Filtración de GPT-5.4: Lo que los desarrolladores deben saber
GPT-5.4 apareció brevemente en los repositorios de OpenAI Codex antes de ser eliminado. Esto es lo que las señales de la filtración pueden significar para los desarrolladores.

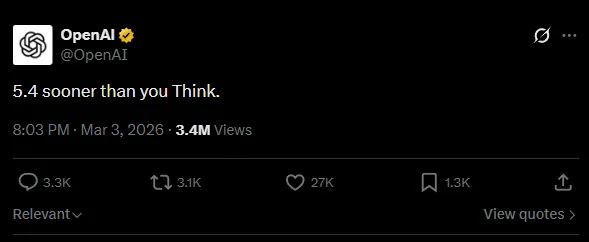
Hola, soy Dora. No estaba buscando un nuevo modelo. Simplemente estaba limpiando un pipeline de compilación cuando vi un hilo con capturas de pantalla de un commit que mencionaba “GPT 5.4”. Sin fanfarria, solo una pequeña línea en un pull request. Hice una pausa, no porque necesitara otro acrónimo en mi día, sino porque las pistas tranquilas y accidentales suelen decir más que los lanzamientos espectaculares.
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. GPT-5.4 API → · GPT-5.5 API → · Abrir Playground →
Durante la primera semana de marzo de 2026, seguí las migas de pan: diffs en caché, conversaciones de desarrolladores y un PR que pareció aparecer y desaparecer. No probé GPT 5.4 (no hay nada oficial que probar), pero observé detenidamente lo que el código parecía referenciar y cómo fue gestionado. El tono del rastro importaba casi tanto como el contenido.
Cómo GPT-5.4 apareció en la naturaleza
Las referencias del PR de Codex
Noté por primera vez menciones de GPT 5.4 vinculadas a un cambio de corta duración en un repositorio que parecía tocar contextos de “Codex”, ya sea nomenclatura heredada o una ruta interna que todavía usa “codex” como contenedor para flujos de codificación. El fragmento que circulaba mostraba algunas cosas que esperarías en torno al enrutamiento de modelos y los feature flags, nada que gritara “lanzamiento”, más bien tuberías. Si has trabajado con cambios de modelos, sabes que estas líneas suelen ser aburridas e importantes.
Dos cosas destacaron en esos fragmentos: una referencia a un interruptor “/fast” en una capa de comandos de chat o agente, y una etiqueta de capacidad que se leía como visión de resolución completa. Soy específica aquí porque importa. Las etiquetas no siempre coinciden con la realidad, pero rara vez son aleatorias.
Por qué el código fue eliminado rápidamente
El commit no duró. Por lo que vi, la rama fue reescrita y el diff del PR fue eliminado. Eso es común cuando un equipo incluye una referencia demasiado pronto o mezcla configuraciones internas y externas por error. En otras palabras: parecía mantenimiento rutinario bajo presión, no una eliminación intencionada.
He hecho lo mismo en equipos más pequeños: detectar un flag que no debería haber expuesto, hacer force-push y seguir adelante. La velocidad de la corrección sugería que alguien más arriba notó el ruido y decidió cerrar el ciclo. No fue un escándalo. Solo contención.
Lo que las eliminaciones con force-push suelen señalar
Un force-push no prueba nada glamoroso. Generalmente señala urgencia y el deseo de restaurar el repositorio a un estado conocido. Puedes leer la postura de Git sobre la reescritura del historial en la documentación: una herramienta útil y afilada, fácil de cortarse con ella si no tienes cuidado. Si ves un force-push en medio de una filtración, a menudo significa que el equipo trata la fuga como ruido en lugar de una revelación coordinada.
Para contexto (no como prueba), aquí hay una referencia neutral: las notas de Git sobre force pushing y reescritura del historial. Mundo diferente, mismo patrón.
Lo que el código filtrado realmente muestra
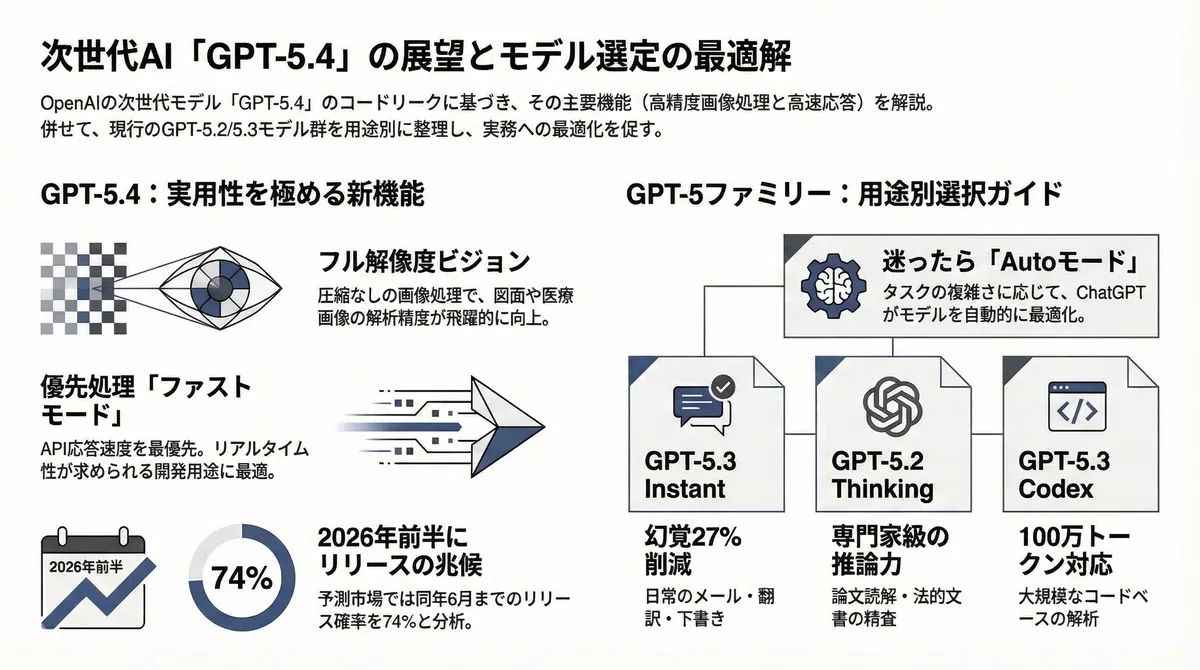
Comando de modo rápido (/fast)
La línea que mencionaba un comando “/fast” me pareció, a mí, como una anulación a nivel de usuario o agente. En términos prácticos, sugiere un modo que intercambia cierta profundidad por velocidad, un dial familiar en los enrutadores de modelos. Si esto está vinculado a GPT 5.4, esperaría tokens iniciales más rápidos, quizás almacenamiento en caché más agresivo, quizás umbrales de llamadas a herramientas más flexibles. Nada llamativo, pero útil cuando estás dentro de un bucle ejecutando docenas de pequeñas comprobaciones.
Esto no sonaba como una característica que gana demos. Sonaba como algo que activarías durante despliegues o pasos de CI cuando te importa más la latencia que la elocuencia: por ejemplo, normalización de cadenas de documentación, pequeñas refactorizaciones o diffs de esquemas que no necesitan una prosa perfecta.
Referencia a visión de resolución completa
“Visión de resolución completa” es una frase cargada. En la práctica, eso podría significar límites de entrada más altos, mejor manejo de capturas de pantalla de UI densas o una reducción de escala menos agresiva antes de que el modelo vea los píxeles. Si es preciso, esto se inclina hacia flujos de trabajo donde la fidelidad importa: leer código real en capturas de pantalla, revisar estados de UI o extraer estructura de diagramas sin difuminar los detalles.
Trabajo con muchas notas de producto empaquetadas en imágenes: maquetas con anotaciones pequeñas, líneas rojas, ese tipo de cosas. Si GPT 5.4 maneja esos de forma nativa a mayor resolución, eliminaría un impuesto silencioso pero constante: el paso de preparación donde recorto o recodifico imágenes para que un modelo vea lo que yo veo.
Señales de agente de codificación en el contexto de Codex
Las referencias a Codex se sentían como andamiaje para agentes de codificación. No magia de “escríbeme una aplicación”, más bien los pequeños músculos: selección de herramientas, llamadas a funciones, políticas de reintento y alternativas cuando una llamada devuelve algo inesperado. Las pistas que vi apuntaban a esa capa, no al titular.
Si esa lectura es correcta, GPT 5.4 podría estar ajustado para flujos de codificación agéntica que sobreviven al desorden de los repositorios reales: pruebas parciales, entornos inestables, gestores de dependencias mixtos. Menos “genio programador”, más “compañero de trabajo confiable que no se rinde después del segundo error”. Puedo trabajar con eso.
Para qué está diseñado probablemente GPT-5.4
Flujos de trabajo de codificación con IA
No creo que GPT 5.4 esté persiguiendo la novedad. El rastro sugiere manos más firmes en bucles comunes: leer código, hacer pequeñas ediciones, validar y volver a intentarlo sin drama. Si entregas funciones dentro de restricciones reales, ese ritmo importa más que la brillantez puntual.
Una suposición, basada en lo que vi y lo que sigue apareciendo en los equipos con los que trabajo: GPT 5.4 probablemente está pensado para estar más cerca del código, no de la presentación de diapositivas. Probablemente apunta a diffs razonablemente rápidos, actualizaciones de documentación consistentes, refactorizaciones más seguras y sugerencias pragmáticas que sobreviven a la etapa de ejecución.
Optimización de bucles de agentes
Los bucles de agentes son frágiles por razones aburridas: tiempos de espera, errores de herramientas, deriva de contexto e intentos que nunca convergen. La pista “/fast” se lee como una forma de mantener los bucles ágiles, mientras que la referencia a visión sugiere que el agente puede leer lo que los humanos realmente comparten (capturas de pantalla, registros, fotos de terminal) sin complicaciones adicionales.
Si es cierto, podrían aparecer dos mejoras en la calidad de vida:
- Menos reintentos manuales: una tipificación de errores más clara y una lógica de retroceso más tranquila reducen el caos.
- Llamadas a herramientas más precisas: saltos más baratos y rápidos cuando un paso no necesita razonamiento completo.
Esto no me ahorró tiempo al principio, rastrear una filtración nunca lo hace, pero su forma se sintió como un esfuerzo mental reducido para los equipos que automatizan las partes aburridas del mantenimiento del código.
Integraciones de herramientas para desarrolladores
La forma en que las referencias estaban encajadas en las pistas de enrutamiento me dice que GPT 5.4 podría estar empaquetado para encajar en los stacks de desarrollo existentes. Piensa en:
- Hooks de CI/CD que eligen velocidad o profundidad por paso.
- Extensiones de editor que pueden leer imágenes con mayor fidelidad sin preprocesamiento externo.
- Frameworks de agentes que dependen menos de código de pegamento especial.
Si es hacia donde va GPT 5.4, el valor no estará en una demo: estará en menos adaptadores frágiles. Ese es el tipo de actualización que notas tres semanas después cuando nada se rompe y te das cuenta de que no tuviste que vigilar al agente un viernes.

Lo que todavía no sabemos
No hay benchmarks confirmados
No he visto benchmarks creíbles vinculados a GPT 5.4. Sin hojas de evaluación, sin tareas estandarizadas, sin comparativas con los modelos actuales. Sin números, solo tenemos impresiones y etiquetas. Si y cuando esto llegue, buscaré primero pruebas pequeñas y prácticas: tiempo de corrección en una prueba fallida, precisión al leer capturas de pantalla densas o número de reintentos por problema resuelto.
Sin detalles de precios ni de API
No hay nada público sobre precios o cuotas. Para planificar, eso importa más que el hype. Un gran modelo que es difícil de presupuestar no llega a producción. Si estás mapeando escenarios hoy, mantén marcadores de posición en tus hojas de cálculo y verifica la cordura con la documentación actual de modelos de OpenAI en lugar de etiquetas filtradas.
Cronograma de lanzamiento poco claro
No tengo una fecha, un trimestre ni siquiera una temporada. La eliminación rápida sugiere movimiento interno, no sincronización con el mercado. Si GPT 5.4 aparece, puede hacerlo silenciosamente en tablas de enrutamiento o como un flag en frameworks de agentes antes de cualquier gran anuncio. O puede cambiar de nombre y nunca ser llamado “GPT 5.4” en público.
Estado actual y descargo de responsabilidad (modelo no lanzado oficialmente)
A principios de marzo de 2026, GPT 5.4 no ha sido anunciado ni documentado. Estoy compartiendo observaciones de referencias de código de corta duración y la forma en que fueron manejadas, nada más. Esto no es un consejo para rediseñar nada. Si tienes curiosidad, mantén un ojo en la documentación estable, no en capturas de pantalla. Y si detectas otra referencia perdida, respira. La mayoría de las filtraciones son más silenciosas, y más útiles, de lo que sugieren los titulares.
Lo dejo aquí: lo que me llamó la atención no fue el número de versión. Fueron los pequeños signos de cuidado en torno a los bucles y la latencia. Si es hacia donde van las cosas, estoy bien con menos espectáculo.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber