Gemini 3.1 Flash-Lite: Características, Casos de Uso y Cómo Se Compara con Flash
Gemini 3.1 Flash-Lite es el modelo de inferencia de menor costo de Google. Características, casos de uso reales y una comparación directa con Gemini Flash.

*Noté algo extraño cuando Google lanzó Gemini 3.1 Flash-Lite el 3 de marzo. Por lo general, primero lanzan el modelo Flash más capaz, o se saltan el nivel Lite por completo. Esta vez, fueron directamente a la opción económica. Ese cambio me hizo prestar atención.
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Abrir Playground →
Soy Dora. Lo he estado probando durante el último día, y lo que me sorprendió no fue solo la velocidad. Fue cómo la estructura de precios de repente hizo que ciertos flujos de trabajo se sintieran… asequibles de una manera que antes no lo eran.

Qué es Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite ocupa el lugar más bajo en la nueva línea de modelos de Google, pero “el más bajo” ya no significa lo que solía. Según la documentación oficial de Google, es su modelo Gemini más rentable, optimizado para casos de uso con baja latencia y tráfico de alto volumen. Su objetivo es igualar el rendimiento de Gemini 2.5 Flash en las principales áreas de capacidad, siendo significativamente más rápido y económico.
Su lugar en la línea Gemini 3.1
La familia Gemini 3 ahora tiene tres niveles bien definidos. En la cima está Gemini 3.1 Pro, el modelo pesado para tareas de razonamiento complejo. En el medio se encuentra Gemini 3 Flash, que combina la inteligencia de Pro con la velocidad de Flash. Y ahora, Flash-Lite ocupa el espacio de alto volumen y sensibilidad al costo.
Lo interesante es que Flash-Lite no es una versión recortada de Flash. En realidad, está basado en la arquitectura de Gemini 3 Pro, luego optimizado específicamente para rendimiento y latencia. Esa elección arquitectónica se refleja en los benchmarks: no es solo más rápido, es más inteligente de lo que esperarías por el precio.
Cómo funciona la lógica de niveles Pro / Flash / Flash-Lite
El enfoque por niveles no trata sobre funcionalidades, sino sobre la asignación de cómputo. Pro dedica más tokens a resolver problemas complejos. Flash equilibra el razonamiento con la velocidad. Flash-Lite minimiza el razonamiento interno por defecto, pero puedes ajustarlo.
Esta última parte es nueva. Google añadió lo que llaman “niveles de pensamiento”: mínimo, bajo, medio o alto. Para una tarea simple de traducción, lo configuras en mínimo y obtienes resultados instantáneos. Para algo que necesita más precisión, lo subes y aceptas una latencia y un costo ligeramente mayores.
Lo probé con un lote de tickets de soporte al cliente. Con pensamiento mínimo, las respuestas llegaron en menos de dos segundos. En medio, tardó cinco segundos, pero captó matices que el procesamiento rápido había omitido. El control se siente práctico.
Características clave de Gemini 3.1 Flash-Lite
Costo de inferencia ultrabajo
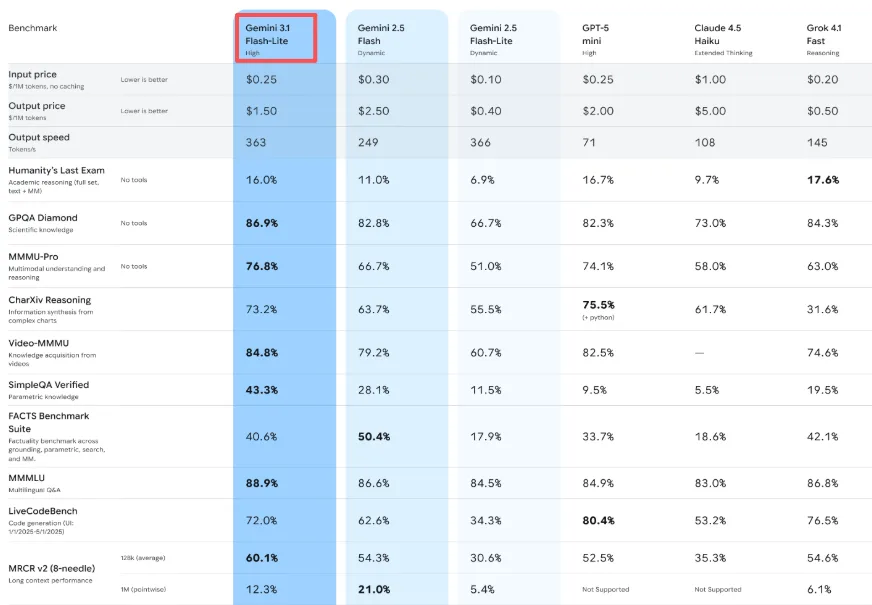
El precio es de $0,25 por millón de tokens de entrada y $1,50 por millón de tokens de salida. Para ponerlo en perspectiva: Gemini 3.1 Pro comienza en $2,00 por millón de tokens de entrada y $18 por millón de tokens de salida para cargas de trabajo exigentes. Flash-Lite cuesta aproximadamente una octava parte que Pro para tareas básicas.
Pero aquí está lo que me sorprendió: también es más barato que Gemini 2.5 Flash (que era $0,30/$2,50), a pesar de ser más capaz. Eso es inusual. Normalmente se paga más por las mejoras.
Alto rendimiento y baja latencia
Google afirma que Flash-Lite genera salida a 363 tokens por segundo, y en mis pruebas, eso parece preciso. Más importante aún, el tiempo hasta el primer token, el momento en que dejas de esperar y empiezas a ver la salida, es 2,5 veces más rápido que Gemini 2.5 Flash, según sus benchmarks internos.
Noté esto más cuando construí un pipeline simple de moderación de contenido. La diferencia entre una espera de tres segundos y una de un segundo no parece mucho. Pero cuando procesas cientos de elementos, ese retraso se acumula. Con Flash-Lite, el pipeline se sintió ágil en lugar de lento.
Soporte de entrada multimodal
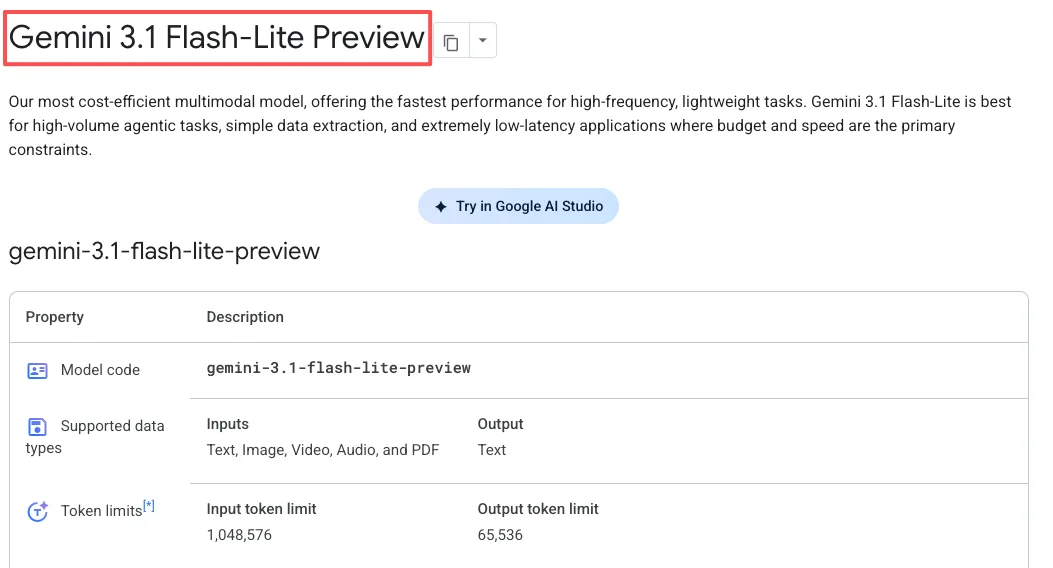
Flash-Lite maneja texto, imágenes, audio y video. La ventana de contexto llega hasta 1 millón de tokens, y puede generar hasta 64.000 tokens de salida de texto.
Lo probé con una mezcla de imágenes de productos y descripciones para un prototipo de comercio electrónico. Los etiquetó de forma consistente y rápida. Usuarios tempranos como Whering reportaron un 100% de consistencia en el etiquetado de artículos para categorías de moda complejas. Ese tipo de fiabilidad importa cuando construyes sistemas que no pueden permitirse la deriva.
Ventana de contexto larga
La ventana de contexto de 1 millón de tokens significa que puedes proporcionar documentos completos, hilos de conversación largos o grandes conjuntos de datos sin necesidad de dividirlos en fragmentos más pequeños primero. No uso la ventana completa con frecuencia, pero cuando lo hago, como al analizar PDFs de varias páginas, marca la diferencia entre un flujo de trabajo fluido y uno frustrante.
Gemini 3.1 Flash-Lite vs Flash: Comparación directa
Cuándo usar Flash-Lite
Usa Flash-Lite cuando ejecutes miles o millones de tareas similares. Pipelines de traducción, colas de moderación de contenido, análisis de sentimientos a escala, extracción básica de datos: cualquier cosa donde la tarea esté bien definida y el costo por token importe más que el razonamiento profundo.
También descubrí que funciona bien como enrutador. Puedes usar Flash-Lite para clasificar las solicitudes entrantes como “simples” o “complejas”, y luego redirigir las complejas a Flash o Pro. Esto ahorra dinero sin sacrificar calidad donde más importa.
Cuándo usar Flash en su lugar
Si la tarea requiere razonamiento en múltiples pasos, resolución creativa de problemas o manejo de instrucciones ambiguas, Flash es la mejor opción. Cuesta el doble, pero también es más inteligente, especialmente para tareas de programación, donde iguala o supera a Pro en algunos benchmarks.
Probé ambos en una tarea que implicaba generar componentes de UI a partir de prompts en lenguaje natural. Flash-Lite podía manejar solicitudes directas (“crea un formulario de inicio de sesión”), pero tenía dificultades con las vagas (“diseña algo moderno y limpio”). Flash manejó ambas.
Casos de uso de Gemini 3.1 Flash-Lite
Enrutamiento de agentes de IA y clasificación de tareas
Uno de los casos de uso más claros que he visto es usar Flash-Lite como controlador de tráfico. Cuando un usuario envía una solicitud, Flash-Lite la lee, determina la complejidad y la redirige al modelo apropiado: Flash para tareas medias, Pro para las difíciles.
Este patrón ya se usa en herramientas de producción. El CLI de Gemini de código abierto usa Flash-Lite exactamente para esto, y funciona porque el modelo es lo suficientemente rápido y económico como para añadir ese paso de enrutamiento sin aumentar notablemente la latencia o el costo.
Chat de alto volumen y automatización de soporte
El soporte al cliente es donde los ahorros realmente se hacen evidentes. Si manejas decenas de miles de tickets de soporte diariamente, la diferencia entre $0,25 y $2,00 por millón de tokens de entrada escala rápidamente.
Flash-Lite puede manejar preguntas directas, extraer intenciones y redirigir tickets que necesitan atención humana. No va a resolver problemas técnicos complejos, pero no necesita hacerlo. Solo necesita ser fiable y rápido.
Moderación de contenido y etiquetado
Construí un pipeline de prueba rápido para moderar contenido generado por usuarios: señalar spam, lenguaje inapropiado y publicaciones fuera de tema. Flash-Lite procesó alrededor de 500 elementos en menos de un minuto, con una precisión consistente.
La clave aquí es la consistencia. Algunos modelos derivan con el tiempo o dan respuestas diferentes a entradas similares. Flash-Lite se mantuvo predecible en ejecuciones repetidas, lo que importa cuando construyes sistemas que necesitan comportarse de la misma manera en todo momento.
Pipelines de preprocesamiento de documentos
Flash-Lite sobresale en la extracción de datos estructurados. Dado un lote de facturas o recibos, puede extraer campos clave, como fechas, montos y nombres de proveedores, y producirlos como JSON.
Lo probé con una mezcla de facturas en PDF y manejó la mayoría de ellas limpiamente. Las que le costaron trabajo fueron escaneos de baja calidad con texto deficiente, pero esa es una limitación de la entrada, no del modelo.
Lo que Flash-Lite significa para el diseño de infraestructura de IA

El patrón de arquitectura de modelos por niveles
El lanzamiento de Flash-Lite completa lo que empieza a sentirse como un patrón estándar de la industria: una pila de modelos de tres niveles. Tienes un modelo pesado para problemas difíciles, una opción equilibrada para uso cotidiano y uno ligero para trabajo repetitivo de alto volumen.
Esto no es nuevo: OpenAI tiene GPT-5 / GPT-5 mini, Anthropic tiene Claude Opus / Sonnet / Haiku. Pero la implementación de Google es interesante porque las brechas de precio son más amplias. Flash-Lite es genuinamente económico comparado con Pro, lo que hace que ciertos flujos de trabajo sean viables económicamente cuando antes no lo eran.
Enrutador económico + razonador potente: por qué importa
El patrón que sigo viendo es: usa un modelo económico para decidir qué tipo de tarea estás manejando, luego redirige a un modelo más caro solo cuando sea necesario. Esto no se trata solo de ahorrar dinero. También mejora la latencia para tareas simples, porque no estás esperando a que un modelo pesado se active.
Lo probé con un lote mixto de 100 tareas, la mitad simples y la mitad complejas. Usando Flash-Lite como enrutador, las tareas simples terminaron en segundos, y las complejas se redirigieron a Flash. El costo total fue aproximadamente un 40% menor que ejecutar todo a través de Flash, sin pérdida de calidad en las tareas complejas.
Esta arquitectura solo funciona si el enrutador es lo suficientemente rápido y económico como para no convertirse en el cuello de botella. Flash-Lite lo es.
Disponibilidad actual y estado de la API
Gemini 3.1 Flash-Lite está disponible ahora en vista previa a través de la API de Gemini en Google AI Studio y Vertex AI. No está en la aplicación Gemini para consumidores: está orientada a desarrolladores.
Los modelos en vista previa pueden cambiar antes de volverse estables y tienen límites de velocidad más estrictos. En la práctica, no he alcanzado esos límites en las pruebas normales, pero si estás planificando una implementación en producción a escala seria, es algo a tener en cuenta.
El modelo también se actualiza activamente. Las notas de versión de Google muestran mejoras continuas en el seguimiento de instrucciones, la calidad de la entrada de audio y las capacidades de razonamiento. Aún es pronto: probablemente mejore en los próximos meses.
Un pensamiento persistente
A lo que sigo volviendo no es la velocidad ni el costo. Es el hecho de que Flash-Lite hace que ciertos flujos de trabajo se sientan menos como experimentos y más como utilidades. Cuando el costo baja lo suficiente, dejas de preguntarte “¿debería usar IA para esto?” y empiezas a preguntar “¿cómo construyo esto para que escale?”
Ese cambio, de novedad a infraestructura, es donde las herramientas empiezan a quedarse.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber