Godmod3 AI Explicado: Chat Multi-Modelo Sin Restricciones
Godmod3 te permite ejecutar más de 50 modelos de IA en paralelo con una sola clave de OpenRouter — sin instalación, sin servidor, sin cuenta. Esto es lo que significa en la práctica.

Construí un flujo de trabajo a su alrededor antes de entender completamente qué era. Así suele pasar.
La semana pasada tenía tres pestañas abiertas: Claude en una, GPT-5 en otra, Gemini en una tercera, copiando y pegando el mismo prompt en cada una para descubrir cuál modelo manejaba mejor una comparación técnica matizada. La fricción era evidente: tres sesiones de inicio de sesión, tres paneles de parámetros, tres cuentas de facturación, cero formato de salida estandarizado. Soy Dora, que ha realizado este tipo de evaluación multi-modelo decenas de veces, y tengo una nota en mi registro de trabajo: “el costo de cambiar es invisible hasta que lo haces cincuenta veces a la semana.” Entonces se vuelve muy visible.
Ese es el problema que resuelve godmod3.ai. Un prompt. Múltiples modelos. Un ganador con puntuación. Esto es lo que realmente necesitas saber antes de decidir si pertenece a tu flujo de trabajo.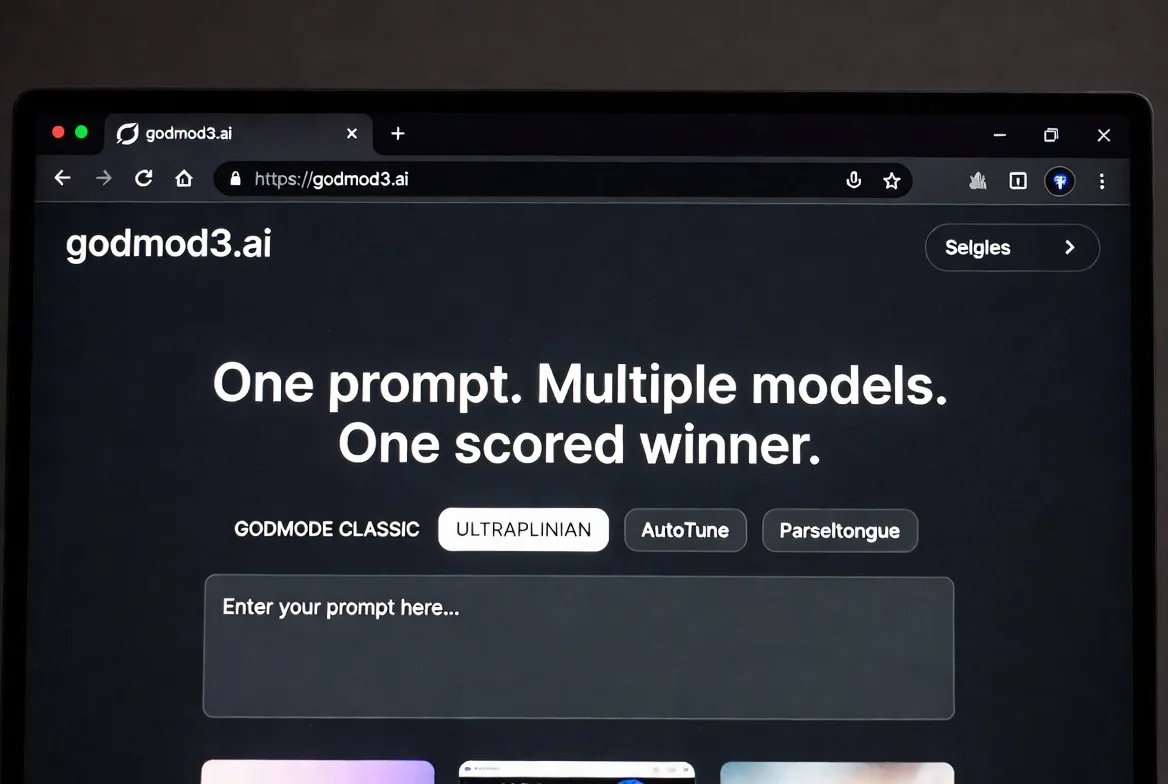
Godmod3 vs Tu Configuración Actual de Chat con IA
El problema del modelo único: por qué cambiar de pestaña entre ChatGPT y Claude no es suficiente
El problema no es que ChatGPT o Claude sean malos. Es que usar un modelo a la vez te obliga a confiar en el juicio de ese modelo sin un punto de comparación. Escribes un prompt, obtienes una respuesta y la aceptas o la reformulas. No sabes si otro modelo lo habría resuelto a la primera.
Cambiar de pestaña para averiguarlo es lento. Cada plataforma tiene su propia configuración de parámetros, su propio comportamiento de ventana de contexto, su propia forma de interpretar la misma instrucción. Para cuando has comparado tres respuestas, has gastado más tiempo en el proceso que en la tarea real.
Lo que te ofrece godmod3.ai: un prompt, múltiples modelos, un ganador
Godmod3 envía tu prompt a múltiples modelos simultáneamente y devuelve los resultados en paralelo. En su modo ULTRAPLINIAN, puntúa las respuestas en una métrica compuesta de 100 puntos y muestra automáticamente la respuesta mejor clasificada. No estás leyendo cinco pestañas — estás leyendo el veredicto.
Toda la interfaz es una aplicación de navegador de una sola página construida por Pliny (elder-plinius) bajo la licencia AGPL-3.0. No se requiere servidor backend para la versión hospedada básica. Tu clave API permanece en el localStorage de tu navegador. Godmod3 no almacena tus conversaciones en ningún servidor — cierra la pestaña y desaparecen.
La dependencia de OpenRouter explicada de forma sencilla
Godmod3 no se conecta directamente a OpenAI, Anthropic o Google. Enruta todo a través de OpenRouter, una puerta de enlace API unificada que proporciona acceso a más de 300 modelos de múltiples proveedores con una sola clave. Pagas a OpenRouter por token, no a godmod3. La herramienta en sí es gratuita. OpenRouter es la capa de facturación, el catálogo de modelos y la infraestructura de enrutamiento, todo a la vez.
Tres Formas de Acceder a Godmod3
Versión hospedada en godmod3.ai — sin instalación, lleva tu clave de OpenRouter
Ve a godmod3.ai, pega tu clave API de OpenRouter en la configuración y empieza a escribir prompts. Eso es todo. Sin descargas, sin Docker, sin npm install. La versión hospedada elimina por completo la función opcional de recopilación de datos — es una interfaz de chat puramente del lado del cliente.
Lo estaba usando a los 60 segundos de llegar a la página. La fricción fue casi nula, lo cual es raro en las herramientas de IA de código abierto.
Archivo único autoalojado — clona y abre index.html
Toda la aplicación cabe en un solo archivo index.html. Clona el repositorio de GitHub, abre index.html en un navegador, listo. O ejecuta python3 -m http.server 8000 si quieres un servidor local. Sin pasos de compilación, sin instalación de dependencias, sin archivo de configuración.
Esto importa si quieres inspeccionar exactamente qué código se está ejecutando antes de pegar una clave API. La licencia AGPL-3.0 — reconocida por la Open Source Initiative como una licencia de software libre — significa que el código fuente es completamente auditable.
Despliegue estático — GitHub Pages, Vercel o Netlify en menos de 5 minutos
Dado que es un único archivo HTML, desplegarlo en cualquier plataforma de alojamiento estático es trivial. Sube a un repositorio de GitHub, habilita GitHub Pages y tu instancia personal de godmod3 estará disponible en una URL que controlas. Lo mismo con Vercel o Netlify — importa el repositorio y despliega. Sin funciones serverless, sin variables de entorno (más allá de tu clave API, que permanece del lado del cliente).
Probé la ruta de GitHub Pages. Tardé unos tres minutos desde el fork hasta la URL activa.
Los Cuatro Modos Explicados
GODMODE CLASSIC — el modo de carrera en paralelo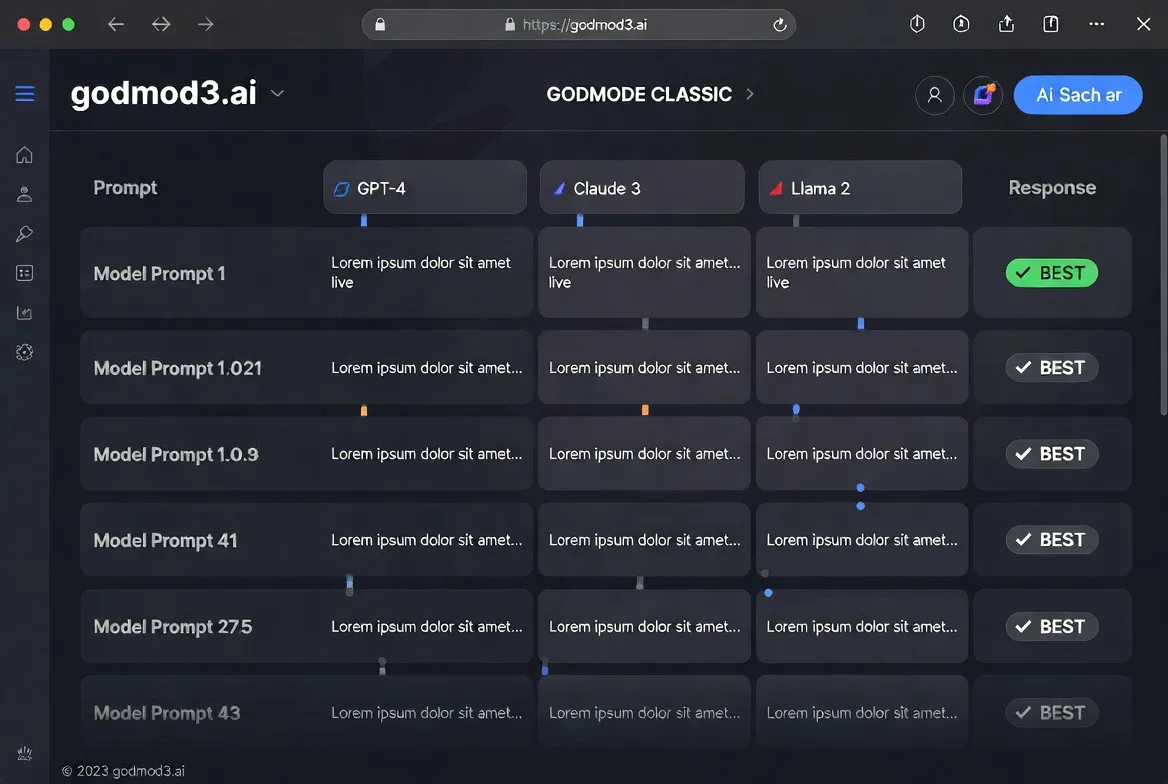
El modo original. Cinco combinaciones de modelo-prompt se ejecutan en paralelo, cada una emparejando un modelo específico con un prompt de sistema ajustado. Las respuestas compiten y la interfaz muestra la mejor. Es rápido y tiene opinión propia — estás confiando en las configuraciones predeterminadas en lugar de elegir los modelos tú mismo.
Ideal para comparaciones rápidas cuando no quieres pensar en el ajuste de parámetros. Menos útil cuando necesitas control específico del modelo.
ULTRAPLINIAN — evaluación profunda multi-modelo para comparaciones serias
Este es el modo que me hizo pausar. Puede consultar hasta 51 modelos en paralelo, puntuar cada respuesta en una métrica compuesta y clasificarlas. La puntuación tiene en cuenta la relevancia, coherencia y calidad de la respuesta. Para los ingenieros de prompts que prueban cómo diferentes modelos manejan la misma instrucción, aquí es donde reside el verdadero valor.
No es barato, sin embargo. Ejecutar 51 modelos en paralelo significa 51 llamadas API separadas, cada una facturada a través de OpenRouter. Ejecuté un prompt de complejidad media a través de una configuración de 10 modelos y el costo fue modesto — unos pocos centavos. Con 51 modelos, se acumula.
AutoTune — por qué ya no necesitas configurar manualmente la temperatura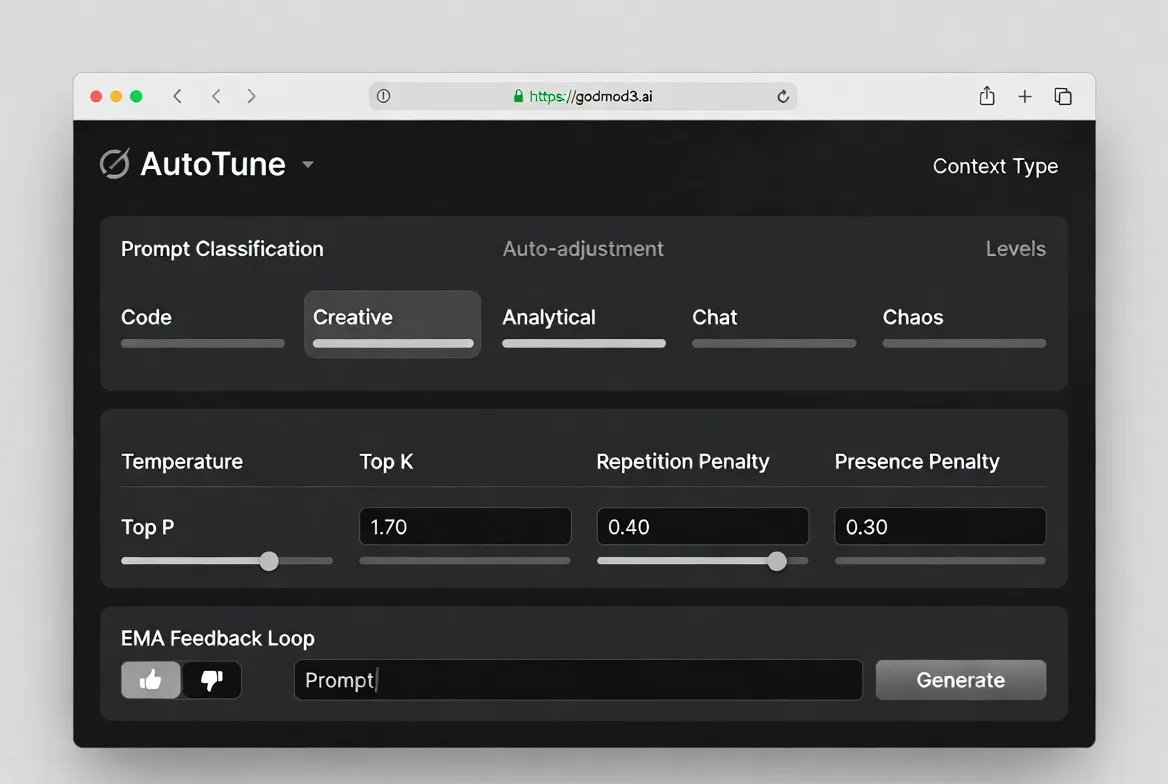
AutoTune clasifica tu prompt en uno de cinco tipos de contexto — código, creativo, analítico, chat o caos — y ajusta automáticamente la temperatura, top_p, top_k y los parámetros de penalización. Utiliza un bucle de retroalimentación basado en EMA: pulgar arriba o abajo en una respuesta refina la selección futura de parámetros.
Todavía no estoy completamente segura de cuánta diferencia hace esto frente a configurar manualmente la temperatura a 0.7 y dejarlo así. Después de una semana de uso, las elecciones de parámetros parecían razonables pero no dramáticamente mejores que mis valores predeterminados. Esta conclusión tiene fecha de caducidad — el bucle de retroalimentación necesita más datos para converger.
Parseltongue — perturbación de entrada para investigadores de seguridad (y para qué no es)
Parseltongue es un módulo de investigación red-team. Detecta palabras desencadenadoras y aplica transformaciones a nivel de carácter — leetspeak, sustitución Unicode, codificación fonética — para estudiar cómo los modelos responden a entradas adversariales. El artículo de investigación del proyecto lo enmarca explícitamente como una herramienta de evaluación de seguridad de IA para probar la robustez del modelo en tiempo de inferencia.
Esto no es una herramienta de evasión de contenido. Está diseñada para investigación controlada sobre cómo las capas de seguridad responden a la perturbación de entrada. La distinción importa. Si tu caso de uso es “quiero engañar a una IA para que diga algo que no debería”, eso no es para lo que está construido este módulo, y la documentación del proyecto lo dice directamente.
Acceso a Modelos a Través de OpenRouter
Qué modelos están disponibles
A través de OpenRouter, godmod3 puede acceder a Claude, GPT-4o, Gemini, Grok, Mistral, Llama, DeepSeek, Qwen y docenas más. El catálogo de modelos de OpenRouter lista más de 300 opciones de más de 60 proveedores a abril de 2026. No todos son útiles para cada tarea, pero la amplitud significa que es poco probable que encuentres un muro de “modelo no disponible”.
Realidad de precios: pagas a OpenRouter por token, no a godmod3
Godmod3 en sí es gratuito. Tus costos provienen de la facturación por token de OpenRouter, que transfiere los precios de cada proveedor a tasas iguales o cercanas a las de la API directa. Ejecutar un prompt a través de un modelo cuesta lo mismo que llamar directamente a la API de ese modelo. Ejecutarlo a través de diez modelos cuesta diez veces eso.
La página de precios de OpenRouter desglosa las tarifas por token por modelo. No hay tarifa mensual, no hay gasto mínimo. Añades créditos y se van agotando a medida que los usas.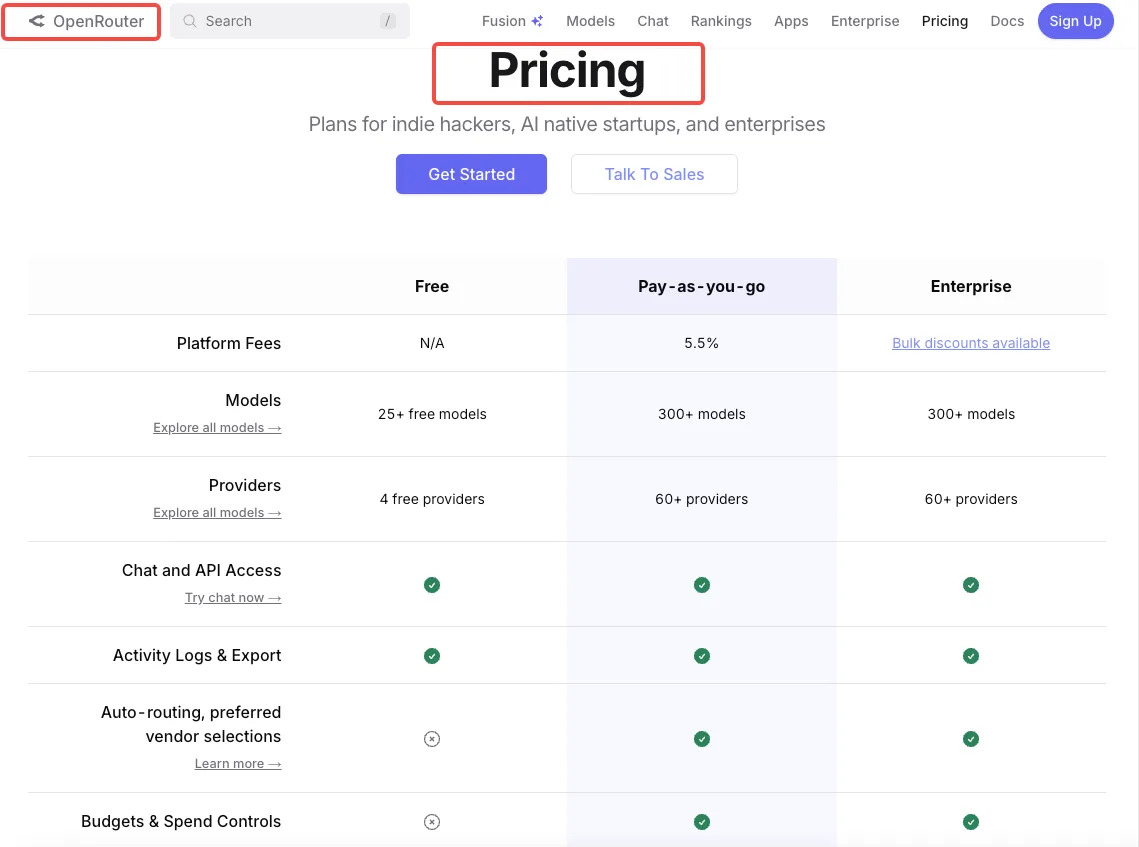
Modelos gratuitos en OpenRouter que puedes usar con godmod3 hoy
OpenRouter mantiene una colección de modelos gratuitos — actualmente alrededor de 29 opciones incluyendo DeepSeek R1, Llama 3.3 70B, Qwen3 Coder y varias variantes de Gemma. Los modelos gratuitos tienen límites de velocidad (típicamente 20 solicitudes por minuto, 200 por día) pero no requieren créditos.
Para probar si godmod3 se adapta a tu flujo de trabajo antes de comprometer dinero, el nivel gratuito es suficiente para formarse una opinión.
Lo Que Godmod3 No Es
No es un backend — el historial de chat vive solo en tu navegador
No hay cuenta, no hay sincronización en la nube, no hay almacenamiento del lado del servidor. Borra los datos de tu navegador y tus conversaciones desaparecen permanentemente. Cambia de dispositivo y nada te sigue. El modo de navegación privada descarta todo al cerrar la ventana.
Esto es una característica de privacidad, no una limitación — pero significa que godmod3 es un bloc de notas, no una base de conocimientos.
No es un reemplazo para las API de producción
Si estás construyendo un producto que llama a LLMs, necesitas integración directa de API con lógica de reintentos, manejo de errores y gestión de límites de velocidad. Godmod3 es una interfaz de investigación y evaluación, no infraestructura de producción. La propia documentación del proyecto es clara al respecto.
No es una herramienta de evasión — el propósito de Parseltongue en la investigación de seguridad de IA
Vale la pena repetirlo: Parseltongue existe para estudiar la robustez del modelo bajo condiciones controladas. El proyecto se posiciona dentro del panorama más amplio de investigación en seguridad de IA junto con marcos como Constitutional AI y RLHF. Proporciona herramientas de evaluación en tiempo de inferencia, no modificaciones en tiempo de entrenamiento. El riesgo de doble uso se reconoce en la documentación, y los usuarios son responsables del cumplimiento de la ley local.
Quién Obtiene Más Valor de Godmod3
Ingenieros de prompts que necesitan comparación rápida multi-modelo
Si estás probando cómo funciona un prompt en Claude, GPT-4o y Gemini antes de comprometerte con uno, godmod3 comprime ese flujo de trabajo de “tres pestañas, tres inicios de sesión, comparación manual” a “un prompt, una pantalla, resultados clasificados”. Ese es el valor central.
Desarrolladores que evalúan qué LLM se adapta a su caso de uso antes de comprometerse con una API
Antes de integrar una API y construir alrededor de sus peculiaridades, quieres saber: ¿maneja bien este modelo mi caso de uso? Ejecutar los mismos prompts de prueba a través de 5-10 modelos en paralelo te da una matriz de comparación en minutos, no días.
Investigadores que realizan estudios controlados de comportamiento de LLM
La combinación de AutoTune (variación de parámetros), Parseltongue (perturbación de entrada) y ULTRAPLINIAN (puntuación multi-modelo) crea un pipeline de evaluación estructurado. Para investigadores académicos o industriales que estudian cómo responden los modelos bajo diferentes condiciones, este es un conjunto de herramientas listo para usar que no requiere construir infraestructura personalizada.
Preguntas Frecuentes
¿Es godmod3.ai lo mismo que G0DM0D3 en GitHub?
Sí. “Godmod3” y “G0DM0D3” se refieren al mismo proyecto. La versión hospedada en godmod3.ai ejecuta el mismo código base que el repositorio de GitHub. La principal diferencia es que la versión hospedada no incluye la función de recopilación de datos opt-in — eso solo está disponible cuando se autoaloja con el servidor API completo basado en Docker.
¿Necesito pagar para usar godmod3?
La herramienta en sí es gratuita. Necesitas una clave API de OpenRouter, y OpenRouter cobra por token cuando usas modelos de pago. Puedes usar modelos gratuitos en OpenRouter sin costo alguno, sujeto a límites de velocidad. Sin suscripción, sin tarifa de plataforma de godmod3.
¿Está segura mi clave API en godmod3.ai?
Tu clave de OpenRouter se almacena en el localStorage de tu navegador y se envía directamente a la API de OpenRouter. Nunca toca un servidor de godmod3. Dicho esto, estás confiando en que el código del lado del cliente no la exfiltre — por eso importa el código base de código abierto. Puedes auditarlo tú mismo o autoalojarlo para tener control total.
¿Puedo usar godmod3 sin una cuenta de OpenRouter?
No. OpenRouter es la capa de enrutamiento para todo el acceso a modelos. Necesitas una cuenta de OpenRouter y una clave API. La creación de cuenta es gratuita y no requiere tarjeta de crédito si solo usas modelos gratuitos.
¿Qué pasa con mi historial de chat si cierro el navegador?
Permanece en localStorage hasta que borres los datos del navegador. Pero no hay copia de seguridad, no hay sincronización, no hay recuperación. Si necesitas conservar una conversación, cópiala manualmente antes de cerrar la pestaña.
He estado usando godmod3 durante unos diez días. No ha reemplazado mis suscripciones directas a Claude o GPT — estas todavía importan para flujos de trabajo conversacionales largos donde la continuidad del contexto cuenta. Pero para la tarea específica de “qué modelo maneja mejor este prompt”, redujo mi tiempo de comparación de minutos a segundos.
Eso es todo lo que puedo confirmar. El resto tendrás que verificarlo tú mismo.
Publicaciones anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber