Architecture de Claude Code en profondeur : Ce que révèle le code source divulgué
Le code source divulgué de Claude Code expose 512 000 lignes de TypeScript en production. Voici la décomposition complète de l'architecture — système d'outils, moteur de requêtes, modèles multi-agents et compression du contexte.

Bonjour à tous, je suis Dora. Je ne cherchais pas à tomber dans un terrier de lapin en mars 2026. Un message est apparu dans mon fil d’actualité : “Le code source de Claude Code a été divulgué via un fichier map dans leur registre npm.”
J’ai fermé l’onglet sur lequel j’étais et je n’ai pas regardé en arrière.
Ce qui a suivi a été l’un des après-midis les plus genuinement intéressants que j’aie passés à étudier comment un outil IA en production est réellement construit. Non pas à cause du drame de la fuite — ça lasse vite — mais parce que le code est une chose rare : un vrai CLI agentique commercial dominant examiné dans 512 000 lignes de détails.
Voici ce que j’ai remarqué.
Pourquoi le code source divulgué est une rare opportunité d’étude architecturale
Après la fuite de Claude Code, le code source a fait surface — exposé via un fichier .map mal configuré dans le propre package npm d’Anthropic — les développeurs ont rapidement réalisé que ce n’était pas un wrapper autour d’une API de chat. D’après l’analyse de cybersecuritynews.com sur l’incident, l’exposition comprenait environ 1 900 fichiers et plus de 512 000 lignes de TypeScript strict, avec le seul point d’entrée principal pesant 785 Ko.
La stack elle-même est déjà intéressante : Bun comme runtime (pas Node.js), React avec Ink pour le rendu de l’interface terminal, et Zod v4 pour la validation de schéma tout au long. Utiliser les patterns de composants React dans un CLI signifie gestion d’état, re-rendus, et composants UI composables dans votre terminal. C’est un choix délibéré et audacieux.
Ce qui mérite d’être étudié au-delà des mèmes : les patterns d’architecture de Claude Code ici s’appliquent à toute équipe construisant des systèmes agentiques sérieux.

Le système d’outils — 40+ modules isolés à accès contrôlé par permission
La première chose qui m’a frappée était la propreté avec laquelle le système d’outils est isolé. Chaque outil définit son propre schéma d’entrée, son niveau de permission et sa logique d’exécution — indépendamment. Il n’y a aucun état mutable partagé qui se glisse entre les outils.
BashTool et FileReadTool se trouvent dans le même registre mais ont des profils de risque fondamentalement différents. L’exécution Bash peut modifier l’état du système ; la lecture de fichiers est en lecture seule. L’architecture les traite en conséquence, plaçant chacun derrière son propre niveau de permission plutôt qu’en appliquant une politique globale. Cette séparation est énormément importante dans les systèmes agentiques en production, où un modèle de permission qui fuit entre les outils est un problème de sécurité et de fiabilité en attente de se produire.
AgentTool est le plus astucieux. Il permet au système de spawner des sous-agents comme n’importe quel autre appel d’outil — aucune couche d’orchestration spéciale requise, aucun modèle de processus séparé. Les sous-agents sont des citoyens de première classe du même registre d’outils. Cette décision de conception maintient l’architecture plate et prévisible.
La définition de l’outil de base seule couvre environ 29 000 lignes de TypeScript. Ce n’est pas du gonflement — c’est ce à quoi ressemble réellement la validation rigoureuse de schéma, l’application des permissions et la gestion des erreurs à cette échelle. La documentation officielle de Claude Code d’Anthropic confirme cette philosophie centrée sur les outils : les outils sont ce qui rend le système agentique.
Le moteur de requêtes de 46K lignes — Le vrai cerveau de Claude Code
QueryEngine.ts fait 46 000 lignes. Laissez cela s’installer un moment.
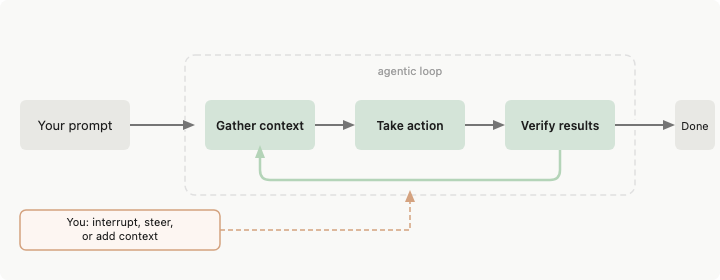
C’est le module qui gère tous les appels API LLM, le streaming, la mise en cache et l’orchestration. Dans un seul fichier. Cela pourrait sembler être un signal d’alarme — et selon les conventions de votre codebase, vous auriez raison de le questionner — mais le raisonnement est cohérent : tout ce qui touche l’API du modèle est en un seul endroit, ce qui signifie que la logique de nouvelle tentative, la gestion des limites de taux, la gestion du budget de contexte et les erreurs de streaming sont tous raisonnés ensemble.
La boucle de requête auto-réparatrice est la partie qui m’a prise par surprise. Quand le budget de contexte approche sa limite, le moteur ne plante pas ni ne demande d’aide. Il déclenche automatiquement la compression, creusant un tampon avant le plafond et générant un résumé structuré de ce qui a été discuté. Ce n’est pas un hack — c’est un comportement conçu. Pour quiconque construit des sessions d’agent de longue durée, ce pattern mérite directement d’être étudié.
Orchestration multi-agents — Coordinateur, travailleurs et le pattern de boîte aux lettres
Le système multi-agents utilise ce que le code source divulgué appelle un pattern de boîte aux lettres pour les opérations dangereuses. Voici ce que cela signifie en pratique : un agent travailleur exécutant une tâche ne peut pas approuver indépendamment une opération à haut risque. Au lieu de cela, il envoie une demande à la boîte aux lettres du coordinateur et attend. Le coordinateur évalue et approuve ou rejette.
Le mécanisme de réclamation atomique empêche deux travailleurs de traiter la même approbation simultanément — un détail subtil mais critique dans tout système avec exécution parallèle. L’espace mémoire partagé entre tous les agents signifie que l’équipe maintient un contexte cohérent sans re-récupération redondante.
Il s’agit d’un écart significatif par rapport aux conceptions multi-agents naïves où chaque agent opère avec une pleine autonomie. La division coordinateur/travailleur avec des portes d’approbation est la façon d’obtenir du parallélisme sans chaos. Les équipes construisant des couches d’orchestration pour leurs propres systèmes agentiques auraient tout intérêt à lire la documentation des patterns agentiques d’Anthropic avant de concevoir les leurs.
Compression de contexte à trois couches — Ingénierie pour les sessions longues
C’est probablement la pièce d’ingénierie la plus directement utile de l’ensemble du codebase pour quiconque construit des applications IA en production.
Claude Code utilise trois stratégies de compression distinctes, chacune déclenchée à un point différent :
MicroCompact édite le contenu mis en cache localement, sans aucun appel API. Les anciennes sorties d’outils sont coupées directement. Rapide, bon marché, transparent.
AutoCompact se déclenche quand la conversation approche le plafond de la fenêtre de contexte. Il réserve un tampon de 13 000 tokens, puis génère jusqu’à un résumé structuré de 20 000 tokens de la session. Il y a un disjoncteur intégré — après trois échecs de compression consécutifs, il arrête les nouvelles tentatives. Pas de boucles infinies.
Full Compact compresse toute la conversation, puis ré-injecte les fichiers récemment accédés (limités à 5 000 tokens par fichier), les plans actifs et les schémas de compétences pertinents. Après compression, le budget de travail se réinitialise à 50 000 tokens.
Ce qui est notable, c’est ce que cette architecture implique pour les outils qui sautent complètement la compression. Les outils agentiques qui ne gèrent pas le budget de contexte échoueront simplement à grande échelle — se dégradant silencieusement ou atteignant des erreurs dures. L’approche à trois couches est un rare exemple de conception pour la longévité de session dès le départ, et non de l’ajouter plus tard comme une rustine.
Les feature flags comme architecture — 108 modules qui n’existent pas en production
L’une des découvertes moins discutées du code source divulgué : 108 modules à accès contrôlé par feature flag, supprimés des builds externes via l’élimination du code mort à la compilation de Bun.
KAIROS, VOICE_MODE, DAEMON — ceux-ci n’existent pas dans la version que vous installez. Le code est là dans le source, mais Bun l’élimine à la compilation en fonction de la configuration des feature flags. Le bundle de production est livré proprement. C’est ainsi que vous itérez sur de nouvelles capacités sans toucher à ce qui est déjà entre les mains des utilisateurs.
L’ironie est bien documentée : le Mode Undercover, un sous-système spécifiquement conçu pour empêcher les noms de code internes d’apparaître dans les commits git ou les sorties, était présent dans le code source divulgué. Le système conçu pour empêcher les fuites n’a pas pu empêcher la fuite elle-même. Pas un échec de sécurité catastrophique, mais un exemple instructif sur l’endroit où le risque s’accumule réellement dans les pipelines de livraison logicielle.
La télémétrie intégrée dans la boucle principale
Deux signaux de télémétrie dans le code source divulgué auxquels je continue à penser :
Une métrique de frustration suit la fréquence des jurons comme signal UX. Si les utilisateurs insultent l’outil, quelque chose se dégrade — un indicateur avancé, pas retardé.
Un compteur “continue” suit la fréquence à laquelle les utilisateurs tapent le mot “continue” en milieu de session. Pour un CLI agentique, c’est un proxy pour les blocages — des moments où l’agent a perdu son élan et l’humain a dû le relancer.
Aucune n’est une métrique de vanité. Toutes deux révèlent des modes d’échec spécifiques que les analyses standard rateraient. Si vous construisez un produit IA avec des sessions d’interaction prolongées, instrumenter le comportement de l’agent de cette façon vaut le temps d’ingénierie.
Ce que cela dit aux constructeurs sur les décisions de stack
La conclusion honnête de l’étude de cette architecture de Claude Code : construire un CLI agentique en production à partir de zéro est un engagement d’ingénierie substantiel. Le système d’outils, le moteur de requêtes, l’orchestration multi-agents, la compression de contexte et la télémétrie représentent ensemble des années d’itération, pas des mois.
Ce n’est pas un argument contre la construction. C’est un argument pour être clair sur ce que vous prenez en charge. Les patterns comme le système d’approbation par boîte aux lettres et la compression à trois couches sont exportables — vous n’avez pas besoin de 512 000 lignes pour implémenter les idées fondamentales.
Là où le calcul build-vs-buy change, c’est dans l’accès et l’agrégation des modèles. L’architecture suppose un accès direct à un seul fournisseur de modèles. Les équipes travaillant avec plusieurs fournisseurs de modèles, ou construisant des produits qui doivent rester agnostiques en termes de modèle, font face à un ensemble de compromis entièrement différent.
Les patterns ici valent la peine d’être empruntés. La complexité vaut la peine d’être comprise avant de s’engager à la répliquer.

FAQ
En quoi le système d’outils de Claude Code diffère-t-il de l’appel de fonction standard ?
L’appel de fonction standard traite les outils comme une liste plate. Claude Code ajoute des portes de permission par outil, des contextes d’exécution isolés et une validation de schéma à chaque limite — empêchant la fuite d’état entre les outils et appliquant l’accès au moindre privilège, ce qui importe quand BashTool peut modifier l’état du système.
Qu’est-ce que le pattern de boîte aux lettres et quand les constructeurs devraient-ils l’utiliser ?
Il achemine les opérations dangereuses des agents travailleurs vers un coordinateur pour approbation, plutôt que d’exécuter de manière autonome. Utilisez-le chaque fois que vous avez une exécution d’agent parallèle et que vous avez besoin d’un humain dans la boucle ou d’un mécanisme d’approbation hiérarchique pour les actions à haut risque. Coût en débit, gain en sécurité.
Comment Claude Code gère-t-il les limites de fenêtre de contexte à grande échelle ?
Compression à trois couches : MicroCompact (éditions locales, pas de coût API), AutoCompact (déclenché près des limites, génère un résumé structuré avec tampon de tokens réservé), et Full Compact (compression complète de la conversation avec ré-injection sélective de fichiers). Conçu pour les longues sessions sans intervention manuelle.
Que sont les feature flags à la compilation et pourquoi les outils IA en production les utilisent-ils ?
Ils permettent au code de fonctionnalités non publiées d’exister dans le source sans apparaître dans les builds de production. Bun élimine le code désactivé par flag à la compilation, de sorte que les utilisateurs externes ne rencontrent jamais des fonctionnalités qui ne sont pas prêtes — séparant la livraison de la préparation.
Est-il légal d’étudier et de référencer le code source divulgué pour s’inspirer de l’architecture ?
Cela mérite d’être traité avec précaution. Le code source divulgué est la propriété intellectuelle d’Anthropic. Étudier les patterns architecturaux à des fins éducatives se situe dans un territoire différent de celui de copier du code directement. La documentation officielle d’Anthropic reste la référence appropriée pour tout ce que vous construiriez au-dessus de leurs systèmes. En cas de doute, consultez votre propre conseiller juridique.

Ce à quoi je reviens sans cesse, c’est combien de cette architecture concerne la gestion des échecs avec grâce. Les disjoncteurs sur la compression, le pattern de boîte aux lettres pour les opérations dangereuses, l’isolation des permissions entre les outils — ce ne sont pas des conceptions optimistes. Elles sont construites par des personnes qui ont regardé les choses mal tourner et ont décidé de les ingénier autour.
C’est un type de maturité différent de la vélocité des fonctionnalités.
Voilà, le partage d’aujourd’hui est terminé. À la prochaine fois.
Articles précédents :
- Comparer GPT-5, DeepSeek et d’autres modèles en termes de performances réelles et de coûts
- Comprendre la mise en cache de contexte de DeepSeek V4 et comment elle améliore l’efficacité des sessions longues
- En savoir plus sur les limites de taux de DeepSeek V4 et les contraintes de mise à l’échelle pour les systèmes en production
- Explorer la tarification de DeepSeek V4 et le coût par million de tokens pour les applications à grande échelle
- Voir combien de VRAM GPU DeepSeek V4 nécessite pour les déploiements réels
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
