Z-Image-Turbo LoRA sur WaveSpeed : Appliquez des styles personnalisés (jusqu'à 3 LoRAs)
Utilisez Z-Image-Turbo LoRA pour appliquer des styles personnalisés, des personnages et des identités de marque. Combinez jusqu'à 3 LoRAs, 0,01 $/image. Inclut un guide d'entraînement (1,25 $/1 000 étapes).

Salut, je m’appelle Dora. Est-ce que toi aussi, comme moi, tu en avais assez que tes maquettes s’écartent de l’identité visuelle — un bleu qui tirait vers le turquoise, un logo qui s’adoucissait sur les bords, une photo produit qui semblait… presque juste ? « Presque » convient pour les brouillons, mais ça génère du bruit. Alors la semaine dernière, j’ai testé LoRA avec Z-Image-Turbo sur WaveSpeed. Pas pour courir après la nouveauté, mais pour voir si je pouvais transformer « c’est assez bien » en « allez, on envoie » sans avoir à surveiller chaque prompt.
Voici mes notes : ce qui a fonctionné, ce qui a coincé, et comment j’ai configuré tout ça pour que ça reste discret une fois bien réglé.
Qu’est-ce que LoRA ?
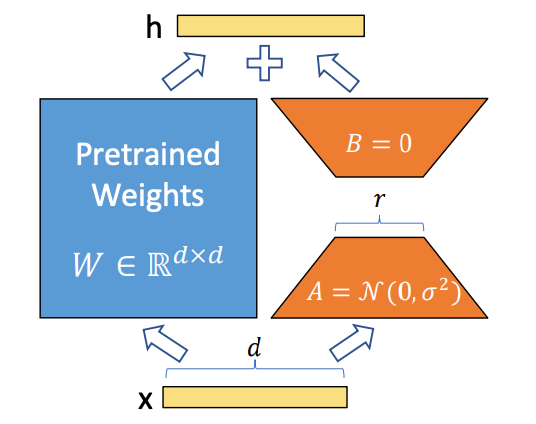 LoRA (Low-Rank Adaptation) est une petite couche ciblée qui oriente un grand modèle vers un style, un personnage ou une esthétique spécifique, sans avoir à réentraîner le tout. Imagine un filtre subtil qu’on peut ajouter ou retirer. Le modèle de base conserve ses compétences générales : le LoRA lui enseigne une préférence.
LoRA (Low-Rank Adaptation) est une petite couche ciblée qui oriente un grand modèle vers un style, un personnage ou une esthétique spécifique, sans avoir à réentraîner le tout. Imagine un filtre subtil qu’on peut ajouter ou retirer. Le modèle de base conserve ses compétences générales : le LoRA lui enseigne une préférence.
En pratique, les fichiers LoRA sont compacts, rapides à entraîner et peu coûteux à échanger. Ce dernier point compte dans les workflows. Je ne veux pas un checkpoint de modèle séparé pour chaque palette de marque ou personnage. Je veux un moteur rapide (Z-Image-Turbo) et quelques réglages interchangeables.
Pourquoi LoRA pour Z-Image-Turbo ?
 Z-Image-Turbo sur WaveSpeed est optimisé pour la vitesse. Parfait pour itérer, mais la vitesse seule ne résout pas le problème de « style cohérent ». LoRA comble ce manque. Je peux :
Z-Image-Turbo sur WaveSpeed est optimisé pour la vitesse. Parfait pour itérer, mais la vitesse seule ne résout pas le problème de « style cohérent ». LoRA comble ce manque. Je peux :
- garder le modèle de base réactif,
- attacher un LoRA prêt à l’emploi pour un look ou un personnage,
- ou entraîner un tout petit LoRA personnalisé pour mes propres assets.
Ce qui m’a surprise, c’est le contrôle offert par le paramètre de scale. Un scale faible (0,3–0,6) préservait les forces du modèle de base. Un scale plus élevé (0,8–1,0) poussait davantage vers le style appris — parfois trop fort. J’ai commencé bas, puis j’ai monté jusqu’à ce que le résultat me convienne. Cette simple habitude m’a réduit les re-rendus d’environ un tiers sur la semaine.
Utiliser des LoRAs prêts à l’emploi
J’ai d’abord testé des LoRAs prêts à l’emploi, car je ne voulais pas entraîner quoi que ce soit avant de connaître les limites. WaveSpeed traite LoRA comme un plug-in : tu pointes vers un fichier, tu définis un scale, c’est parti.
Trouver des LoRAs compatibles
La compatibilité se résume au format et à la famille du modèle de base. Si un LoRA a été entraîné sur un backbone de diffusion similaire (et noté comme compatible avec Z-Image-Turbo ou sa lignée), il s’est généralement bien comporté. J’ai gardé une courte checklist :
- même famille de modèle de base, ou famille adjacente,
- notes de version si disponibles (date + tag du modèle),
- une galerie de prévisualisation qui montre de la variété, pas seulement des résultats triés sur le volet.
Quand un LoRA semblait « trop parfait », je supposais un surapprentissage. Dans mes tests, ceux-là tendaient à s’effondrer sur des prompts en dehors d’un registre étroit. Les meilleurs sets tenaient la route quand je changeais l’éclairage ou les termes de cadrage.
Paramètres API : path + scale
 L’API de WaveSpeed utilise une structure simple par LoRA : un path (où se trouve le fichier LoRA) et un scale (l’intensité d’application). Le path peut être un asset hébergé sur WaveSpeed ou une URL signée que tu contrôles. Le scale est un flottant. Je me suis surtout situé entre 0,35 et 0,7. En dessous de 0,3, je ne percevais souvent aucun effet ; au-dessus de 0,8, la composition se trouvait parfois complètement écrasée.
L’API de WaveSpeed utilise une structure simple par LoRA : un path (où se trouve le fichier LoRA) et un scale (l’intensité d’application). Le path peut être un asset hébergé sur WaveSpeed ou une URL signée que tu contrôles. Le scale est un flottant. Je me suis surtout situé entre 0,35 et 0,7. En dessous de 0,3, je ne percevais souvent aucun effet ; au-dessus de 0,8, la composition se trouvait parfois complètement écrasée.
Une petite remarque tirée de mes runs réels : si ton path est erroné ou que l’asset est privé sans le bon token, tu n’obtiendras pas toujours une erreur explicite — tu auras simplement des images qui ressemblent au modèle de base. Quand quelque chose me semblait suspicieusement générique, je revérifiais le path.
Empiler plusieurs LoRAs (jusqu’à 3)
Tu peux empiler jusqu’à trois LoRAs. J’en ai essayé un pour le traitement colorimétrique, un pour une texture de marque, et un pour les traits d’un personnage. Ça a fonctionné, mais seulement après avoir équilibré leurs scales. Si deux LoRAs entrent en conflit (disons, l’un insiste sur un grain de film doux pendant que l’autre ajoute un éclat produit net), l’image paraît indécise. Ma règle :
- commencer chacun à 0,3,
- identifier le LoRA d’ancrage (le look non négociable),
- le monter progressivement,
- ajuster les autres par petites touches jusqu’à ce qu’ils se complètent plutôt qu’ils ne se concurrencent.
L’empilement m’a fait gagner du temps quand j’avais besoin à la fois de l’ambiance de marque et d’un personnage récurrent. Ça ne m’en a pas fait gagner quand j’ai essayé de forcer trois styles lourds à la fois. Ça m’a juste ramenée au tâtonnement.
Implémentation API
Voici comment j’ai câblé tout ça dans un petit script. J’ai utilisé des prompts que j’utilise réellement en production : des maquettes produit avec des variations d’arrière-plan, plus quelques shots de personnages pour la documentation interne.
Structure des paramètres LoRA
Le corps de la requête inclut un tableau loras. Chaque élément :
- path : string (chemin d’asset WaveSpeed ou URL signée)
- scale : float (0,0–1,0 : je recommande 0,3–0,7 pour commencer)
Les autres paramètres de Z-Image-Turbo (prompt, negative_prompt, seed, steps, width/height) fonctionnent comme d’habitude. Les seeds m’ont aidée à comparer les changements de scale dans des conditions identiques.
Exemple de code Python
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/v1/z-image-turbo/generate"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# Expect base64 images or URLs depending on your account settings
print(result.get("images", []))Dans mes runs, 16 steps avec Z-Image-Turbo suffisaient pour une qualité de prévisualisation. Pour les images finales, je montais à 22–24 steps. Cela ajoutait environ 0,3–0,6 secondes par image sur mon compte, ce qui était acceptable.
Équilibrer les scales LoRA
J’itérais ainsi :
- fixer le seed,
- mettre tous les LoRAs à 0,3,
- choisir le LoRA d’ancrage et le monter de 0,1 jusqu’à obtenir le bon résultat,
- ajuster les autres par paliers de 0,05–0,1.
Garder le seed fixe pendant le réglage des scales m’a permis de voir l’effet directement. Une fois l’équilibre trouvé, j’ai libéré le seed pour introduire de la variation. Ça ne m’a pas fait gagner du temps au début — j’ai passé 15 à 20 minutes juste pour m’y habituer. Mais dès le troisième jour, j’ai remarqué que j’avais arrêté de retoucher les prompts. Les scales portaient le style, et je me concentrais sur la composition et les textes à la place.
Entraîner des LoRAs personnalisés
Après les LoRAs prêts à l’emploi, j’en ai entraîné un petit pour la forme d’une bouteille client et le style de son étiquette. Je l’ai fait pour réduire les allers-retours causés par la dérive constante de l’angle du goulot et du brillant de l’étiquette.
Préparer les données d’entraînement (upload ZIP)
J’ai rassemblé 18 images, nettoyé les arrière-plans et maintenu les métadonnées cohérentes. Je les ai zippées — dossier simple, noms de fichiers en minuscules, sans espaces — et uploadées. J’ai ajouté 3 à 4 légendes par image quand le texte de l’étiquette importait. Quand ce n’était pas le cas, j’ai gardé les légendes minimales. Plus de légendes aidaient l’étiquette à rester lisible.
Une petite friction : les images presque identiques n’apportaient rien. J’ai supprimé les quasi-doublons et observé moins de surapprentissage.
Paramètres d’entraînement
J’ai gardé ça léger :
- résolution : crops carrés de 768,
- batch size : 1,
- learning rate : valeur par défaut conservative,
- steps d’entraînement : 3 000–6 000 pour le style + la forme,
- network rank (r) : modéré — trop élevé rendait le LoRA « trop envahissant » à mon goût.
Quand j’ai poussé au-delà de ~8 000 steps, il a commencé à imposer la bouteille dans des prompts où je ne la demandais pas. Pas idéal. Moins de steps plus un dataset plus propre l’ont emporté.
Tarification : 1,25 $ pour 1 000 steps
 Mes deux runs (3 500 et 5 000 steps) ont coûté 10,63 $ au total, à 1,25 $ pour 1 000 steps. C’est raisonnable si le LoRA s’amortit sur quelques mois.
Mes deux runs (3 500 et 5 000 steps) ont coûté 10,63 $ au total, à 1,25 $ pour 1 000 steps. C’est raisonnable si le LoRA s’amortit sur quelques mois.
Budget d’entraînement type
Ce que je budgéterais désormais :
- LoRA de style uniquement : 2 000–4 000 steps (2,50 $–5,00 $),
- personnage avec expressions : 5 000–8 000 steps (6,25 $–10,00 $),
- forme produit + détails d’étiquette : 3 000–6 000 steps (3,75 $–7,50 $).
Je ferais d’abord un run plus court, je vérifierais les résultats, puis je compléterais si c’est prometteur. Deux runs courts valent mieux qu’une longue session de surapprentissage.
Cas d’usage
Voici les situations où LoRA sur Z-Image-Turbo m’a aidée à livrer plus vite — pas tous les jours, mais de manière fiable quand la tâche s’y prêtait.

Cohérence du style de marque
Si tu en as assez de retaper les indications de marque dans chaque prompt, un LoRA de style doux à 0,4–0,6 maintient couleur, contraste et texture dans les clous. Je l’ai utilisé pour des variantes réseaux sociaux et des bannières web. Ça ne les rendait pas brillants — ça les rendait cohérents. C’est tout l’intérêt. J’ai économisé environ 5 à 7 minutes par livrable en évitant le deuxième round de « corrige l’ambiance ».
LoRAs de personnages
Pour la documentation interne et une mascotte légère qui apparaît dans les écrans d’onboarding, un LoRA de personnage maintenait les traits stables sous différents angles. L’empiler avec un traitement colorimétrique doux fonctionnait, mais seulement après avoir réduit le scale du personnage à 0,35. Plus haut, il écrasait l’éclairage. Une fois réglé, ça a supprimé une charge mentale étrange : je ne m’inquiétais plus de savoir si le visage allait dériver.
Esthétiques spécifiques aux produits
Le LoRA personnalisé de la bouteille a réduit la déformation des étiquettes et préservé la géométrie du goulot sur les gros plans. Ce n’était pas parfait — les reflets serrés demandaient encore quelques essais — mais ça a réduit le nombre de rendus inutilisables. La victoire discrète, c’était la prévisibilité. Quand je tapais « angle trois quarts sur lin », je l’obtenais, sans variante surprise.
À qui ça plaira : aux gens qui savent déjà ce qu’ils veulent et en ont assez de se battre avec le modèle. À qui ça ne plaira pas : ceux qui explorent de nouveaux styles audacieux à chaque fois. LoRA est un stabilisateur. Il brille quand tu valorises moins de surprises plutôt que plus de feux d’artifice.
Articles associés

Claude Fable 5 vient de sortir : 80,3 % sur SWE-Bench Pro, prix 2× Opus 4.8, gratuit jusqu'au 22 juin

Comment choisir une API de médias IA pour les applications Codex (2026)

API Hunyuan 3D : Ce que les développeurs doivent savoir

Hunyuan 3D vs Hyper3D vs Pixal3D

Créer des applications vidéo IA avec des agents de codage
