortie générale.” Construire sur Opus 4.6 maintenant signifie que votre architecture est validée en production quand Mythos arrivera. La mise à niveau sera un simple échange de chaîne de modèle. Les équipes qui attendent joueront à rattraper leur retard.
Articles précédents :
- Claude Sonnet 4.6 : Un modèle de travail “qui ne vole pas la vedette”
- GLM-5 vs DeepSeek V3 vs GPT-5 : Vitesse et coût pour les développeurs
- GLM-5 vs GLM-4.7 : Faut-il mettre à niveau ? (Benchmarks)
- Démarrage rapide de l’API GLM-5 sur WaveSpeed (exemples de code)
- Vitesse d’inférence GLM-5 sur WaveSpeed : Latence et débit
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
