Control de Primer y Último Fotograma en WAN 2.7: Guía para Desarrolladores
Cómo usar el control de primer y último fotograma de WAN 2.7 para una generación de video predecible: preparación de entradas, parámetros de API y consejos para flujos de trabajo en producción.

Hey, chicos, Dora está llegando. Seguía viendo equipos describir el control de primer/último fotograma como “solo subes dos imágenes.” Es como describir las colas de trabajos asíncronos como “solo esperas.” La mecánica no es difícil — pero las decisiones de diseño de entrada son donde la mayoría de los flujos de trabajo en producción fallan silenciosamente.
Esta guía es para desarrolladores que necesitan resultados repetibles, no solo una demo que funcionó una vez.
Qué Hace Realmente el Control de Primer y Último Fotograma
El Problema que Resuelve vs I2V Estándar
La imagen a video estándar (I2V) ancla el fotograma de apertura y luego el modelo improvisa. El resultado es lo que la comunidad suele llamar “deriva” — el sujeto, la posición de cámara o la iluminación diverge gradualmente de cualquier estado objetivo que tenías en mente. Para demos de productos o secuencias narrativas con un punto final requerido, esto es costoso de corregir en posproducción.
El enfoque FLF2V de WAN utiliza un mecanismo adicional de ajuste de control: los fotogramas primero y último se tratan como condiciones de control, y las características semánticas de ambas imágenes se inyectan en el proceso de generación. Esto mantiene el estilo, el contenido y la estructura consistentes mientras el modelo se transforma dinámicamente entre ellos.
Cómo Se Usan Ambos Fotogramas Durante la Generación
El modelo no simplemente interpola valores de píxeles. Utiliza características semánticas CLIP y mecanismos de atención cruzada para mantener el video estable — este diseño ha demostrado reducir el temblor del video en comparación con los enfoques de ancla única. Tu primer fotograma define el estado inicial; tu último fotograma restringe el destino. El camino de movimiento entre ellos se infiere, no se especifica, lo cual es tanto el poder como el principal modo de fallo.
Qué Infiere el Modelo sobre el Camino Entre Ellos
Tu prompt de texto guía cómo ocurre la transición — no solo que ocurre. Si tu prompt dice “el producto rota lentamente y revela su cara frontal,” esa descripción de movimiento da forma al camino inferido. Sin un prompt, el modelo intentará una transición plausible, pero tendrás mucho menos control sobre los cambios de dirección, el movimiento de cámara o el ritmo.
Preparación de Entradas
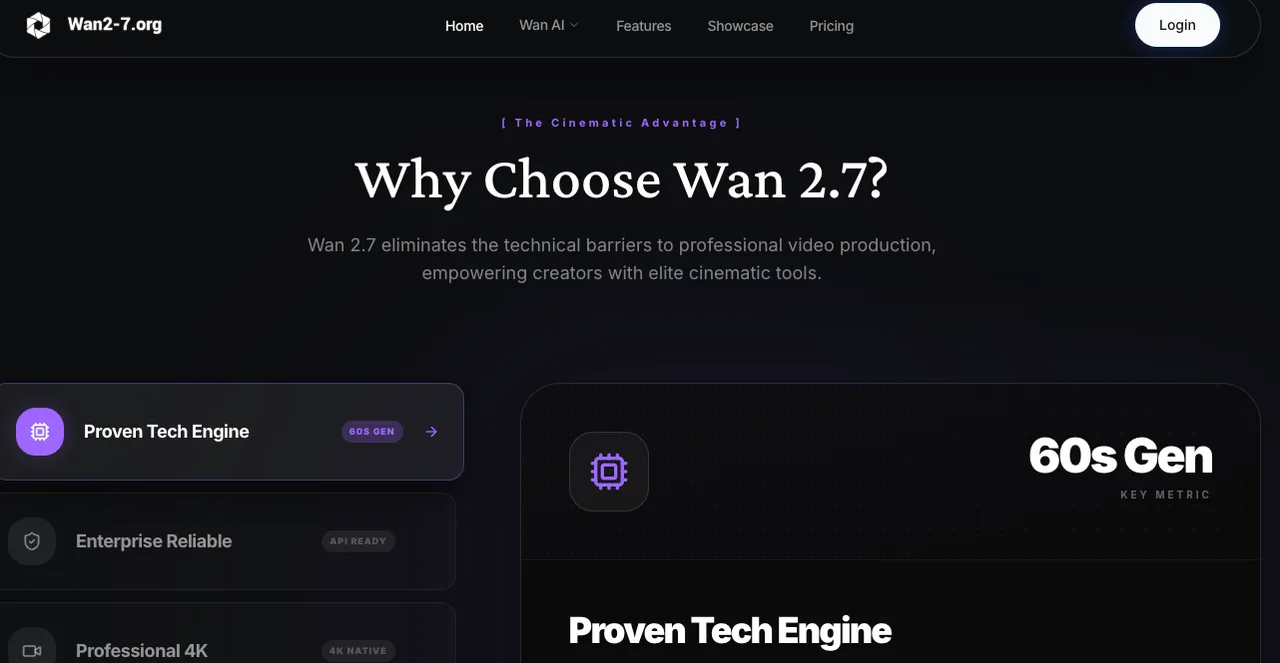
Requisitos de Especificación de Imagen
El modelo usa la relación de aspecto de tu primer fotograma lo más cercana posible a tu salida objetivo. Para una entrada 3:4 (750×1000), una configuración de salida 720P producirá algo alrededor de 816×1104 — no exactamente 3:4. Si necesitas proporciones exactas, planea recortar o agregar bandas negras en posproducción. Para la serie WAN en general, 720p (1280×720 o equivalente en retrato) es la resolución recomendada para salida de calidad; usar resoluciones más pequeñas es una estrategia válida para iteraciones de prueba pero no para finales.
Formato: PNG o JPEG de alta calidad. Evita miniaturas comprimidas como fotogramas primero/último — los artefactos de compresión introducen ruido que el modelo tiene que interpretar como información visual intencional.
Estrategias de Emparejamiento de Fotogramas que Funcionan
Los pares más fuertes comparten tres cosas: dirección de fuente de luz consistente, características de profundidad de campo coincidentes, y un sujeto que es espacialmente plausible en ambas posiciones. Una foto de producto con luz de estudio difusa emparejada con un fotograma final que muestra el mismo producto en un ángulo ligeramente diferente funciona bien. Un packshot a una imagen hero de estilo de vida funciona si la configuración de iluminación es similar.
Para secuencias narrativas, piensa en el par como definiendo un verbo: abierto → cerrado, antes → después, ensamblando → completo. Cuanto más limpia sea la relación semántica, más coherente será el camino inferido.
Qué Hace un Mal Par de Fotogramas
Tres culpables comunes:
Dirección de iluminación inconsistente. Si tu primer fotograma tiene la luz principal a 45° a la izquierda y tu último fotograma fue tomado con luz cenital, el modelo intentará hacer la transición entre dos entornos de sombra diferentes. El resultado suele ser un salto de fuente de luz a mitad del clip que parece un error de renderizado.
Desajuste espacial. Un plano general amplio emparejado con un primer plano estrecho obliga al modelo a inventar un movimiento de cámara. A veces eso es intencional; generalmente no lo es. Mantén la distancia focal aproximadamente consistente a menos que estés solicitando explícitamente un zoom o alejamiento.
Señales de profundidad conflictivas. Bokeh en el primer fotograma, todo enfocado en el último — el modelo interpretará esto como un cambio de profundidad de campo e intentará animarlo. Eso no siempre está mal, pero rara vez es lo que pretendías.
Implementación de API
Lo siguiente refleja el patrón FLF2V documentado para la serie WAN. Verifica los nombres de parámetros actuales y las rutas de endpoint en la documentación de Alibaba Cloud Model Studio antes del uso en producción. Los detalles específicos de la API de WAN 2.7 deben confirmarse en el lanzamiento.
Estructura del Payload
El patrón central involucra dos entradas de imagen — una a través de URL pública o ruta de archivo local — pasadas como first_frame_url y last_frame_url, junto con un prompt de texto y configuración de resolución.
Patrón de Solicitud Python (Pseudocódigo)
# Verifica el nombre del modelo y el endpoint en el lanzamiento — los nombres cambian entre versiones
import os
from dashscope import VideoSynthesis
response = VideoSynthesis.async_call(
model="wan2.x-flf2v-<verificar-en-lanzamiento>", # confirma la cadena exacta del modelo
first_frame_url="https://your-cdn.com/start.png",
last_frame_url="https://your-cdn.com/end.png",
prompt="Cámara fija. Comenzar desde la primera imagen, terminar en la última imagen. [describir movimiento]",
negative_prompt="parpadeo, deformación, desenfoque",
resolution="720P", # verificar valores aceptados
# parámetro seed: bloquéalo una vez que tengas una buena ejecución
)
task_id = response.output.task_idManejo Asíncrono para Trabajos Más Largos
Las tareas de generación de imagen a video típicamente tardan 1–5 minutos. La API usa un patrón asíncrono de dos pasos: enviar la tarea, obtener un ID de tarea, luego sondear el resultado. Incorpora el sondeo en tu pipeline desde el principio. No asumas comportamiento síncrono incluso para llamadas de prueba — los tiempos de espera agotados descartarán resultados silenciosamente en implementaciones ingenuas.
Flujo de Trabajo en Producción: Método Borrador-a-Final
Paso 1 — Construye un Par de Referencia y Ejecuta una Prueba
Comienza con un solo par. No proceses en lote hasta que hayas visto una salida de principio a fin. Usa tu contenido objetivo — no imágenes de stock de marcador de posición — porque las características espaciales y de iluminación necesitan representar tu biblioteca de recursos real.
Paso 2 — Valida el Camino de Movimiento Antes del Lote
Mira el clip completo una vez a 0.5x de velocidad. Busca: temblor a mitad del clip, deriva de identidad del sujeto alrededor del fotograma 50–70% del clip (aquí es donde se concentran la mayoría de los artefactos), y discontinuidad de iluminación. Si ves cualquiera de estos, corrige el par de entrada antes de tocar el prompt.
Paso 3 — Bloquea tu Mejor Seed para Consistencia
Una vez que tengas una salida limpia, registra el valor del seed. El modelo FLF2V acepta un prompt opcional para guiar la lógica de acción intermedia y transformación. Un seed bloqueado más un prompt bloqueado te da una unidad de generación reproducible que puedes aplicar en pares de entrada similares. Esto es lo que hace que la producción en lote sea predecible en lugar de probabilística.
Paso 4 — Escala a Generación en Lote
Estructura tu lote como: un “par de prueba” canónico que sirve como tu ancla de calidad, luego pares variantes generados desde la misma configuración de toma controlada. La página del modelo en Hugging Face para WAN FLF2V documenta la versión de peso abierto para equipos que ejecutan inferencia local junto con llamadas a API.
Dónde Encaja Esta Función (y Dónde No)
Ideal para: secuencias de demo de productos donde el punto final importa (packshot → revelación de características), tomas de continuidad narrativa con un antes/después definido, caminos de cámara controlados donde necesitas estabilidad espacial en múltiples clips de una serie.
No ideal para: movimiento altamente dinámico con cambios bruscos de dirección (el modelo los suavizará, a menudo perdiendo el drama), transiciones espaciales ambiguas donde los fotogramas primero y último no comparten una relación semántica clara, o escenarios que requieren temporización precisa de fotogramas — el modelo controla el ritmo, no tú.
Patrones de Fallo Comunes y Soluciones
Artefacto de movimiento a mitad del clip. Generalmente causado por un desajuste espacial en el par de entrada. El modelo “se compromete” con un camino de interpolación temprano, y la inconsistencia emerge alrededor del punto medio. Solución: ajusta la relación entre fotogramas antes de cambiar el prompt.
Inconsistencia de estilo de fotograma. Si tu primer fotograma es un render estilizado y tu último es una fotografía, el modelo intentará mezclar los estilos visuales. Esto rara vez produce una salida limpia. Iguala el tratamiento de imagen — ambos renders, ambas fotos, ambas ilustraciones.
El modelo ignora el último fotograma. Esto ocurre cuando el prompt describe un movimiento que no puede terminar lógicamente en tu último fotograma. El modelo prioriza la coherencia del prompt sobre la adherencia al fotograma cuando entran en conflicto. Escribe tu prompt para llegar al último fotograma, no solo para partir del primero.
Preguntas Frecuentes
- ¿Puedo usar primer/último fotograma con texto a video o solo con I2V? El modo FLF2V es una extensión de I2V. Ambas entradas de fotograma son obligatorias. El T2V estándar no acepta restricciones de fotograma final por diseño.
- ¿Qué formato de imagen funciona mejor para las entradas de fotograma? PNG para cualquier cosa que requiera bordes limpios o manejo de transparencia. JPEG de alta calidad (>90 de calidad) está bien para fotografía. Evita WebP si tu plataforma no ha confirmado compatibilidad.
- ¿Esto cuesta más que el I2V estándar? El precio depende de la resolución — 720p cuesta aproximadamente el doble que 480p por generación. FLF2V en sí no tiene un precio adicional en los precios documentados, pero confirma con tu plataforma específica.
- ¿Cómo manejo el movimiento que requiere cambios bruscos de dirección? Divide la secuencia en múltiples clips con fotogramas intermedios como puntos finales. Encadénalos en posproducción en lugar de intentar que una sola generación maneje movimiento discontinuo.
- ¿Puedo combinar esto con el modo de entrada de cuadrícula 9? Estos son modos de entrada separados. WAN 2.7 admite el control de primer/último fotograma y la imagen a video de cuadrícula 9 como características distintas. Actualmente no se combinan en una sola llamada — verifica en el lanzamiento si esto cambia.
Conclusión
El espacio de diseño interesante con el control de primer/último fotograma no es la llamada a la API — es el par de entrada. Ahí es donde está el verdadero apalancamiento en producción, y es donde la mayoría de los equipos invierten poco. Un par de fotogramas bien diseñado con una relación semántica clara superará consistentemente a un prompt perfecto emparejado con una entrada desajustada.
Para equipos que construyen pipelines en lote: trata tu biblioteca de pares de entrada como un activo de primera clase, no como una ocurrencia tardía. Una vez que tengas un seed bloqueado y un formato de par validado, el lado de generación se vuelve rutinario. La comunidad de ComfyUI ha documentado configuraciones de flujo de trabajo WAN FLF2V en detalle si también estás ejecutando inferencia local junto con llamadas a API — vale la pena leerlo por la perspectiva a nivel de nodo sobre cómo funciona realmente el condicionamiento de fotogramas.
Sigo volviendo a algo silencioso aquí: la restricción es la característica. Darle al modelo un destino te obliga a ser preciso sobre lo que realmente quieres. Eso no es una limitación — es una disciplina que tiende a producir mejores resultados que la generación abierta jamás lo hace.
Continúa explorando flujos de trabajo de video con IA:
- Mira cómo el control de primer/último fotograma se compara con otros modelos de generación de video
- Entiende cómo mantener la consistencia de personajes en clips de video generados
- Explora casos de uso del mundo real para la generación de video con IA en flujos de trabajo de producción
- Aprende cómo las entradas de referencia de múltiples imágenes mejoran el control de generación
- Mira cómo los pipelines de imagen a video se usan en diferentes herramientas
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber