DeepSeek V4 Context Caching : Réduisez les coûts de 90 % sur les prompts répétés
La tarification des hits de cache de DeepSeek est 90 % moins chère. Apprenez à structurer vos prompts pour une utilisation maximale du cache.

Salut, je m’appelle Dora. Une petite chose m’a fait trébucher la semaine dernière : j’ai relancé le même prompt trois fois parce que je ne me souvenais plus où j’avais laissé la dernière version. Le résultat avait à peine changé, mais ma limite de débit, elle, avait bien bougé. C’est ce qui m’a poussée à réfléchir à un cache pour DeepSeek v4.
 Je n’attends pas de miracles. Je veux juste moins d’appels inutiles, une latence plus stable, et un peu de marge sous les limites de débit. Comme v4 n’est pas encore très documenté, j’ai commencé par observer ce qui se passe réellement avec v3 et des APIs similaires, puis j’ai façonné quelques patterns côté client avec lesquels je peux vivre. Si DeepSeek publie un cache officiel pour v4, je veux être prête à le brancher sans refaire tout mon workflow.
Je n’attends pas de miracles. Je veux juste moins d’appels inutiles, une latence plus stable, et un peu de marge sous les limites de débit. Comme v4 n’est pas encore très documenté, j’ai commencé par observer ce qui se passe réellement avec v3 et des APIs similaires, puis j’ai façonné quelques patterns côté client avec lesquels je peux vivre. Si DeepSeek publie un cache officiel pour v4, je veux être prête à le brancher sans refaire tout mon workflow.
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. DeepSeek V3.2 API → · DeepSeek R1 API →
Voici comment j’aborde la question du cache deepseek v4 : supposer des limites, mettre en cache ce qui est répétable, réessayer calmement, et surveiller les bons indicateurs.
Limites de débit attendues
Je n’ai pas encore trouvé de tableau public et clair pour v4, alors j’ai traité ça comme une correspondance d’avion : supposer un timing serré et se préparer aux retards.
Ce que je sais de mon expérience avec DeepSeek v3 (et des fournisseurs similaires) est assez simple :
- Il y a généralement deux plafonds qui comptent au quotidien : les requêtes par minute (RPM) et les tokens par minute (TPM). Les 429 apparaissent vite lors de traitements par lots ou de tâches en arrière-plan.
- Les pics passent parfois, jusqu’à ce qu’ils ne passent plus. Des charges en rafale peuvent fonctionner une minute, puis bloquer la suivante.
- Les limites peuvent différer selon la clé, le niveau de compte, et parfois l’IP. Cela rend les tests locaux généreux et la production moins indulgente.
Donc quand je pense à un cache deepseek v4, je l’associe à une gestion conservative des débits. L’objectif n’est pas de faire passer chaque dernier appel, c’est de lisser la courbe pour ne pas passer l’après-midi à chasser des 429.
Basé sur les limites actuelles de V3
J’ai effectué quelques tests légers en janvier 2026 avec un mélange d’appels de génération et de reranking sur des endpoints v3. Rien de scientifique, juste assez pour sentir les limites. Quelques notes que j’ai gardées :
- Les prompts lourds en tokens (grandes fenêtres de contexte) déclenchent le TPM avant le RPM. Cela signifie que mettre en cache les parties lourdes est rentable même si les sorties changent.
- Les prompts courts et répétés (vérifications de santé, exécutions de templates) déclenchent d’abord le RPM. Ce sont des candidats idéaux pour un cache de réponses avec un TTL court.
- Le backoff fonctionne, mais l’exponentiel seul n’est pas un plan. Il faut une file d’attente pour ne pas exploser la concurrence pendant qu’on « attend poliment ».
Tout cela pour dire : si v4 reflète les niveaux de v3, j’attends un TPM serré pour les grands contextes, un RPM raisonnable pour une utilisation interactive, et des pénalités rapides pour les charges en rafale. Mon setup suppose que je verrai des pics de 429 et de 5xx pendant les périodes chargées et les traite comme normaux, pas comme exceptionnels.
Patterns côté client
Je n’attends pas une fonctionnalité officielle de cache deepseek v4 pour faire le ménage de mon côté. Ce sont les patterns que j’ai mis en place devant l’API pour pouvoir brancher un cache fournisseur plus tard sans changer mes habitudes.
Backoff exponentiel
Ma première version utilisait un simple backoff exponentiel (200ms, 400ms, 800ms, max autour de 5–8s). Ça fonctionnait, mais semblait instable sous charge. Ce qui a aidé :
- Ajouter du jitter. Je randomise un peu chaque délai (par exemple, une variance de 20–30%). Cela répartit les tentatives et prévient les tempêtes de synchronisation quand beaucoup d’appels échouent en même temps.
- Limiter les tentatives. Trois tentatives pour les lectures idempotentes ou les prompts mis en cache. Une tentative pour les interactions clairement orientées utilisateur, sauf si l’interface attend un indicateur de chargement. Si ça prend plus de ~10 secondes à se stabiliser, je préfère échouer proprement plutôt que de retenir quelqu’un en otage.
- Distinguer 429 de 5xx. Un 429 suggère que je devrais ralentir toute la file d’attente. Un 5xx suggère une brève perturbation : je réessaierai quelques fois, puis j’ouvrirai le circuit (plus de détails ci-dessous).
Une petite observation : le backoff ne m’a pas fait gagner de temps au début. Ce qu’il a fait, après quelques exécutions, c’est réduire l’effort mental. J’ai arrêté de surveiller le terminal, ce qui dans mon univers vaut autant que la vitesse.
File d’attente des requêtes
La concurrence est là où j’ai généralement des problèmes. J’ai ajouté une file d’attente simple côté client avec ces règles :
- Concurrence fixe (commencer avec 2–4 workers pour les tâches en arrière-plan, 1–2 pour les actions déclenchées par l’interface). Je l’augmente seulement après une période calme.
- Planification tenant compte des tokens. Si je peux estimer les tokens, je planifie les prompts lourds en premier pendant les fenêtres calmes, puis je complète avec des appels légers. Cela maintient le TPM plus plat.
- Couloirs prioritaires. Les actions utilisateur peuvent préempter les tâches par lots. Si quelqu’un attend, le système s’écarte.
Je mets aussi en cache les parties coûteuses en amont :
- Les échafaudages de prompt. Si le prompt système et les outils changent rarement, je les hache et traite le hash comme clé de cache. Si v4 publie un cache de contexte côté serveur, je passerai cette clé : pour l’instant c’est juste mon propre tag.
- Le contexte récupéré. Je mets en cache les chunks RAG par empreinte de contenu. Si la source n’a pas changé, je réutilise le même bloc de contexte plutôt que de re-récupérer et ré-intégrer à chaque fois.
Ce n’est pas glamour, mais ça a réduit mes 429 de tâches en arrière-plan d’environ 70% en une semaine. Pas plus rapide, juste plus stable.
Disjoncteur
Je ne m’attendais pas à en avoir besoin. Puis un après-midi, le service a commencé à lancer des 5xx pendant quelques minutes et ma logique de retry les a joyeusement amplifiés. Le disjoncteur a corrigé ça.
Mes règles sont simples :
- Ouvrir le circuit si le taux d’erreur dépasse un seuil (disons, >30% des appels échouant sur une fenêtre de 60–90 secondes) ou si la latence dépasse le P95 pendant deux fenêtres consécutives.
- Pendant l’ouverture, court-circuiter les appels et se replier : servir des réponses mises en cache si disponibles, dégrader les fonctionnalités (contexte plus petit, prompts plus simples), ou afficher un message calme expliquant la pause.
- Semi-ouvert après une période de backoff. Laisser passer un filet de requêtes et surveiller les métriques. Si elles tiennent, fermer le circuit.
Ce qui m’a surprise, c’est combien l’interface semblait plus calme. Un propre « on fait une pause une minute » vaut mieux qu’un indicateur qui tourne indéfiniment.
Surveillance et alertes
 Je n’aime pas combattre des incendies à l’aveugle. Pour quelque chose comme un cache deepseek v4, les signaux utiles sont petits et ennuyeux.
Je n’aime pas combattre des incendies à l’aveugle. Pour quelque chose comme un cache deepseek v4, les signaux utiles sont petits et ennuyeux.
Ce que je surveille :
- Le taux de hit du cache. Divisé par type : échafaudage de prompt, contexte récupéré, et réutilisation de réponse complète. Si les hits de réponse complète montent au-dessus de ~25% pour un workflow, je vérifie les TTL — je suis peut-être en train de trop mettre en cache et de manquer du contexte frais.
- TPM/RPM effectif. Pas seulement les chiffres du fournisseur, mais ce qui passe après la mise en file d’attente. Si le RPM effectif reste plat pendant que l’entrée augmente, la file fait son travail.
- Distribution des tentatives. Combien d’appels réussissent au premier essai versus au deuxième/troisième. Une dérive vers des tentatives plus tardives signifie qu’une pression se construit quelque part.
- Bandes de latence. Le P50 me dit le chemin heureux ; le P95 me dit ce que les utilisateurs ressentent un mauvais jour. J’alerte sur le P95.
- Taxonomie des erreurs. 429 vs 5xx vs timeouts. Des leviers différents corrigent chacun.
Des alertes qui ne crient pas :
- Latence P95 multipliée par 2 pendant 5 minutes. Me contacter seulement si ça persiste.
- Taux de 429 au-dessus de 5% sur 10 minutes. Baisser automatiquement la concurrence d’un cran et allonger l’attente de file ; me prévenir que c’est arrivé.
- Circuit ouvert pendant plus de 3 minutes. C’est un vrai incident. Je vérifie le statut du fournisseur et décide de changer de région ou de mettre en pause les tâches par lots.
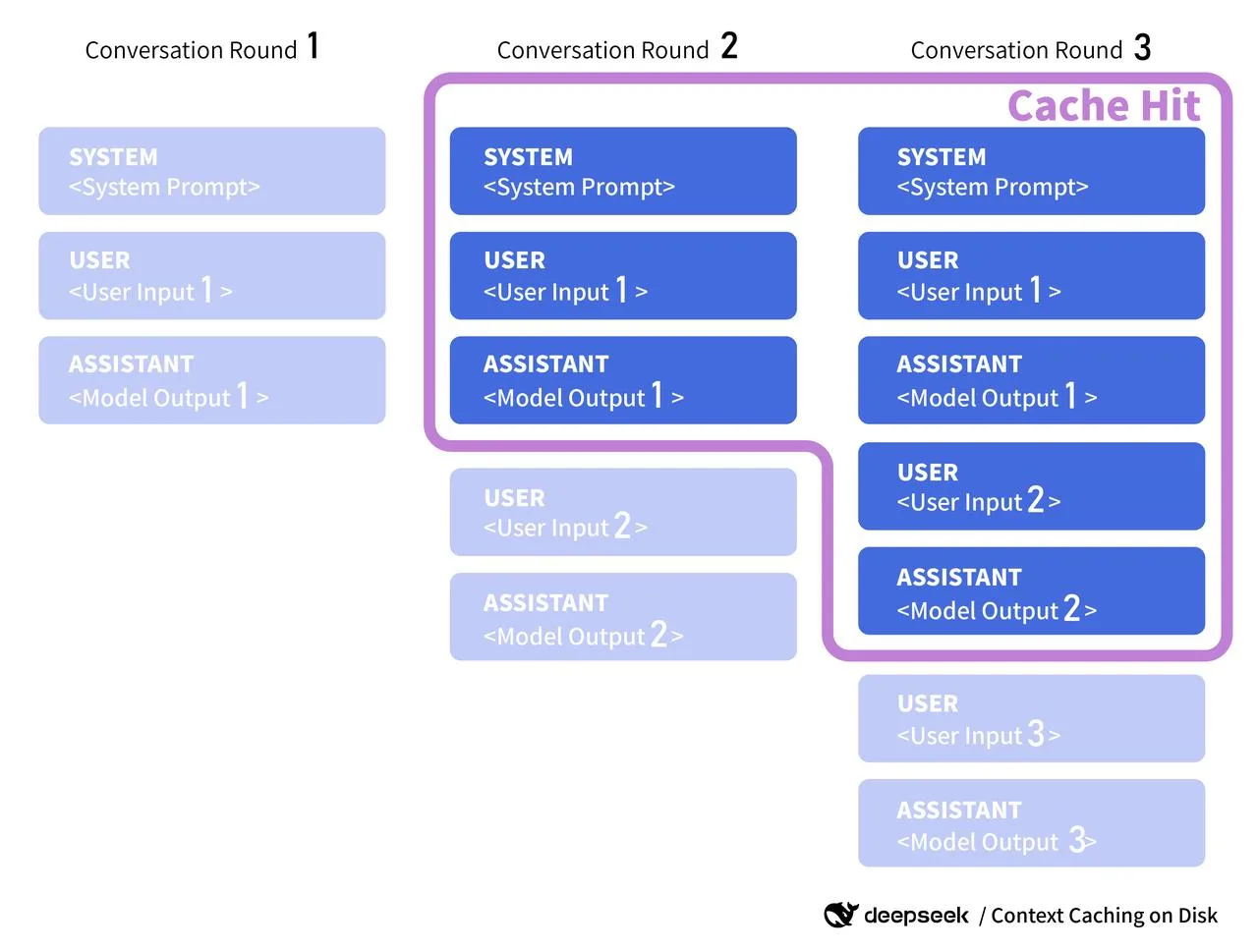 Un mot rapide sur les docs officielles : quand les docs v4 seront publiées, je chercherai tout ce qui ressemble à du cache de contexte côté serveur, des clés de cache, ou des tokens de réutilisation. Certains fournisseurs exposent un cache_id que vous pouvez attacher à un segment de préfill partagé (pensez : long prompt système). Si DeepSeek fait quelque chose de similaire, j’alignerai mes clés client sur leur format et respecterai les règles de TTL ou d’invalidation qu’ils publient. En attendant, je traite mon cache comme consultatif : utile quand il touche, inoffensif quand il rate.
Un mot rapide sur les docs officielles : quand les docs v4 seront publiées, je chercherai tout ce qui ressemble à du cache de contexte côté serveur, des clés de cache, ou des tokens de réutilisation. Certains fournisseurs exposent un cache_id que vous pouvez attacher à un segment de préfill partagé (pensez : long prompt système). Si DeepSeek fait quelque chose de similaire, j’alignerai mes clés client sur leur format et respecterai les règles de TTL ou d’invalidation qu’ils publient. En attendant, je traite mon cache comme consultatif : utile quand il touche, inoffensif quand il rate.
À qui ce setup s’adresse :
- Les personnes avec des prompts répétables et un contexte qui évolue lentement (docs, centres d’aide, bases de connaissances). Le cache brille ici.
- Les équipes traitant des tâches par lots la nuit. La file d’attente et le disjoncteur réduisent les surprises.
- Quiconque est fatigué des à-coups. Ce n’est pas plus rapide, mais c’est plus calme.
Qui pourrait s’en passer :
- Les chats très dynamiques et spécifiques à l’utilisateur où la fraîcheur prime sur la réutilisation. Mettre en cache les échafaudages, bien sûr, mais pas les réponses complètes.
- Les projets à très faible trafic. Si vous envoyez quelques appels par jour, l’overhead n’en vaut pas la peine.
Si vous voulez creuser la mécanique, je commencerais par les docs du fournisseur sur les limites de débit et toute mention de cache de contexte ou de réutilisation. Quand DeepSeek publiera les spécificités de v4, je mettrai à jour mon setup pour les faire correspondre et je lierai les docs directement. Pour l’instant, le système tient : moins d’appels gaspillés, une contre-pression plus claire, et une interface qui sait quand faire une pause.
Je garde une petite note collée près de mon écran : « Ne combats pas la file d’attente. » Ce n’est pas profond, mais les jours chargés c’est suffisant pour m’empêcher de forcer une requête de plus à travers une fenêtre qui se ferme.
Questions fréquemment posées
Comment les disjoncteurs améliorent-ils la fiabilité avec un cache deepseek v4 ?
Un disjoncteur s’ouvre quand les taux d’erreur augmentent ou que la latence P95 bondit, court-circuitant temporairement les appels. Pendant l’ouverture, servez des réponses mises en cache, dégradez les fonctionnalités (contexte plus petit), ou faites une pause propre. Après un délai de refroidissement, semi-ouvrez avec un filet pour tester la récupération. Cela empêche les tentatives d’amplifier les pannes et calme l’interface.
DeepSeek v4 offre-t-il un cache de contexte côté serveur ou des clés de cache ?
Début 2026, les détails publics pour DeepSeek v4 sont limités. Certains fournisseurs supportent un cache_id ou des segments de préfill réutilisables. Préparez-vous en hachant côté client les prompts système stables et les outils. Si DeepSeek expose ultérieurement des clés de cache côté serveur, alignez vos hashes et respectez les règles de TTL/invalidation qu’ils publient.
Quels TTL et règles d’invalidation devrais-je utiliser pour le cache LLM ?
Utilisez des TTL courts (5–30 minutes) pour la réutilisation de réponses complètes sur les vérifications de santé ou les templates, et des TTL plus longs (heures–jours) pour les échafaudages stables et le contexte récupéré lié à des empreintes de contenu. Invalidez lors des mises à jour de source, des changements de modèle/version, ou des modifications de schéma de prompt. Suivez les taux de hit ; >25% de hits de réponse complète peut indiquer un excès de mise en cache.
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir