Muse Spark vs Llama 4: El Cambio Estratégico de Meta
Meta pasó de Llama de pesos abiertos a Muse Spark cerrado. Qué cambió, por qué importa para los desarrolladores y si las futuras versiones de código abierto son realistas.

Meta acaba de lanzar una nueva serie de modelos. Si has construido algo sobre Llama 4 durante el último año, probablemente te preguntas si seguir adelante o empezar a planificar una migración.
Soy Dora. Ayer pasé el día leyendo cada pieza de documentación que publicó Meta, cruzando referencias con benchmarks de terceros e intentando entender qué significa esto realmente para quienes tienen Llama en su stack. Este artículo desglosa qué cambió, qué no cambió, y en qué posición se encuentran los desarrolladores ahora mismo.
Qué Cambió Entre Llama 4 y Muse Spark
Arquitectura: Nueve Meses, Desde Cero
Meta Superintelligence Labs — la unidad formada tras la incorporación de Alexandr Wang como director de IA en mediados de 2025 — reconstruyó toda la infraestructura de IA desde cero. Nueva infraestructura, nueva arquitectura, nuevas tuberías de datos. Eso no es material de marketing; es lo que afirma el propio blog técnico de Meta. Muse Spark es el primer modelo que sale de esa reconstrucción.
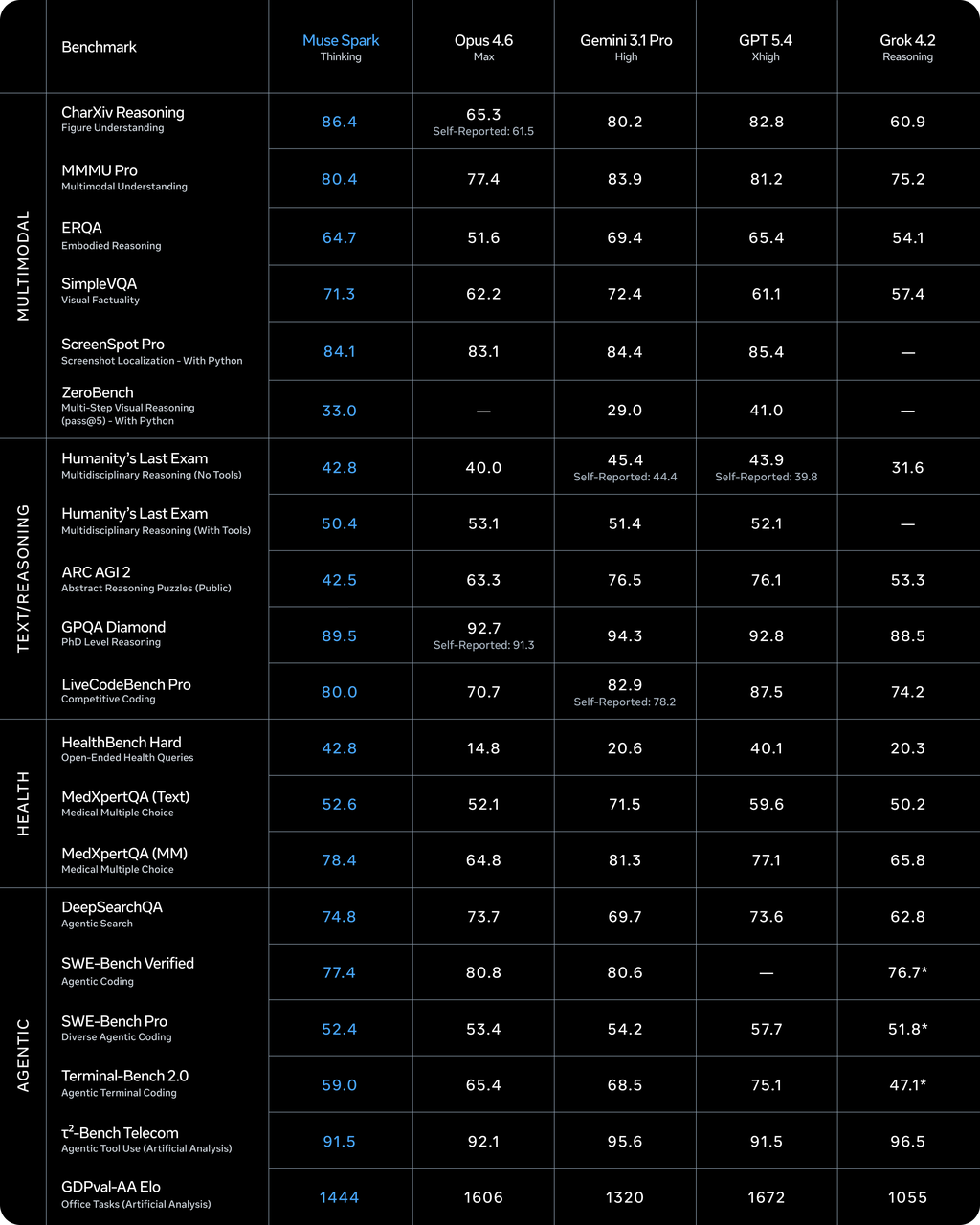
Llama 4 utilizaba una arquitectura de Mixture-of-Experts con pesos abiertos. Muse Spark es un modelo de razonamiento multimodal nativo — lo que significa que la visión no fue añadida posteriormente, sino integrada desde el principio. Admite uso de herramientas, cadena de pensamiento visual y orquestación multiagente. Llama 4 no tenía ninguna de estas capacidades de forma nativa.
El modelo también introduce modos de razonamiento por niveles: Instant para consultas casuales, Thinking para trabajo paso a paso, y un modo Contemplating que ejecuta múltiples subagentes en paralelo. Este último es la respuesta de Meta a Gemini Deep Think y al razonamiento extendido de GPT Pro.
Eficiencia: La Afirmación de Meta, No una Conclusión Independiente
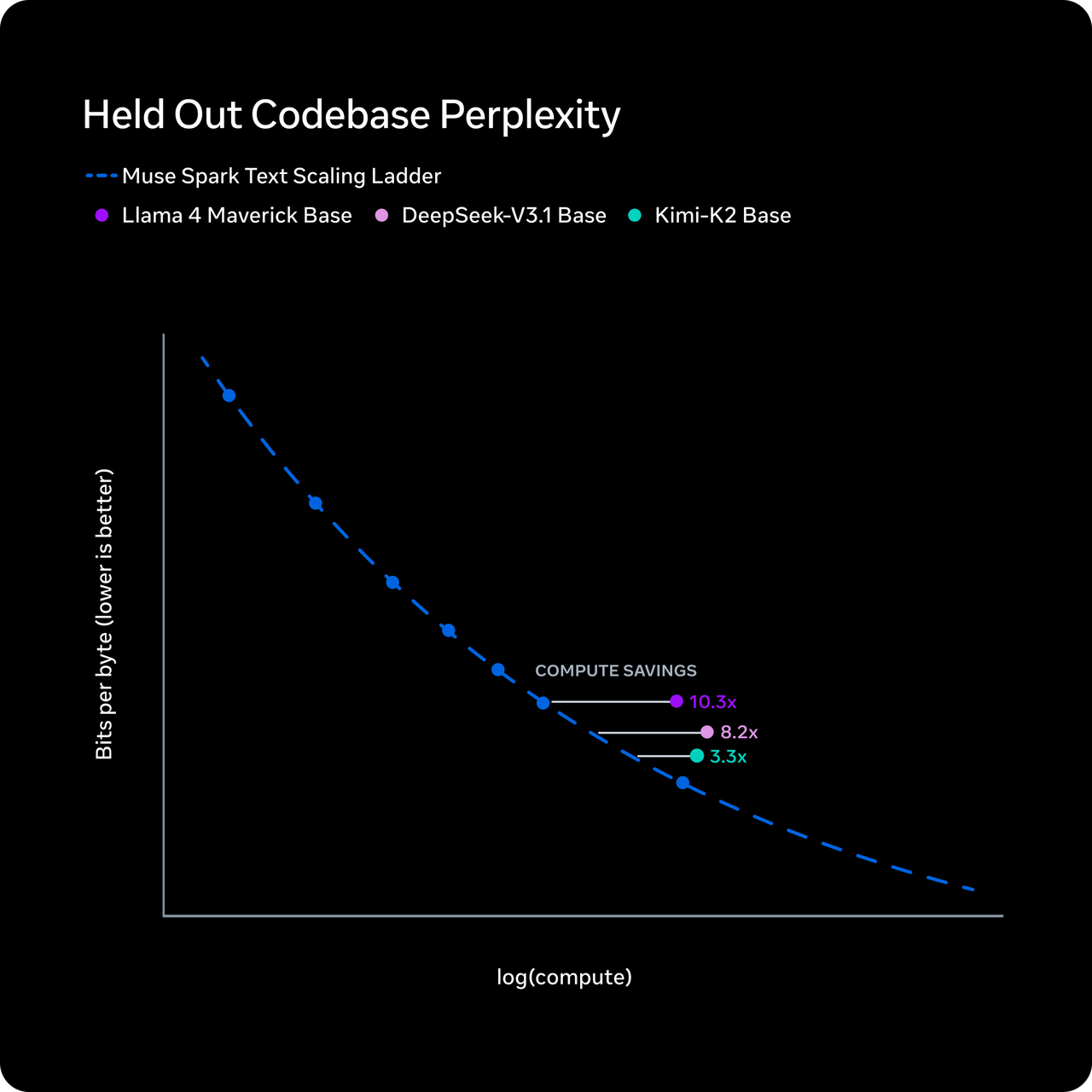
Meta afirma que Muse Spark alcanza el nivel de capacidad de Llama 4 Maverick usando más de diez veces menos cómputo. El mecanismo que describen es la “compresión del pensamiento” — durante el aprendizaje por refuerzo, el modelo es penalizado por tiempos de razonamiento excesivos, lo que lo obliga a razonar con menos tokens sin perder precisión.
Quiero ser preciso aquí: esto es una afirmación de Meta. No ha sido replicado de forma independiente. Los números de eficiencia de tokens de Artificial Analysis sí muestran que Muse Spark utilizó 58 millones de tokens de salida para ejecutar su Intelligence Index completo — comparable a los 57 millones de Gemini 3.1 Pro y muy por debajo de los 157 millones de Claude Opus 4.6 o los 120 millones de GPT-5.4. Así que la historia de eficiencia tiene cierto respaldo independiente, al menos en el lado de la salida.
Brecha en Benchmarks: De 18 a 52
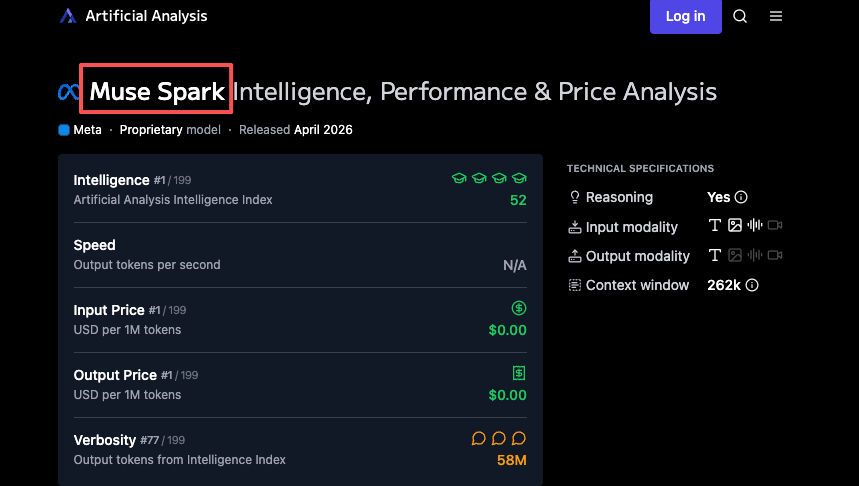
Según Artificial Analysis, Llama 4 Maverick obtuvo 18 en el Intelligence Index en su lanzamiento. Muse Spark obtuvo 52. Eso lo sitúa en cuarto lugar en general — por detrás de Gemini 3.1 Pro Preview y GPT-5.4 (ambos con 57) y Claude Opus 4.6 (53).
Una advertencia importante: Artificial Analysis recibió acceso anticipado de Meta para hacer benchmarks del modelo. Ejecutaron sus propias evaluaciones de forma independiente, pero el acceso en sí llegó a través de Meta. Estos no son aún benchmarks públicos completamente independientes. Las puntuaciones son útiles de forma orientativa, no como verdad absoluta.
Donde Muse Spark lidera: benchmarks de salud (42,8 en HealthBench Hard, por delante del 40,1 de GPT-5.4), razonamiento visual (80,5% en MMMU-Pro, segundo solo detrás de Gemini 3.1 Pro) y comprensión de gráficos.
Donde queda rezagado: programación (Terminal-Bench Hard, por detrás de Claude Sonnet 4.6 y GPT-5.4), tareas agénticas (GDPval-AA 1.427 ELO frente al 1.676 de GPT-5.4) y razonamiento abstracto (ARC-AGI-2 en 42,5 frente a 76+ de los mejores competidores). Meta reconoció explícitamente estas brechas en su blog técnico, afirmando que continúan invirtiendo en “sistemas agénticos de largo horizonte y flujos de trabajo de programación”.
El Cambio de Abierto a Cerrado
El Modelo de Llama: Pesos Abiertos, Ecosistema Comunitario
La propuesta de valor de Llama era sencilla. Descarga los pesos, ejecútalos en tu propio hardware, ajústalos para tu caso de uso, paga solo por el cómputo. El enfoque de pesos abiertos construyó un ecosistema — miles de variantes ajustadas en Hugging Face, implementaciones autoalojadas en startups y empresas, toda una industria artesanal de modelos cuantizados que se ejecutan en GPUs de consumidor. Llama 4 Scout cabe en una sola H100. Maverick se ejecuta en una RTX 5090 con cuantización.
Ese ecosistema sigue existiendo. Esos modelos no han sido retirados.
El Modelo de Muse Spark: Cerrado, Solo Vista Previa Privada de API
Muse Spark es propietario. Sin pesos descargables. Sin autoalojamiento. Ahora mismo impulsa Meta AI en todas las aplicaciones de la empresa — el sitio web de Meta AI, y pronto WhatsApp, Instagram, Facebook, Messenger y las gafas Ray-Ban AI. Los desarrolladores externos pueden solicitar una vista previa privada de la API. Eso es todo.
Esto está más bloqueado que los modelos de OpenAI o Anthropic, que al menos ofrecen acceso público a la API. Como señaló Fortune en su cobertura, Muse Spark es “incluso más propietario que los modelos propietarios de pago que ofrecen los rivales de Meta”.

“Esperamos Hacer Código Abierto de Versiones Futuras”
La entrada del blog de Meta incluye esta frase. Zuckerberg escribió en Threads sobre planes para lanzar “modelos cada vez más avanzados que empujen la frontera de la inteligencia y las capacidades, incluidos nuevos modelos de código abierto”. Wang mencionó en X la posibilidad de publicar versiones futuras como código abierto.
Sin plazos. Sin compromiso específico sobre qué modelo o cuándo. Sin indicación de si “versiones futuras” significa que el propio Muse Spark eventualmente se abre, o si una rama separada de pesos abiertos continúa en paralelo.
Compara esto con el manifiesto de Zuckerberg de 2024 titulado “Open Source AI is the Path Forward”, donde argumentaba que abrir Llama no perjudica los ingresos de Meta. Eso fue hace dieciocho meses. El cálculo estratégico ha cambiado claramente. Como señaló el análisis de The Next Web, el cierre es una señal de que Meta ahora se considera inmersa en una carrera donde regalar innovaciones arquitectónicas cuesta más de lo que gana.
Aquí es donde terminan mis datos. Si los futuros modelos Muse se abren realmente es especulación. Actualizaré cuando haya algo concreto.
Qué Significa Esto para los Desarrolladores que Usan Llama Actualmente
Llama Autoalojado: Sigue Siendo Viable, No Está Obsoleto
Cuando VentureBeat preguntó directamente a Meta si el desarrollo de Llama había terminado, un portavoz dijo: “Nuestros modelos Llama actuales seguirán estando disponibles como código abierto”. Esa frase está cuidadosamente redactada. Confirma que los modelos existentes siguen disponibles. No dice nada sobre el desarrollo futuro de Llama.
Si ejecutas Llama 4 Scout o Maverick en producción hoy, nada ha cambiado operativamente. Los pesos siguen en Hugging Face. Los ajustes de la comunidad siguen funcionando. Tu infraestructura no necesita moverse.
Compensaciones Operativas: Hoy vs. Esperar
Esta es la situación práctica. Si tienes una implementación de Llama que funciona — pipeline de inferencia ajustado, costos predecibles, equipo familiarizado con los parámetros — tienes una cantidad conocida. Los precios de la API de Muse Spark no han sido anunciados. El acceso público a la API no ha sido anunciado. La vista previa privada es solo por invitación.
Cambiar de un modelo de pesos abiertos autoalojado a una API cerrada significa perder control sobre la latencia, el tiempo de actividad, la estructura de costos y el manejo de datos. Para algunos equipos esa compensación tiene sentido. Para otros no. El punto es que ni siquiera puedes evaluar la compensación todavía porque los términos de la API de Muse Spark no existen públicamente.
Flujos de Trabajo de Programación: La Brecha Reconocida
Si tu implementación de Llama maneja generación de código, revisión de código o cualquier tarea orientada al desarrollador, no hay razón para mirar a Muse Spark ahora mismo. Meta lo dijo ellos mismos — la programación es una debilidad actual. En Terminal-Bench Hard, Muse Spark queda por detrás de Claude Sonnet 4.6 y GPT-5.4. En GDPval-AA, que mide tareas de trabajo del mundo real, obtiene 1.427 ELO frente al 1.648 de Claude Sonnet 4.6.
Funciona para mi frecuencia. La tuya puede diferir. Pero los datos son claros en este punto.
Por Qué Meta Hizo Este Movimiento
Llama 4: El Tropiezo Reconocido
Llama 4 se lanzó en abril de 2025 con una recepción mixta. La controversia de los benchmarks — Meta utilizó una “versión de chat experimental” especializada y no publicada para impulsar las puntuaciones en LMArena — dañó la credibilidad. Los modelos en sí eran sólidos para su clase de peso, pero no movieron la frontera. A mediados de 2025, la narrativa era que Meta había quedado rezagada respecto a OpenAI, Anthropic y Google.
El Mandato de Wang
En junio de 2025, Meta gastó $14.300 millones para adquirir una participación no votante del 49% en Scale AI y trajo al cofundador Alexandr Wang como director de IA. El mandato era explícito: ponerse al día. Se formó Meta Superintelligence Labs. Se contrataron investigadores de OpenAI, Anthropic y Google con paquetes salariales que supuestamente alcanzaban cientos de millones cuando se incluía el capital.
Nueve meses después, Muse Spark es el primer resultado. Si justifica la inversión depende de lo que venga después — este modelo es deliberadamente pequeño y rápido, con versiones más grandes ya en desarrollo.
Presión Competitiva
La matemática es simple. OpenAI y Anthropic tienen una valoración combinada superior al billón de dólares. Gemini de Google ha ganado tracción tanto en mercados de consumo como de desarrolladores. Meta estaba gastando $72.000 millones en infraestructura de IA en 2025, con previsión de subir a $115-135.000 millones en 2026, y no tenía ningún modelo competitivo en la frontera que mostrar. Algo tenía que cambiar.
Marco de Decisión para Desarrolladores
Quédate con Llama Si:
Necesitas pesos abiertos — para autoalojamiento, ajuste fino, cumplimiento en instalaciones propias o control de costos. Estás ejecutando flujos de trabajo intensivos en programación donde Muse Spark tiene brechas reconocidas. Necesitas infraestructura predecible y autogestionada que no dependa de una lista de espera de API privada. Ya has invertido en herramientas específicas de Llama (pipelines de cuantización, adaptadores LoRA, evaluaciones personalizadas).
Observa Muse Spark Si:
Estás construyendo dentro del ecosistema de productos de Meta — cualquier cosa que se integre con Instagram, WhatsApp, Facebook o Messenger. Necesitas una comprensión multimodal sólida, particularmente razonamiento visual o tareas relacionadas con la salud. Estás dispuesto a esperar el acceso público a la API y puedes evaluar una vez que los precios y términos estén disponibles.
Ninguno Cubre:
Generación de imágenes. Generación de vídeo. Estas son categorías de modelos separadas. Muse Spark es solo de salida de texto, y Llama 4 es solo de salida de texto. Si necesitas capacidades de generación, estás mirando herramientas completamente diferentes.
Preguntas Frecuentes

¿Puedo seguir usando Llama 4 después del lanzamiento de Muse Spark?
Sí. Llama 4 Scout y Maverick siguen disponibles en Hugging Face y a través de los socios de API de Meta. Nada ha sido obsoleto ni retirado.
¿Publicará Meta los pesos de Muse Spark?
Meta dijo que “espera hacer código abierto de versiones futuras del modelo”. No hay plazos, ningún compromiso específico sobre el propio Muse Spark, y ninguna indicación de qué significa “versiones futuras” en la práctica. Trátalo como aspiración, no como plan.
¿Es Muse Spark mejor que Llama 4 para programación?
No. Meta reconoce explícitamente la programación como una brecha actual. En benchmarks específicos de programación, Muse Spark queda por detrás de Claude Sonnet 4.6 y GPT-5.4. Si la programación es tu caso de uso principal, Llama 4 Maverick con ajuste fino o un modelo de programación de propósito específico es una mejor opción hoy.
¿Cuándo llega el próximo modelo Muse?
Meta describió Muse Spark como “el primer paso” con “modelos más grandes ya en desarrollo”. Sin fechas. Sin nombres. Sin especificaciones más allá de confirmar que existen.
¿Afecta esto al ecosistema más amplio de IA de código abierto?
Es una señal, no un golpe mortal. Los modelos Llama de pesos abiertos de Meta siguen disponibles. Otras organizaciones — Mistral, DeepSeek, Qwen de Alibaba — continúan lanzando modelos abiertos. Pero Meta era el mayor patrocinador corporativo único de modelos de frontera de pesos abiertos. Si su inversión en la frontera se desplaza permanentemente hacia modelos cerrados, el ecosistema pierde a su contribuidor con mayor financiación. Eso importa a lo largo de años, no de semanas.
Eso es todo. Más actualizaciones cuando la API sea pública.
Artículos anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado

API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción

Precios de GPT-5.4 Mini: Costos de entrada, caché y salida

API de MAI-Image-2.5: Lo que los desarrolladores deben saber
