Rendimiento de Codificación de Claude Mythos: Lo Que Significa para los Flujos de Trabajo de Desarrollo con IA
Se informa que Claude Mythos obtiene puntuaciones dramáticamente más altas en codificación que Opus 4.6. Esto es lo que significa para los desarrolladores que crean agentes de codificación con IA en 2026.

Todo el mundo se centró en el susto de ciberseguridad cuando Fortune publicó un titular audaz y directo diciendo: Anthropic había dejado accidentalmente expuestos casi 3.000 archivos internos, incluido un borrador de publicación de blog que promocionaba su modelo inédito. Pero como alguien que pasa cada día construyendo con Claude, lo que captó mi atención no fue la filtración en sí, sino las afirmaciones tranquilas y explosivas enterradas en ese borrador sobre el rendimiento en codificación.
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Abrir Playground →
En este artículo, ustedes y yo, Dora, no vamos a perseguir el hype ni el pánico de seguridad, sino ir directamente a lo que realmente importa para los desarrolladores y equipos que lanzan productos reales, analizando exactamente lo que sabemos (y lo que no sabemos) sobre las capacidades de codificación de Claude Mythos / Capybara.
Lo que dice el borrador filtrado sobre el rendimiento de codificación de Claude Mythos
La afirmación precisa del borrador filtrado: “En comparación con nuestro mejor modelo anterior, Claude Opus 4.6, Capybara obtiene puntuaciones dramáticamente más altas en pruebas de codificación de software, razonamiento académico y ciberseguridad, entre otros.”
Eso es todo lo que Anthropic puso por escrito sobre el rendimiento de codificación. Sin porcentaje de SWE-bench, sin puntuación de Terminal-Bench, sin tabla comparativa. La frase “dramáticamente más altas” es la señal real — vaga, pero no sin significado.

Para contexto, Opus 4.6 actualmente lidera los modelos disponibles públicamente en SWE-bench Verified (~80,8%), Terminal-Bench 2.0 y Humanity’s Last Exam. El portavoz oficial de Anthropic confirmó que el modelo representa “avances significativos en razonamiento, codificación y ciberseguridad”. El entrenamiento está completo, las pruebas de acceso anticipado están en curso, y la codificación es explícitamente una de las tres dimensiones de capacidad principales. Todo lo demás es inferencia.
Por qué la codificación es la capacidad más importante para este nivel de modelo
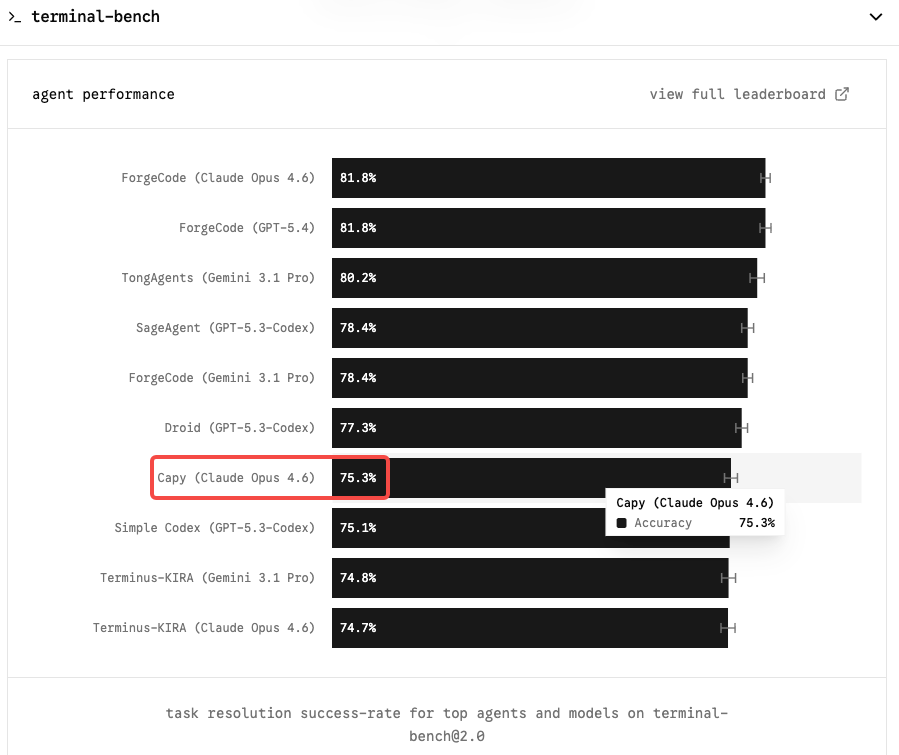
Contexto de Terminal-Bench 2.0 y puntuaciones actuales de Opus 4.6
Terminal-Bench 2.0 es el benchmark que más importa para los flujos de trabajo de codificación agéntica. A diferencia de SWE-bench, que evalúa la resolución aislada de problemas de GitHub, Terminal-Bench evalúa tareas reales en un entorno de terminal con sandbox — administración de sistemas, DevOps, flujos de trabajo CLI de múltiples pasos. Es más difícil, más representativo del uso en producción y menos susceptible a la inflación impulsada por andamiajes.
Claude Opus 4.6 ocupa el primer lugar con 65,4% en Terminal-Bench 2.0 y 72,7% en OSWorld. Un modelo de nivel Capybara que lleve ese número al rango del 75–85% sería un cambio genuino para cualquier equipo que ejecute agentes de codificación autónomos.
En SWE-bench Verified, el panorama está más comprimido: seis modelos ahora puntúan dentro de 0,8 puntos entre sí. Opus 4.6 está en 80,8%; Gemini 3.1 Pro ofrece 80,6% a $2/$12 por millón de tokens. El SWE-bench bruto ya no es un diferenciador significativo. Terminal-Bench y la coherencia en contextos largos son donde Opus 4.6 justifica su precio premium — y donde Mythos probablemente hará su caso más claro.
Lo que “dramáticamente más alto” significa estructuralmente
En el borrador, “dramáticamente más alto” aparece junto a “cambio significativo” — la misma frase que el portavoz de Anthropic usó públicamente. Ninguno de los dos términos es casual. El salto de Opus 4.1 a Opus 4.6 fue una mejora generacional dentro del mismo nivel. “Cambio significativo” implica algo diferente en naturaleza — más parecido a la brecha entre Sonnet y Opus que entre dos versiones consecutivas de Opus.
Un modelo que supere significativamente a Opus 4.6 en codificación sería una herramienta importante para el desarrollo de software, la depuración y los flujos de trabajo agénticos. La pregunta abierta es cuándo estará disponible y a qué costo. Ese es el encuadre honesto. La afirmación de rendimiento es creíble dado el historial reciente de Anthropic. La validación simplemente aún no está aquí.
Implicaciones para los flujos de trabajo de codificación agéntica
Tareas de código de contexto largo
La implicación práctica más inmediata de un modelo de nivel Capybara para los equipos de codificación no son las puntuaciones brutas de benchmark — es lo que hace un mejor razonamiento a escala.
La ventana de contexto de 1M de Claude Code ya está disponible para todos en Opus 4.6, proporcionando ~830K tokens utilizables tras la compactación — suficiente para monorepos completos y conjuntos de documentación completos. Un modelo que supera dramáticamente a Opus 4.6 en codificación, aplicado a esa misma ventana, significa mejor comprensión arquitectónica en bases de código grandes y menos errores de razonamiento en refactorizaciones de múltiples archivos. La ventana de contexto no cambia. La calidad del razonamiento dentro de ella sí lo haría.
Para equipos que hoy realizan análisis de bases de código grandes — el tipo de trabajo donde cargas más de 50K líneas de código fuente y le pides al modelo que entienda el panorama completo — este es el camino de mejora práctica que más importa.
Agentes de depuración de múltiples pasos
Anthropic lanzó Agent Teams como una función experimental con la versión Opus 4.6, marcando un paso significativo en los flujos de trabajo agénticos. Una sesión actúa como líder del equipo — coordina el trabajo, asigna tareas y sintetiza resultados. Los compañeros de equipo trabajan de forma independiente, cada uno en su propia ventana de contexto, y se comunican directamente entre sí.
Los agentes de depuración de múltiples pasos son donde el valor compuesto de un mejor modelo base se vuelve más claro. En una configuración multiagente, la calidad de planificación del líder del equipo determina qué tan bien funciona toda la operación. Un modelo más potente toma mejores decisiones de descomposición de tareas, escribe especificaciones de tareas más claras para los subagentes y detecta errores de integración antes.
El borrador filtrado señaló específicamente la codificación de software junto con la ciberseguridad como los dominios donde Capybara supera “dramáticamente” a Opus 4.6. Si esa brecha es real y sustancial en tareas al estilo Terminal-Bench, se traduciría directamente en agentes de depuración de múltiples pasos más confiables que requieren menos intervención humana para recuperarse de suposiciones incorrectas.
Exploración autónoma de bases de código
Este es el caso de uso que más me genera curiosidad en la práctica. Claude Code rastrea el problema a través de tu base de código, identifica la causa raíz e implementa una solución. La calidad de ese rastreo es una función de la profundidad de razonamiento, no solo del tamaño de la ventana de contexto.
En un flujo de trabajo típico de 2026, un desarrollador podría presentar un requisito de alto nivel y el agente líder lo descompondrá en tareas distintas, con compañeros de equipo utilizando el Model Context Protocol para acceder a herramientas externas, ejecutar pruebas y realizar auditorías de seguridad simultáneamente. Un modelo de nivel Capybara funcionando como orquestador en ese tipo de configuración haría que todo el flujo de trabajo sea más autónomo — lo que significa menos solicitudes de aclaración, mejor descomposición inicial de tareas y autocorrección más confiable cuando un subagente llega a un estado inesperado.
Qué deben hacer los desarrolladores ahora mientras Mythos no está disponible
Cómo hacer benchmark de Opus 4.6 para tu caso de uso actual
Lo más útil que puedes hacer ahora mismo es ejecutar tu propia evaluación en Opus 4.6 — no contra benchmarks, sino contra tu carga de trabajo real. Los benchmarks genéricos como SWE-bench prueban la resolución aislada de problemas con andamiajes estandarizados. Tu agente de codificación en producción tiene una estructura de base de código específica, un conjunto específico de tareas y un modo de fallo específico. Esos son los que importan.
Una evaluación de línea base práctica para un agente de codificación podría verse así:
# Simple task success rate tracking
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Run the same 20-30 representative tasks through Opus 4.6
# Track: did it succeed on first attempt? How many turns?
# What fraction of the 1M context window did it consume?
# Where did it fail — reasoning error, tool use, or context overflow?La razón por la que esto importa: cuando Mythos esté disponible, tendrás una línea base real para evaluar si la mejora de capacidad justifica la prima de costo para tu flujo de trabajo específico. “Dramáticamente más alto” en el conjunto de pruebas interno de Anthropic puede o no traducirse en una diferencia significativa en tu estructura particular de base de código y distribución de tareas.
El “mejor modelo” es el que se adapta a cómo te comunicas con él. Un modelo de nivel medio en un buen entorno supera a un modelo de frontera en uno malo. La calidad de tu entorno — ingeniería de prompts, configuración de herramientas, estructura de CLAUDE.md — es una variable que puedes mejorar ahora. Mythos no arreglará una arquitectura de agente mal diseñada.
Decisiones de arquitectura que escalarán con un modelo más capaz
La buena noticia es que las arquitecturas agénticas bien diseñadas son agnósticas al modelo en la capa de enrutamiento. Los patrones que vale la pena construir ahora:
Separa la orquestación de la ejecución. Un agente orquestador que descompone tareas, asigna archivos y revisa resultados — respaldado por subagentes especializados para la implementación — puede intercambiar su modelo base con un solo cambio de parámetro. Construye esta separación ahora y la actualización a Mythos se convierte en una actualización de configuración, no en una refactorización arquitectónica.
Usa CLAUDE.md como contexto de tiempo de ejecución, no como prompting específico de sesión. El archivo CLAUDE.md sirve como la “constitución” para los agentes de IA dentro de un repositorio — proporcionando el contexto necesario sobre la arquitectura del proyecto, los estándares de codificación y los comandos de compilación que permiten a los agentes operar sin microgestión humana. Un CLAUDE.md bien estructurado reduce los costos de exploración por tarea en Opus 4.6 hoy y amplificará las ganancias de un modelo más potente mañana.
Diseña para la ventana de contexto de 1M, no en su contra. Los equipos que ya han reestructurado su estrategia de carga de archivos, lógica de fragmentación y gestión de contexto para trabajar dentro de la ventana de 1M estarán posicionados para aprovechar al máximo la capacidad de razonamiento de Mythos en esa misma ventana. No construyas soluciones alternativas para límites de contexto que asuman que el techo no subirá.
Qué observar en el lanzamiento para equipos enfocados en codificación
Las señales que más importan para los desarrolladores son diferentes de las señales empresariales generales. Para equipos enfocados específicamente en codificación:
Puntuaciones de SWE-bench y Terminal-Bench en el lanzamiento. Anthropic históricamente ha publicado estas junto con los lanzamientos de modelos. Si Mythos cumple la promesa de “dramáticamente más alto”, esperarías que las puntuaciones de Terminal-Bench 2.0 se muevan significativamente por encima del 65,4% de Opus 4.6. Un salto al 75%+ validaría la afirmación para los flujos de trabajo agénticos.
Actualización de la cadena del modelo de Claude Code. Revisa los documentos de Claude Code y la descripción general de modelos de API para ver un nuevo alias de modelo. Claude Code históricamente ha actualizado su modelo predeterminado dentro de los días siguientes a un nuevo lanzamiento insignia. Si Mythos llega a la API pública, aquí es donde aparecerá primero para los equipos de codificación.
Anuncio de compatibilidad con Agent Teams. Agent Teams se lanzó como experimental con Opus 4.6. Si Mythos se integra nativamente con Agent Teams en el lanzamiento — o requiere una configuración separada — determinará qué tan rápido los equipos pueden incorporarlo a los flujos de trabajo multiagente.
El registro de cambios de Anthropic y la documentación de precios. Estas dos páginas son la señal confiable más temprana antes de cualquier anuncio de prensa. Una nueva cadena de modelo y una nueva fila de precios aparecerán aquí primero.
Preguntas frecuentes
¿Está Claude Mythos disponible para tareas de codificación ahora?
No. A principios de abril de 2026, no existe un endpoint de API público para Claude Mythos o el nivel Capybara. Claude Mythos / Capybara solo está disponible para un pequeño grupo de clientes de acceso anticipado seleccionados por Anthropic, sin API pública, sin precios anunciados y sin fecha de lanzamiento confirmada. Claude Opus 4.6 — 80,8% en SWE-bench Verified, 65,4% en Terminal-Bench 2.0 — sigue siendo la mejor opción disponible públicamente.
¿Funcionará Claude Mythos con Claude Code?
Casi con certeza sí, eventualmente. La arquitectura de Claude Code es agnóstica al modelo; cambiar a un nuevo modelo insignia es un solo cambio de parámetro. Pero esto no está confirmado para Mythos en el lanzamiento.
¿Debería esperar a Mythos para construir mi herramienta de codificación con IA?
No. Anthropic ha declarado que necesita volverse “mucho más eficiente antes de cualquier lanzamiento general”. Construir sobre Opus 4.6 ahora significa que tu arquitectura está validada en producción cuando llegue Mythos. La actualización será un cambio de cadena de modelo. Los equipos que esperen estarán tratando de ponerse al día.
Publicaciones anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado

API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción

Precios de GPT-5.4 Mini: Costos de entrada, caché y salida

API de MAI-Image-2.5: Lo que los desarrolladores deben saber
