¿Por qué HappyHorse-1.0 está de repente en el #1 del ranking de video?
HappyHorse-1.0 alcanzó el #1 en Artificial Analysis sin un equipo público. Aquí explicamos por qué el sistema Elo recompensa la calidad del video sobre la marca, y qué significa esto para los desarrolladores.

Hola a todos. Soy Dora. Conté las veces que alguien en mi feed preguntó esta semana alguna versión de ”¿qué demonios es HappyHorse?” Seis. Seis hilos distintos. Y cada uno tenía un rumor ligeramente diferente: es WAN 2.7, es un lanzamiento encubierto de ByteDance, es algo de Alibaba. Nadie lo sabe con certeza. En lo que todos coinciden: apareció en el ranking de video de Artificial Analysis alrededor del 7–8 de abril de 2026, y de inmediato tomó el puesto #1 en Text-to-Video e Image-to-Video.
Ese es el hecho. Todo lo demás — quién lo construyó, cuándo se publicarán los pesos, si se mantiene en el #1 — sigue sin resolverse.
Este artículo trata sobre lo que el ranking realmente mide, por qué un modelo desconocido puede llegar legítimamente a la cima, y qué deberías y no deberías hacer con esa información como desarrollador.
Cómo funciona el Video Arena de Artificial Analysis
Antes de confiar en un ranking, necesitas entender qué mide ese ranking. El Video Arena de Artificial Analysis no es un benchmark donde el desarrollador del modelo envía sus propias puntuaciones — es un sistema de votación ciega de usuarios.
Lo que los usuarios ven (y no ven)
Vas al arena, te muestran dos videos generados a partir del mismo prompt de texto o imagen de entrada, y eliges cuál prefieres. No sabes qué modelo generó qué video. Sin etiquetas. Sin contexto. Solo dos clips.
Así lo describe Artificial Analysis directamente: “Los usuarios comparan dos videos generados a partir del mismo prompt de texto sin saber qué modelo creó cada video.” Esa es la parte importante. No hay autoinformes, no hay benchmarks proporcionados por el desarrollador, ninguna página de marketing influenciando el resultado.
Elo: señal confiable, pero no infalible
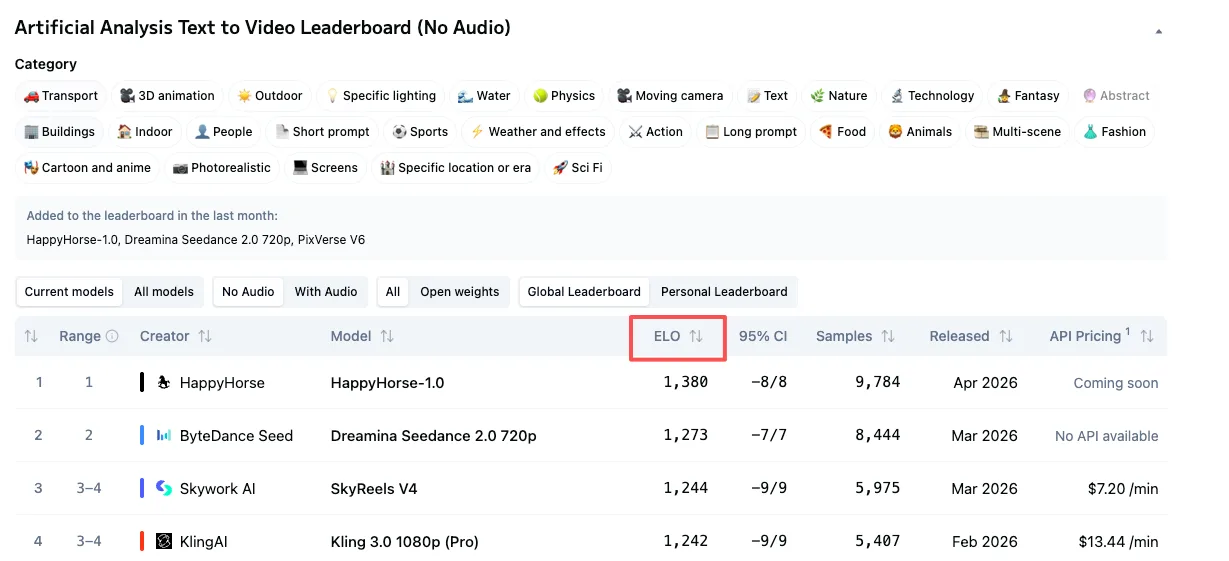
El ranking utiliza un sistema Elo — el mismo enfoque tomado del ajedrez competitivo. Cada vez que dos modelos se enfrentan en una votación, el ganador gana puntos Elo y el perdedor pierde algunos. Un modelo con un Elo alto ha ganado consistentemente más enfrentamientos contra otros modelos de los que ha perdido.
Puntuaciones Elo más altas indican que un modelo es preferido con mayor frecuencia. Esa es una señal real. Está basada en miles de elecciones humanas reales, no en pruebas sintéticas, no en ejemplos seleccionados a mano, no en una tarjeta de modelo.
Conteo de votos y tamaño de muestra: la parte que la gente omite
Aquí está la cuestión con el Elo para nuevos participantes. Los modelos establecidos como Seedance 2.0 tienen miles de votos detrás de sus puntuaciones — Seedance 2.0 tiene más de 7.500 muestras de votos en la categoría T2V. El conteo de muestras de HappyHorse aún no está desglosado públicamente. Más votos = puntuación más estable. Un modelo más nuevo con menos enfrentamientos puede oscilar más dramáticamente con cada nuevo voto.

Estos números cambiarán a medida que lleguen más votos. La dirección de ese cambio es desconocida. Tenlo en cuenta antes de tomar decisiones de pipeline basadas en un número que tiene dos días de antigüedad.
Qué está puntuando realmente HappyHorse-1.0
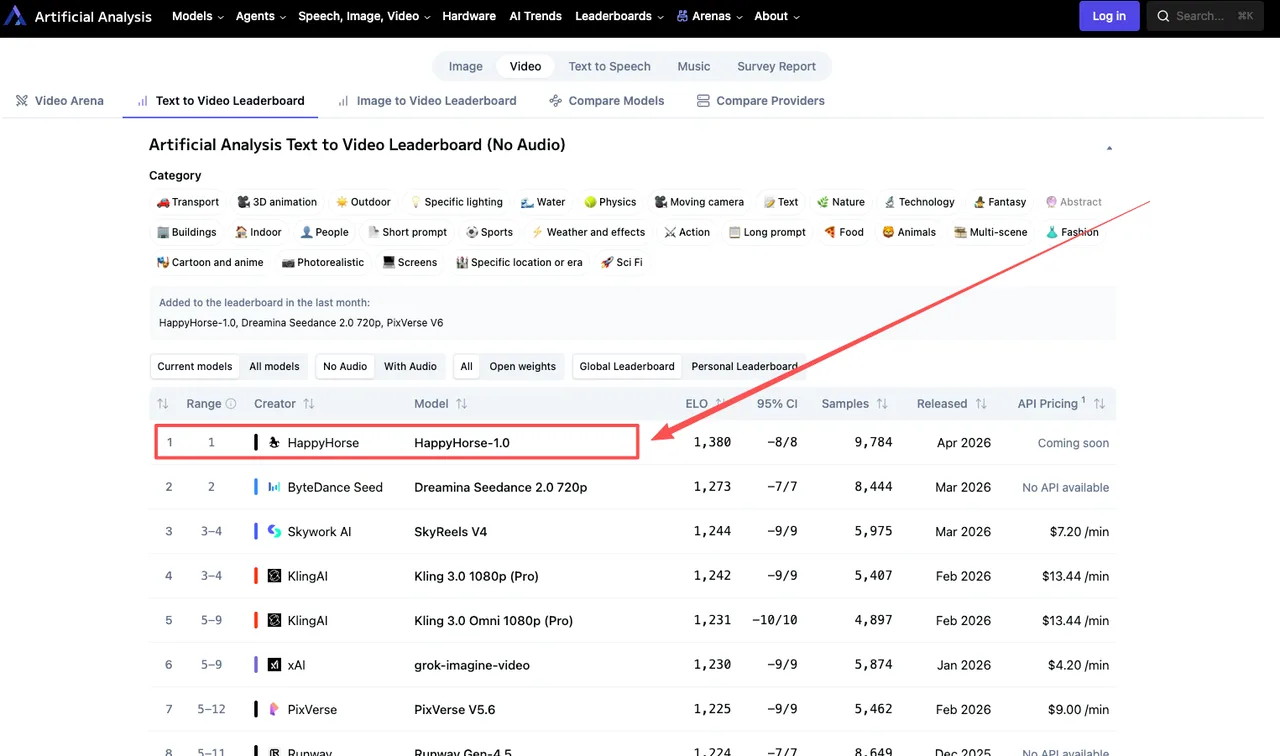
Los números actuales, extraídos del ranking en vivo a principios de abril de 2026:
T2V (sin audio): HappyHorse-1.0 lidera con una puntuación Elo de 1357, por delante de Dreamina Seedance 2.0 en 1273, SkyReels V4 en 1244 y Kling 3.0 Pro en 1243.
I2V (sin audio): HappyHorse-1.0 lidera con un Elo de 1402, con Seedance 2.0 en 1355 y Grok Imagine Video en 1331.
Esa brecha de 84 puntos en I2V sin audio no es pequeña. Una brecha Elo de 60 puntos significa que un modelo gana aproximadamente el 58–59% de los enfrentamientos ciegos — significativo. Una brecha de más de 80 puntos es aún más fuerte.
La historia del audio se invierte
Para Image-to-Video con audio, HappyHorse-1.0 actualmente lidera con una puntuación Elo de 1160, con Dreamina Seedance 2.0 en 1158. Una brecha de 2 puntos es ruido estadístico. Y en T2V con audio, Seedance 2.0 lidera en 1220 con HappyHorse en 1215.
Así que el panorama es más matizado que “HappyHorse es #1 en todas partes.” Es #1 por un margen significativo cuando se excluye el audio. Cuando la calidad del audio entra en la ecuación, está esencialmente empatado con Seedance 2.0.
Lo que dicen las afirmaciones sobre la arquitectura (y lo que no prueban)
Varios sitios que describen HappyHorse dicen que funciona con una arquitectura Transformer de flujo único con aproximadamente 15 mil millones de parámetros, con velocidades de generación declaradas de alrededor de 38 segundos para un clip de 1080p en una sola H100. Al 8 de abril de 2026, los enlaces de GitHub y Hugging Face en estos sitios de HappyHorse apuntan a páginas de “próximamente” o devuelven errores 404. Los pesos no están disponibles para descarga pública.
Estas afirmaciones arquitectónicas son plausibles — pero no están verificadas. Ninguna auditoría técnica independiente ha confirmado el conteo de parámetros, el tipo de arquitectura o las velocidades de inferencia. Trátalas como afirmadas, no confirmadas.
Por qué los modelos desconocidos pueden ganar en Elo
Esto es lo que confunde a las personas que asumen que los rankings recompensan el reconocimiento de marca.
Al Elo no le importa quién construyó el modelo. No sabe si eres Google o un laboratorio de tres personas. El Video Arena de Artificial Analysis usa el sistema de puntuación Elo y se basa enteramente en votos ciegos de usuarios reales. Ignora parámetros, papers o hype — solo le importa una pregunta: “¿Qué video preferiste después de ver ambos?”
Eso es en realidad una ventaja. Es uno de los pocos sistemas de evaluación donde una marca bien financiada no puede comprar un mejor resultado publicando un paper favorable.
Este patrón ha ocurrido antes
Los lanzamientos anónimos previos al lanzamiento se han convertido en un patrón en el ecosistema de IA chino. La situación de Pony Alpha en febrero de 2026 es el precedente más claro — un modelo misterioso apareció en OpenRouter, desencadenó un juego de adivinanzas y resultó ser el GLM-5 de Z.ai haciendo una prueba de estrés encubierta. HappyHorse encaja en esta plantilla: nombre desconocido, sin atribución de equipo en el lanzamiento, página de destino con enlaces de GitHub “próximamente”, resultados sólidos.
Si es un gran laboratorio haciendo una verificación silenciosa de capacidades o un equipo genuinamente nuevo — eso sigue sin resolverse. Pero la puntuación Elo en sí es real independientemente de ello.
La limitación que el Elo no puede ocultar
El Elo mide una cosa: qué video prefirieron los usuarios reales en una comparación ciega. No mide cómo funciona el modelo en ejecuciones por lotes. No mide el tiempo de actividad de la API, la latencia bajo carga, ni si la calidad de la salida se mantiene cuando estás generando a escala versus seleccionando ejemplos del arena.
Un modelo puede tener excelentes resultados en pruebas ciegas y ser completamente inutilizable en producción. Estas son preguntas separadas.
Lo que “Ranking #1 en el Leaderboard” no significa para los desarrolladores
Aquí es donde frenaría si estás a punto de tomar una decisión de herramienta basada en el ranking actual de HappyHorse.
Sin API, sin acceso a producción
Tres cosas moverían a HappyHorse de “entrada en el ranking” a “opción real”: un repositorio de GitHub con pesos e código de inferencia reales, una tarjeta de modelo en HuggingFace con detalles verificables y una licencia, o un endpoint de API con precios documentados. Ninguno existe al momento de escribir esto.
Si no puedes llamarlo, no puedes usarlo. La posición en el ranking es información sobre la calidad de la salida, no sobre la disponibilidad.
El rendimiento del audio cambia el cálculo
Si tu flujo de trabajo requiere audio — locución, sonido ambiental, sincronización de labios — la ventaja de HappyHorse básicamente desaparece. La brecha entre él y Seedance 2.0 en las categorías con audio es de 5 puntos en T2V y 2 puntos en I2V. Esos son empates dentro de la varianza normal de Elo.
Para casos de uso que requieren audio, el campo práctico en este momento parece un empate entre Seedance/HappyHorse en la cima, con SkyReels V4 un paso significativo por debajo.
Responsabilidad del equipo: desconocida
Artificial Analysis describió a HappyHorse como “seudónimo” cuando añadió el modelo al arena. Un conjunto de sitios conectados al modelo afirma que fue construido por el equipo Future Life Lab en Taotian Group (Alibaba), liderado por Zhang Di, ex jefe de Kling AI. Otro análisis lo conectó con un proyecto de código abierto de Sand.ai llamado daVinci-MagiHuman, que comparte especificaciones casi idénticas. Ninguno ha sido confirmado oficialmente.
Para una herramienta de producción, la responsabilidad del equipo importa para correcciones de errores, actualizaciones del modelo y soporte a largo plazo. Con modelos seudónimos, no tienes esa claridad.
Cómo leer el Video Leaderboard como desarrollador
Marco concreto, no abstracciones.
Usa el Elo como señal de calidad, no como decisión de adquisición. Si un modelo gana consistentemente comparaciones ciegas contra competidores bien financiados, eso te dice algo real sobre lo que produce. Vale la pena notarlo. No te dice nada sobre los términos de la API, precios, latencia, ni si el equipo responde a los informes de errores.
El ranking práctico empieza en el #3. Los dos modelos de mayor calidad por Elo — HappyHorse y Seedance 2.0 — son inaccesibles a través de API pública. El siguiente nivel — SkyReels V4, Kling 3.0, PixVerse V6 — es donde se toman las decisiones de integración reales en este momento.
Cuándo actuar temprano ante un nuevo participante en el ranking. Si un modelo está en la cima con una brecha Elo significativa, tiene una versión de GitHub verificada y existe documentación — vale la pena probarlo de inmediato. Si está en la cima pero GitHub dice “próximamente” — pon un recordatorio para revisar en dos semanas. No reestructures un pipeline en torno a vapor.
Consulta el ranking en vivo directamente, no artículos. Incluyendo este. Las puntuaciones Elo cambian diariamente. Los números que he mencionado aquí reflejan principios de abril de 2026 y habrán cambiado para cuando leas esto.
Preguntas frecuentes
¿Cuánto tiempo lleva HappyHorse-1.0 en el ranking de Artificial Analysis?
Artificial Analysis lo anunció el 7 de abril de 2026, describiéndolo como un modelo seudónimo recién añadido. Al momento de escribir esto, lleva aproximadamente 48 horas en vivo y los conteos de votos siguen acumulándose.
¿Puede un modelo mantenerse en el #1 de Elo indefinidamente?
Generalmente no. A medida que modelos más nuevos entran al arena y acumulan más votos, los rankings cambian. Un modelo que domina en el día dos con una muestra pequeña puede estabilizarse más abajo a medida que el pool de votos se profundiza. La puntuación siempre está en vivo — refleja datos actuales, no un juicio permanente.
¿Verifica Artificial Analysis quién envía modelos al arena?
Artificial Analysis no ha publicado una política formal de verificación para los envíos de modelos. Describieron a HappyHorse-1.0 como “seudónimo” al anunciarlo, lo que sugiere que la identidad del equipo les es conocida pero no se divulga públicamente. Si realizan alguna auditoría técnica de los modelos enviados no está documentado.
¿Debo elegir un modelo basándome únicamente en la puntuación Elo?
No. El Elo te informa sobre la preferencia visual en comparaciones ciegas. No dice nada sobre la disponibilidad de la API, el costo por generación, la latencia, el tiempo de actividad, la política de contenido, o si el modelo existirá dentro de tres meses. Es una señal entre varias.
¿Qué otras métricas importan junto con los rankings del leaderboard?
Acceso a la API y documentación; precio por generación o por minuto; latencia y comportamiento de arranque en frío a tu frecuencia de uso; conteo de muestras detrás de la puntuación Elo (más votos = más estable); y si el equipo tiene un historial de mantenimiento y actualización del modelo. La página de comparación de modelos de WaveSpeed rastrea varias de estas dimensiones en modelos accesibles si quieres un punto de partida.
Así están las cosas. Un modelo con un equipo desconocido y sin pesos públicos acaba de liderar el benchmark de video más creíble que tenemos, por un margen difícil de ignorar. Si se convierte en una opción real de producción depende enteramente de lo que se publique en las próximas semanas.
Vale la pena seguirlo. No vale la pena actuar todavía.
Más por venir.
Prueba HappyHorse-1.0 en WaveSpeedAI
HappyHorse-1.0 ya está disponible en WaveSpeedAI:
Publicaciones anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber