Guía de la API GPT Image 2 para Generación y Edición
Una guía práctica de la API GPT Image 2 para desarrolladores que cubre generación, edición, diseño de flujos de trabajo y consideraciones comunes de implementación.

La semana pasada lancé una pequeña funcionalidad de producto que necesitaba generación de imágenes detrás de un botón. A los dos días de desarrollo, me di cuenta de que las decisiones de integración que tomé el primer día iban a definir cuánto dolor cargaría durante los próximos seis meses. Eso es lo que nadie te advierte sobre la API de GPT Image 2. El hello-world es fácil. La postura en producción es donde se pone interesante.
Soy Dora. Escribo notas de trabajo después de lanzar cosas, no antes. Esto es lo que aprendí al conectar OpenAI’s gpt-image-2 a un producto real, y lo que le diría a otro desarrollador o equipo de ingeniería de IA que considere antes de que salga la primera solicitud.
Qué Necesitas Antes de Usar la API de GPT Image 2
Acceso al modelo, endpoints y documentación clave
GPT Image 2 se lanzó el 21 de abril de 2026. El ID del modelo es gpt-image-2. Antes de tu primera llamada es posible que necesites completar la Verificación de Organización API en la consola de desarrollador — OpenAI restringe el acceso a la familia GPT Image detrás de ella.
Tienes tres superficies para elegir. La Image API expone dos endpoints: images.generate para texto a imagen e images.edit para modificar imágenes existentes con un prompt y máscara opcional. La tercera superficie es la Responses API, que expone la generación de imágenes como una herramienta integrada para flujos conversacionales o de múltiples pasos.
Elige según el trabajo, no por novedad. Si tu producto es “el usuario escribe un prompt y obtiene una imagen,” usa la Image API. Si tu producto es “el usuario tiene una conversación de ida y vuelta que a veces produce imágenes,” usa la Responses API. Mezclarlas porque una parece más sofisticada que la otra es una trampa de mantenimiento.
Lo que GPT Image 2 soporta hoy
Dos cosas para interiorizar pronto.
No soporta fondos transparentes. Las solicitudes con background: "transparent" fallarán. Si necesitas PNGs transparentes, dirige esas tareas a gpt-image-1.5 y acepta que ahora mantienes dos rutas de modelo.
La fidelidad de entrada está bloqueada. El parámetro input_fidelity existe en modelos más antiguos, pero gpt-image-2 siempre procesa las entradas con alta fidelidad. Omite el parámetro o tu solicitud fallará. La implicación de costo: las solicitudes de edición con imágenes de referencia consumen más tokens de entrada de lo que podrías esperar de tus días con gpt-image-1.
Cómo Generar Imágenes con GPT Image 2
Estructura básica de solicitud y opciones de salida
Una solicitud de generación toma un prompt, un tamaño, una calidad y un formato de salida. El formato predeterminado es PNG; puedes solicitar JPEG o WebP, y JPEG es más rápido que PNG cuando importa la latencia. El tamaño acepta presets o dimensiones personalizadas, con la restricción de que ambos lados deben ser múltiplos de 16, el lado máximo es de 3840 px, la relación de aspecto menor a 3:1, y el total de píxeles entre 655.360 y 8.294.400.
El parámetro n te permite generar múltiples imágenes en una sola solicitud. Útil cuando necesitas variaciones para comparar. Menos útil cuando pagas por token de salida — que es lo que haces.
Gestión de tamaño, calidad y compensaciones de flujo de trabajo
Aquí es donde la mayoría de los equipos gastan dinero sin darse cuenta. GPT Image 2 se factura por token, no por imagen: entrada de imagen $8 por 1M tokens, salida de imagen $30 por 1M tokens, entrada de texto $5 por 1M tokens. Las entradas en caché son más baratas. El procesamiento por lotes reduce a la mitad las tarifas estándar.
Lo que eso significa en números prácticos: a 1024x1024, la calculadora de OpenAI estima aproximadamente $0,006 para calidad baja, $0,053 para media y $0,211 para alta. Los tamaños rectangulares como 1024x1536 son ligeramente más baratos: $0,005, $0,041 y $0,165. Esas son estimaciones solo de salida. Suma tokens de entrada y tokens de referencia de edición encima.
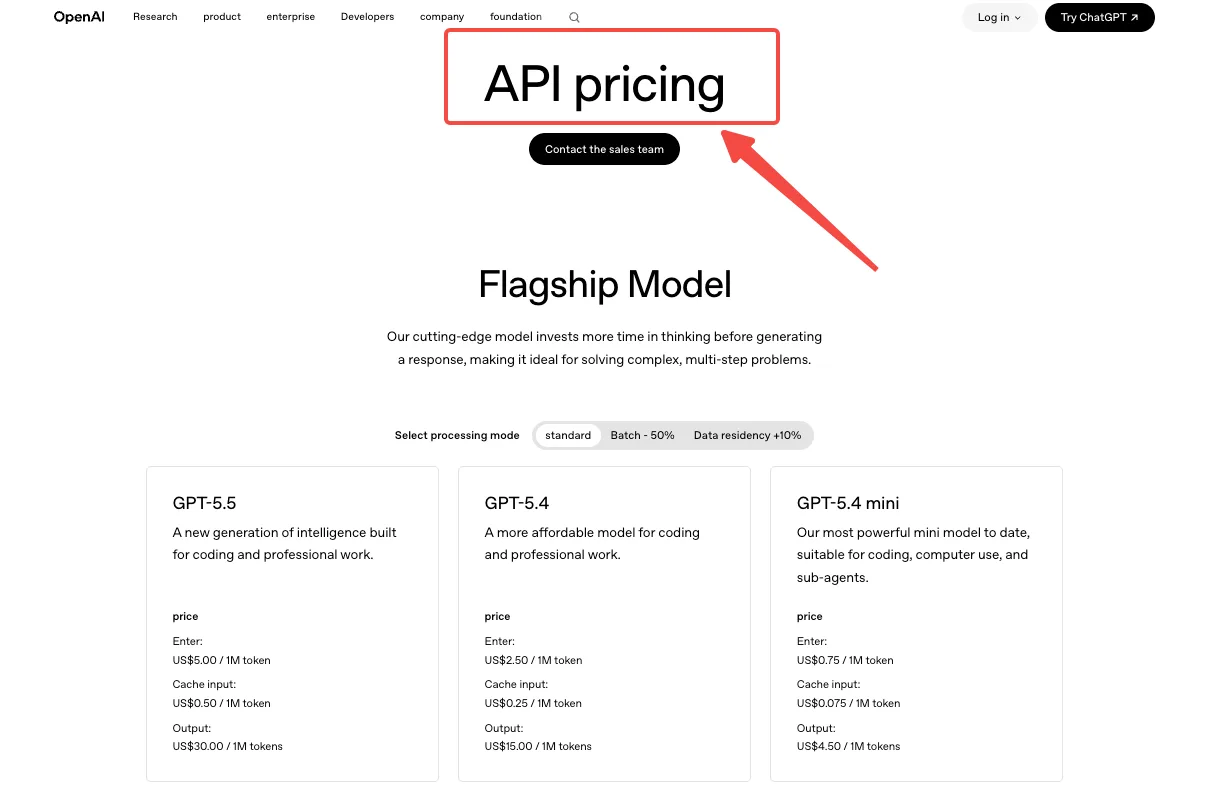
Entonces la pregunta de compensación no es qué calidad se ve mejor. Es: a mi volumen, ¿cuál es la diferencia de costo entre media y alta, y mi usuario realmente lo percibe? Para una superficie de miniaturas, la calidad baja suele ser suficiente. Para una imagen principal que los usuarios contemplarán, la alta vale su precio. Elegí media como predeterminado y expuse alta como opción habilitada por el usuario. Esa única decisión cambió mi factura mensual proyectada en aproximadamente 4x.
Cómo Funciona la Edición de Imágenes
Requisitos de entrada y escenarios de edición comunes
El endpoint de edición toma una imagen, una máscara opcional y un prompt que describe el cambio. Pasa una imagen para editarla. Pasa múltiples imágenes para combinar sujetos, estilos o referencias en una sola salida. El modelo maneja inpainting y outpainting, y preserva las regiones no enmascaradas mientras aplica tu prompt al resto.
Ediciones comunes que he validado: cambio de fondo en fotos de productos, eliminación de objetos, transferencia de estilo entre dos imágenes de referencia y traducción de texto dentro de una imagen. La afirmación de consistencia de personaje — el mismo personaje en múltiples escenas generadas — funciona para mí con sujetos simples. Se vuelve menos confiable a medida que crece la complejidad de la escena.
Errores que aumentan el costo o reducen la consistencia
Enviar entradas de tamaño excesivo. Dado que GPT Image 2 procesa cada entrada de imagen con alta fidelidad, una foto de referencia 4K cuesta los mismos tokens de entrada ya sea que tu salida sea una miniatura o un póster. Reduce las referencias al nivel que la tarea realmente necesita.
Prompts de edición vagos. “Mejóralo” produce cambios impredecibles y a menudo te cuesta un reintento. “Cambia el sombrero rojo a terciopelo azul claro” preserva el resto de la imagen y generalmente lo logra en un solo intento.
n sin límite. Pedir n=4 para “ver opciones” parece inofensivo hasta que te das cuenta de que acabas de pagar 4x por una solicitud de la que solo usarás una salida.
Tratar las ediciones como generaciones para estimar costos. Las ediciones a menudo cuestan más que las generaciones del mismo tamaño de salida, porque las imágenes de referencia agregan tokens de entrada. Planifica eso en tu modelo de precios antes del lanzamiento, no después.
Consideraciones de Producción para Equipos
Reintentos, moderación y controles operativos
Tres cosas que no son opcionales en producción.
Reintentos con retroceso exponencial. La generación de imágenes puede tardar hasta 2 minutos para prompts complejos, y encontrarás límites de velocidad. La guía de OpenAI es reintentar con retroceso exponencial más jitter — el jitter importa porque los reintentos sincronizados de una flota golpean el mismo techo de velocidad al mismo tiempo.
Moderación, en dos capas. El endpoint de generación de imágenes tiene un parámetro moderation integrado (auto es el predeterminado; low es permisivo pero aún filtrado). Para prompts enviados por usuarios, ejecútalos a través del endpoint gratuito omni-moderation-latest antes de enviarlos a gpt-image-2 — acepta tanto texto como imágenes, y detiene la mayoría de las solicitudes que violan políticas antes de que pagues por la generación. La referencia de la API de moderaciones tiene la forma exacta de la solicitud.
Registro en el grano correcto. Registra el ID del modelo, tamaño, calidad, recuento de tokens de entrada y salida, latencia, ID de solicitud y estimación de costo final por solicitud. Cuando algo sale mal a escala, estos son los datos que te permiten diagnosticarlo. Cuando algo sale bien, son los datos que te permiten decidir si escalar más. Fija un snapshot de modelo específico en producción en lugar del alias flotante, para que el comportamiento no cambie sin que te des cuenta. La guía de mejores prácticas de producción cubre la rotación de claves, el monitoreo y el resto de la capa operativa.
Cuándo mantener la integración directa simple vs agregar una capa de plataforma
Esta es la pregunta con la que más tiempo estuve.
La integración directa con OpenAI es la respuesta correcta cuando tu producto usa un modelo de imagen, tu equipo tiene experiencia en operaciones de API, y tu tráfico es lo suficientemente predecible como para que la propiedad de los límites de velocidad y la facturación de primera parte importen más que la conveniencia.
Una capa de plataforma — y sí, trabajo en una en WaveSpeedAI — gana su lugar en situaciones diferentes. Estás enrutando entre múltiples modelos de imagen (gpt-image-2 para tipografía, un modelo diferente para PNGs transparentes, otro para video). Necesitas precios planos por llamada para la previsibilidad del presupuesto en lugar de cálculos de tokens. Quieres una única superficie de integración que sobreviva a los cambios de proveedor sin que tengas que reescribir tus puntos de llamada.
Ninguna respuesta es universal. La prueba honesta: cuenta cuántos proveedores de modelos llama tu producto hoy, multiplica por cuántos llamarás en doce meses, y pregúntate si quieres mantener tú mismo tantas integraciones.
Preguntas Frecuentes
¿Qué endpoint deben usar los desarrolladores para GPT Image 2?
Usa images.generate para texto a imagen, images.edit para modificar una imagen existente con un prompt y máscara opcional, y la herramienta de imagen de la Responses API cuando la generación necesita vivir dentro de una conversación de múltiples turnos.
¿GPT Image 2 soporta ediciones de imágenes?
Sí. El endpoint images.edit acepta una o más imágenes de referencia más un prompt, y soporta inpainting y outpainting enmascarados. Todas las entradas de imagen se procesan automáticamente con alta fidelidad.
¿Qué deben registrar y monitorear los equipos en producción?
Como mínimo: ID de snapshot del modelo, tamaño, calidad, recuentos de tokens de entrada y salida, latencia, ID de solicitud, recuento de reintentos, resultado de moderación y costo estimado final por solicitud. Esto es lo que te permite reconstruir cualquier incidente y pronosticar el gasto.
¿Cuándo deja de ser suficiente una integración API simple?
Cuando llamas a más de un proveedor de imágenes, cuando los modos de fallo necesitan respaldo entre proveedores, o cuando finanzas pide precios predecibles por llamada en lugar de variabilidad basada en tokens. Por debajo de esos umbrales, la integración directa sigue siendo la opción más limpia.
¿Cómo evito que la inyección de prompts y las salidas inseguras lleguen a producción?
Ejecuta los prompts de usuarios a través del endpoint de moderación antes de la generación, establece el parámetro moderation de la image API en auto, registra cada solicitud marcada, y sigue las mejores prácticas de seguridad de OpenAI — incluyendo revisión humana para superficies de alto riesgo y red-teaming antes del lanzamiento.
Conclusión
La API de GPT Image 2 no es difícil de conectar. La primera solicitud lleva una tarde. Las decisiones que importan — valores predeterminados de calidad, modelado de costos de edición, capas de moderación, comportamiento de reintentos, si agregar una capa de plataforma — son las que se acumulan silenciosamente durante meses después de que lanzas. Elígelas deliberadamente. Ejecuta primero el pequeño piloto. El resto sigue.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber