¿Qué es SkyReels V4? El Primer Modelo de IA Unificado de Video y Audio Explicado
SkyReels V4 es la primera IA de código abierto que genera video y audio juntos, a 1080p/32FPS. Aquí te explicamos qué hace, cómo funciona y por qué es importante.

Hola, soy Dora. Ese día generé mi primer video con **SkyReels V4**. Quince segundos de un gato caminando por un callejón empapado de lluvia al atardecer. El video se veía bien — 1080p, movimiento fluido, iluminación agradable. Pero lo que me hizo pausar fue el audio. Pasos salpicando en charcos. Tráfico lejano. El suave eco de las paredes del callejón. Todo generado junto, sincronizado perfectamente, sin que yo tocara ni una sola herramienta de edición de audio.
Esa fue la parte que se sintió diferente.
El Problema que Tenía Toda Herramienta de IA para Video Antes de V4
Por qué la generación solo de video siempre se sentía incompleta
La mayoría de las herramientas de IA para video generan clips sin sonido. Runway, Pika, incluso las versiones anteriores de SkyReels — producen imágenes y se detienen ahí. Obtienes una hermosa toma de 10 segundos de olas rompiendo en una playa, pero está completamente en silencio. Las olas no rompen. El viento no sopla. No hay ningún sonido ambiental en absoluto.
Esto no es un descuido técnico. Generar audio sincronizado junto con el video es genuinamente difícil. El audio necesita coincidir no solo con la escena general, sino con eventos visuales específicos — pasos que suenan cuando los pies tocan el suelo, puertas que se cierran cuando se balancean, voces que sincronizan con los movimientos de los labios.
El cuello de botella de “agregar audio en posproducción”
El flujo de trabajo estándar se convirtió en: generar video, exportarlo, abrir un editor de audio, agregar efectos de sonido o música manualmente, sincronizar todo a mano, exportar de nuevo. Para un clip de 15 segundos, esto podía llevar entre 20 y 30 minutos.
Probé esto con resultados de Pika el mes pasado. El video se veía profesional. Pero encontrar los sonidos ambientales correctos, sincronizarlos con las señales visuales y evitar esa sensación de “obviamente agregado después” consumió más tiempo que generar el propio video. El flujo de trabajo se sentía roto — como comprar un auto pero tener que instalar el motor por separado.
Qué Es Realmente SkyReels V4
Desarrollado por SkyworkAI (explicación del linaje V1/V2/V3)
SkyworkAI lanzó SkyReels V1 a principios de 2025 como un modelo básico de texto a video. V2 le siguió con una arquitectura de diffusion forcing que permitió generación de duración infinita mediante secuencias autorregresivas. V3 se lanzó en enero de 2026 con aprendizaje en contexto multimodal — podías alimentarlo con imágenes de referencia, clips de audio o video existente y generaría continuaciones coherentes.

V4, que se puso en marcha el 25 de febrero de 2026, representa un tipo diferente de salto. Mientras que V3 agregó funcionalidades, V4 reestructuró toda la arquitectura en torno a un sistema de flujo dual que genera video y audio simultáneamente.
Qué significa realmente “modelo fundacional unificado de video-audio”
El artículo técnico describe a V4 como un Transformador de Difusión Multimodal (MMDiT) con dos ramas paralelas. Una rama sintetiza fotogramas de video. La otra genera audio alineado temporalmente. Ambas ramas comparten un codificador de texto basado en modelos de lenguaje grande multimodales, lo que significa que procesan la misma comprensión semántica de tu prompt y mantienen la sincronización durante toda la generación.
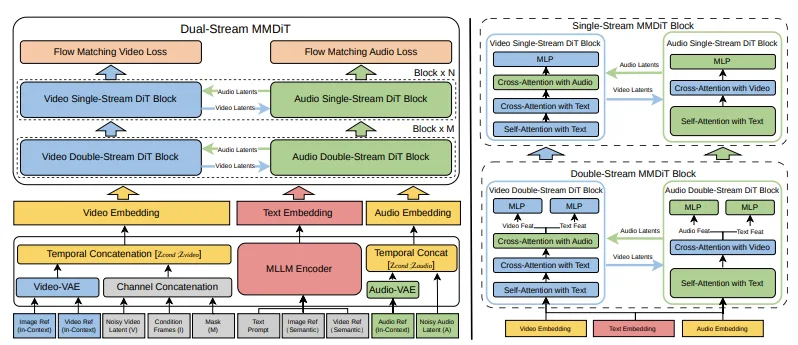
Esto no es generación de video con audio añadido encima. Es un único modelo que trata la vista y el sonido como salidas igualmente importantes, generadas juntas desde la misma comprensión latente de la escena.
En la práctica, esto significa que cuando escribes “una mujer hablando en un podio,” el modelo genera tanto la imagen visual de sus labios moviéndose como el audio real del discurso, sincronizados a nivel de fotograma. Cuando generas “lluvia intensa sobre un techo de metal,” obtienes tanto la imagen visual de la lluvia cayendo como el característico sonido de tamborileo metálico — no aproximadamente sincronizados, sino generados como un evento audiovisual unificado.
Capacidades Clave de un Vistazo
Generación conjunta de video + audio desde un solo prompt
La generación con un único prompt es la capacidad central. Escribes “truenos retumbando sobre un paisaje desértico” y V4 produce 15 segundos de nubes acumulándose, relámpagos destellando y truenos sincronizados que coinciden con el timing visual. Sin un paso de generación de audio separado. Sin trabajo de sincronización manual.
Probé esto con escenas de diálogo. Escribí “dos personas discutiendo en un café concurrido” y obtuve no solo la imagen visual de la conversación sino el murmullo de fondo, el tintineo de platos y las voces de los hablantes subiendo y bajando con la intensidad de sus gestos. La sincronización de labios no fue perfecta — noté algunos momentos donde el timing se desfasó ligeramente — pero fue mejor que cualquier cosa que yo hubiera sincronizado manualmente.
Salida de 1080p / 32FPS / 15 segundos
Especificaciones técnicas: hasta 1080p de resolución, 32 fotogramas por segundo, duración máxima de 15 segundos. Para contexto, la mayoría de las herramientas competidoras tienen un máximo de 720p o requieren tiempos de generación significativamente más largos para salida en HD.
El límite de 15 segundos importa más de lo que parece. La mayoría del contenido para redes sociales vive en fragmentos de 10 a 15 segundos. YouTube Shorts tiene un límite de 60 segundos. Instagram Reels de 90. Para ese caso de uso, 15 segundos con audio sincronizado es más útil que 30 segundos de video silencioso que necesita posproducción.
Entradas multimodales: texto, imagen, video, máscara, referencia de audio
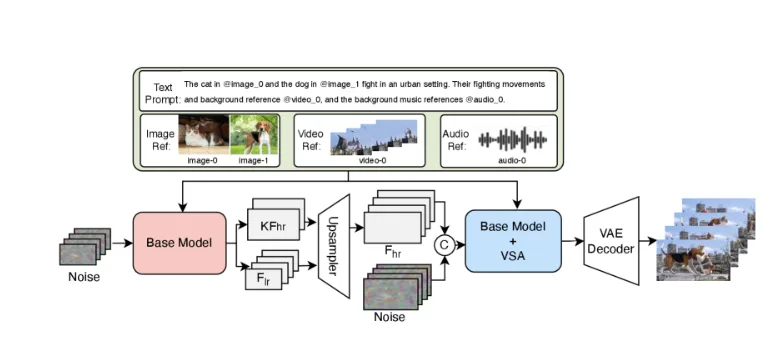
V4 acepta cinco tipos de entrada: prompts de texto, imágenes de referencia, clips de video, máscaras binarias para inpainting y referencias de audio. Puedes combinarlos — subir una imagen de una persona específica, proporcionar una muestra de audio de pasos sobre grava y escribir “caminando por un bosque al amanecer.” El modelo usa las tres entradas para guiar la generación.
Probé el prompting multimodal con una imagen de referencia de un estilo arquitectónico específico y un clip de audio de ambiente urbano. El video generado mantuvo los detalles arquitectónicos de la imagen mientras incorporaba los sonidos ambientales de la referencia de audio. No perfectamente — algunos elementos de audio se sentían genéricos — pero la funcionalidad funcionó.
Tres tareas en una: generar, inpaint, editar
Más allá de la generación, V4 maneja el inpainting y la edición mediante concatenación de canales. Proporciona un video y una máscara que indica qué regiones modificar, y el modelo regenera solo esas áreas preservando el resto. Esto permite tareas como eliminar objetos, cambiar fondos o reemplazar elementos específicos sin regenerar el clip completo.
Cómo se Compara V4 con lo que Existía Antes
Evolución de V4 frente a SkyReels V1/V2/V3
V1 era solo texto a video. V2 agregó duración mediante diffusion forcing. V3 introdujo entradas multimodales pero aún generaba video sin audio nativo. V4 es el primero en tratar el audio como una salida de primera clase generada simultáneamente con el video.
¿Quién Debería Prestar Atención a SkyReels V4?

Creadores de contenido y cineastas
Cualquiera que produzca contenido de formato corto para plataformas sociales se beneficia inmediatamente. La compresión del flujo de trabajo — de prompt a clip audiovisual terminado — elimina el cuello de botella que hacía que las herramientas de IA para video sintieran que creaban más trabajo del que ahorraban.
Vi a un amigo cineasta usar V4 para generar tomas de B-roll para un documental. Prompts como “time-lapse de las luces de la ciudad encendiéndose al atardecer” o “primer plano de lluvia en el cristal de una ventana” con sonidos ambientales apropiados. Los resultados no eran indistinguibles del material real, pero eran lo suficientemente buenos para tomas de fondo, y estaban listos en menos de 60 segundos cada uno, en lugar de requerir rodajes en locación o licencias de material de archivo.
Desarrolladores que construyen pipelines de video
Si estás construyendo aplicaciones que generan o manipulan video, la interfaz unificada de V4 para generación, inpainting y edición simplifica la pila. En lugar de encadenar modelos separados para generación de video, síntesis de audio y corrección de sincronización, una sola llamada a la API maneja el flujo completo.
La arquitectura del modelo está documentada en detalle, y SkyworkAI tiene un historial de código abierto en versiones anteriores, lo que sugiere que el acceso para desarrolladores se expandirá. Los pesos de V3 ya están disponibles en Hugging Face y GitHub.
Estado de Acceso Actual y Lo que Viene
A partir del 2 de marzo de 2026, V4 está en vista previa limitada. El sitio oficial ofrece un nivel gratuito con límites de generación diarios, pero aún sin acceso a API. Basándome en el cronograma de V3 — que pasó de la publicación del artículo a la API pública en aproximadamente dos semanas — esperaría una disponibilidad más amplia para mediados de marzo.
El artículo técnico señala que el trabajo futuro incluye extender más allá de los 15 segundos y mejorar el control de audio de grano fino. Esas limitaciones se sienten significativas ahora mismo, especialmente el límite de duración. Pero para el problema específico que V4 resuelve — generar clips audiovisuales cortos y sincronizados sin posproducción — funciona mejor que cualquier otra cosa que haya probado.
He mantenido V4 en mi flujo de trabajo desde esa primera prueba. No para todo — todavía hay tareas donde el material filmado o el video de archivo tiene más sentido. Pero para B-roll rápido, escenas ambientales o fragmentos para redes sociales donde el audio sincronizado importa, V4 eliminó suficiente fricción como para que ahora lo use primero.
La arquitectura unificada se siente menos como una función incremental y más como arreglar algo que debería haber funcionado así desde el principio.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber