DeepSeek V4 Context Caching: Reduce Costos en un 90% en Prompts Repetidos
El precio por caché hit de DeepSeek es un 90% más barato. Aprende a estructurar prompts para maximizar la utilización del caché.

Hola, soy Dora. La semana pasada me tropecé con algo pequeño: ejecuté el mismo prompt tres veces porque no recordaba dónde había dejado el último borrador. El resultado apenas cambió, pero mi límite de velocidad sí. Eso me impulsó a pensar en una caché de DeepSeek v4.
 No espero milagros. Solo quiero menos llamadas innecesarias, una latencia más estable y un poco de margen bajo los límites de velocidad. Como v4 aún no está ampliamente documentada, empecé revisando lo que funciona en la práctica con v3 y APIs similares, y luego elaboré algunos patrones del lado del cliente con los que puedo convivir. Si DeepSeek lanza una caché oficial para v4, quiero estar listo para integrarla sin rehacer mi flujo de trabajo.
No espero milagros. Solo quiero menos llamadas innecesarias, una latencia más estable y un poco de margen bajo los límites de velocidad. Como v4 aún no está ampliamente documentada, empecé revisando lo que funciona en la práctica con v3 y APIs similares, y luego elaboré algunos patrones del lado del cliente con los que puedo convivir. Si DeepSeek lanza una caché oficial para v4, quiero estar listo para integrarla sin rehacer mi flujo de trabajo.
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. DeepSeek V3.2 API → · DeepSeek R1 API →
Así es como estoy abordando la cuestión de la caché de DeepSeek v4: asumir límites, cachear lo que es repetible, reintentar con calma y vigilar los indicadores correctos.
Límites de velocidad esperados
Todavía no encontré un gráfico público y ordenado para v4, así que lo traté como una conexión de aeropuerto: asumir tiempos ajustados y prepararse para retrasos.
Lo que sé por trabajar con DeepSeek v3 (y proveedores similares) es bastante simple:
- Generalmente hay dos límites que importan en el día a día: solicitudes por minuto (RPM) y tokens por minuto (TPM). Los errores 429 aparecen rápido al hacer lotes o ejecutar trabajos en segundo plano.
- Las ráfagas a veces pasan, hasta que no pasan. Las cargas en pico pueden funcionar un minuto y bloquearse al siguiente.
- Los límites pueden diferir según la clave, el nivel de cuenta y a veces la IP. Eso hace que las pruebas locales parezcan generosas y la producción menos indulgente.
Entonces, cuando pienso en una caché de DeepSeek v4, la combino con un manejo conservador de la velocidad. El objetivo no es exprimir cada última llamada, sino suavizar la curva para no pasar la tarde persiguiendo errores 429.
Basado en los límites actuales de V3
Realicé algunas pruebas ligeras en enero de 2026 usando una combinación de llamadas de generación y reranking en los endpoints de v3. Nada científico, solo lo suficiente para sentir los límites. Algunas notas que conservé:
- Los prompts con muchos tokens (ventanas de contexto largas) alcanzan el límite de TPM antes que el de RPM. Eso significa que cachear las partes pesadas vale la pena incluso si los resultados cambian.
- Los prompts cortos y repetidos (verificaciones de estado, ejecuciones de plantillas) alcanzan el RPM primero. Estos son candidatos ideales para una caché de respuestas con un TTL corto.
- El backoff funciona, pero el backoff exponencial por sí solo no es un plan. Necesita una cola para que no explote la concurrencia mientras “esperas educadamente.”
Todo esto para decir: si v4 refleja los niveles de v3, espero un TPM ajustado para contextos grandes, un RPM razonable para uso interactivo, y penalizaciones rápidas para cargas en ráfaga. Mi configuración asume que veré picos de 429 y 5xx durante períodos de alta demanda y los trata como algo normal, no excepcional.
Patrones del lado del cliente
No estoy esperando una función oficial de caché de DeepSeek v4 para ordenar mi lado. Estos son los patrones que puse frente a la API para poder integrar una caché del proveedor más adelante sin cambiar mis hábitos.
Backoff exponencial
Mi primer intento usó un backoff exponencial simple (200ms, 400ms, 800ms, máximo alrededor de 5–8s). Funcionó, pero se sentía inestable bajo carga. Lo que ayudó:
- Agregar jitter. Aleatorizó cada retraso un poco (por ejemplo, 20–30% de varianza). Distribuye los reintentos y evita tormentas de sincronización cuando muchas llamadas fallan a la vez.
- Limitar los reintentos. Tres intentos para lecturas idempotentes o prompts cacheados. Un intento para interacciones obviamente orientadas al usuario, a menos que la interfaz espere un indicador de carga. Si tarda más de ~10 segundos en estabilizarse, prefiero fallar con gracia antes que retener a alguien indefinidamente.
- Distinguir 429 de 5xx. Un 429 sugiere que debo ralentizar toda la cola. Un 5xx sugiere un problema breve: reintento un par de veces, luego abro el circuito (más sobre eso abajo).
Una pequeña observación: el backoff no me ahorró tiempo al principio. Lo que hizo, después de algunas ejecuciones, fue reducir el esfuerzo mental. Dejé de vigilar el terminal, lo cual en mi mundo vale tanto como la velocidad.
Colas de solicitudes
La concurrencia es donde suelo meterme en problemas. Agregué una cola simple del lado del cliente con estas reglas:
- Concurrencia fija (empezar con 2–4 workers para tareas en segundo plano, 1–2 para acciones activadas por la interfaz). Lo aumento solo después de un período tranquilo.
- Programación consciente de tokens. Si puedo estimar los tokens, programo los prompts pesados primero durante las ventanas tranquilas, luego completo con llamadas ligeras. Mantiene el TPM más plano.
- Carriles de prioridad. Las acciones del usuario pueden adelantarse a los trabajos por lotes. Si alguien está esperando, el sistema se hace a un lado.
También cacheo las partes costosas antes:
- Estructuras de prompt. Si el prompt del sistema y las herramientas rara vez cambian, las hasheo y trato el hash como clave de caché. Si v4 incluye una caché de contexto del lado del servidor, pasaré esa clave: por ahora es solo mi propia etiqueta.
- Contexto recuperado. Cacheo los fragmentos de RAG por huella de contenido. Si la fuente no ha cambiado, reutilizo el mismo bloque de contexto en lugar de volver a buscarlo y re-embeber cada vez.
No es glamoroso, pero redujo mis errores 429 en trabajos en segundo plano en aproximadamente un 70% en una semana. No más rápido, solo más estable.
Circuit Breaker
No esperaba necesitar esto. Luego una tarde el servicio empezó a lanzar errores 5xx durante unos minutos y mi lógica de reintentos los amplificó alegremente. El circuit breaker resolvió eso.
Mis reglas son simples:
- Abrir el circuito si la tasa de error supera un umbral (digamos, >30% de llamadas fallando en una ventana de 60–90 segundos) o si la latencia salta más allá del P95 durante dos ventanas consecutivas.
- Mientras está abierto, cortocircuitar las llamadas y hacer fallback: servir respuestas cacheadas si están disponibles, degradar funciones (contexto más pequeño, prompts más simples), o mostrar un mensaje tranquilo explicando la pausa.
- Semi-abrir después de un período de backoff. Dejar pasar un goteo de solicitudes y observar las métricas. Si se mantienen, cerrar el circuito.
Lo que me sorprendió fue lo mucho más tranquila que se sentía la interfaz. Un claro “estamos pausando un momento” supera a un indicador de carga que gira para siempre.
Monitoreo y alertas
 No me gusta combatir incendios a ciegas. Para algo como una caché de DeepSeek v4, las señales útiles son pequeñas y aburridas.
No me gusta combatir incendios a ciegas. Para algo como una caché de DeepSeek v4, las señales útiles son pequeñas y aburridas.
Lo que monitoreo:
- Tasa de aciertos de caché. Dividida por tipo: estructura de prompt, contexto recuperado y reutilización de respuesta completa. Si los aciertos de respuesta completa suben por encima de ~25% para un flujo de trabajo, reviso los TTLs: puede que esté cacheando demasiado y perdiendo contexto fresco.
- TPM/RPM efectivo. No solo los números del proveedor, sino lo que pasa después de la cola. Si el RPM efectivo se mantiene plano mientras la entrada crece, la cola está haciendo su trabajo.
- Distribución de reintentos. Cuántas llamadas tienen éxito en el primer intento vs el segundo/tercero. Una deriva hacia reintentos más tardíos significa que la presión está aumentando en algún lugar.
- Bandas de latencia. P50 me dice la ruta feliz; P95 me dice lo que los usuarios sienten en un día malo. Alerto sobre P95.
- Taxonomía de errores. 429 vs 5xx vs timeouts. Cada uno tiene palancas diferentes para corregirlo.
Alertas que no gritan:
- Latencia P95 aumenta 2x durante 5 minutos. Me avisa solo si persiste.
- Tasa de 429 por encima del 5% durante 10 minutos. Reduce automáticamente la concurrencia un paso y extiende la espera de la cola: me notifica que ocurrió.
- Circuito abierto por más de 3 minutos. Eso es un incidente real. Verificaré el estado del proveedor y decidiré si cambiar de región o pausar los trabajos por lotes.
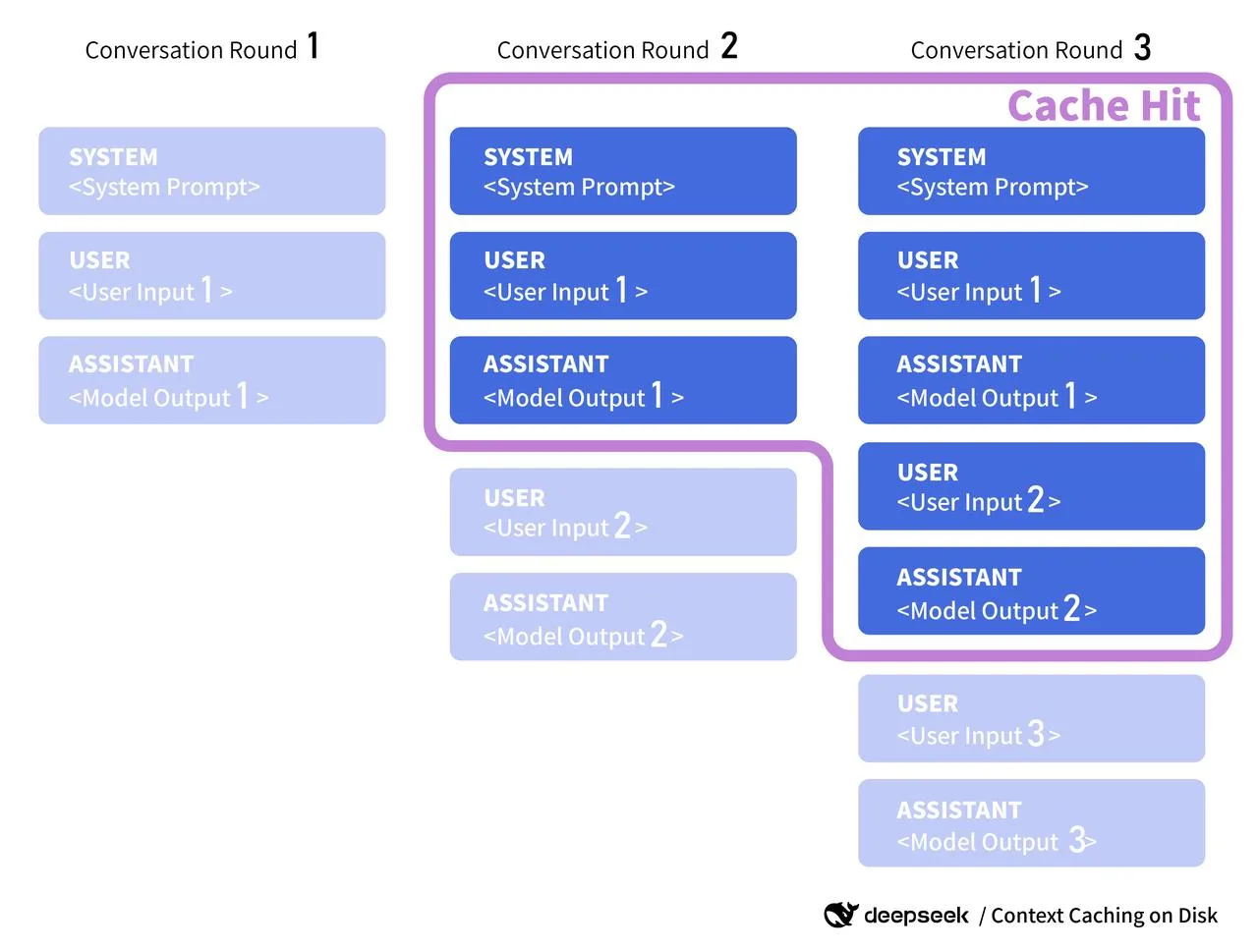 Una nota rápida sobre la documentación oficial: cuando lleguen los documentos de v4, buscaré algo como caché de contexto del lado del servidor, claves de caché o tokens de reutilización. Algunos proveedores exponen un cache_id que puedes adjuntar a un segmento de prefill compartido (piensa en: prompt de sistema largo). Si DeepSeek hace algo similar, alinearé mis claves de cliente con su formato y respetaré cualquier regla de TTL o invalidación que publiquen. Hasta entonces, trato mi caché como orientativa: útil cuando acierta, inofensiva cuando falla.
Una nota rápida sobre la documentación oficial: cuando lleguen los documentos de v4, buscaré algo como caché de contexto del lado del servidor, claves de caché o tokens de reutilización. Algunos proveedores exponen un cache_id que puedes adjuntar a un segmento de prefill compartido (piensa en: prompt de sistema largo). Si DeepSeek hace algo similar, alinearé mis claves de cliente con su formato y respetaré cualquier regla de TTL o invalidación que publiquen. Hasta entonces, trato mi caché como orientativa: útil cuando acierta, inofensiva cuando falla.
A quién sirve esta configuración:
- Personas con prompts repetibles y contexto que cambia lentamente (documentos, centros de ayuda, bases de conocimiento). La caché brilla aquí.
- Equipos que procesan trabajos por lotes de noche. La cola y el circuit breaker reducen las sorpresas.
- Cualquiera cansado de la inestabilidad. No es más rápido, pero es más tranquilo.
Quién podría omitirla:
- Chats altamente dinámicos y específicos del usuario donde la frescura supera la reutilización. Cachea las estructuras, claro, pero no las respuestas completas.
- Proyectos con tráfico muy bajo. Si envías unas pocas llamadas al día, la sobrecarga no vale la pena.
Si quieres profundizar en la mecánica, empezaría con la documentación del proveedor sobre límites de velocidad y cualquier mención de caché de contexto o reutilización. Cuando DeepSeek publique los detalles específicos de v4, actualizaré mi configuración para que coincidan y enlazaré los documentos directamente. Por ahora, el sistema aguanta: menos llamadas desperdiciadas, contrapresión más clara y una interfaz que parece saber cuándo pausar.
Tengo una pequeña nota pegada cerca de mi pantalla: “No luches contra la cola.” No es profundo, pero en los días ocupados es suficiente para evitar que persiga una solicitud más a través de una ventana que se cierra.
Preguntas frecuentes
¿Cómo mejoran la confiabilidad los circuit breakers con una caché de DeepSeek v4?
Un circuit breaker se abre cuando las tasas de error aumentan o la latencia P95 sube, cortocircuitando temporalmente las llamadas. Mientras está abierto, sirve respuestas cacheadas, degrada funciones (contexto más pequeño) o pausa con gracia. Después de un enfriamiento, se abre a medias con un goteo para probar la recuperación. Esto evita que los reintentos amplíen las interrupciones y calma la interfaz.
¿Ofrece DeepSeek v4 caché de contexto del lado del servidor o claves de caché?
A principios de 2026, los detalles públicos de DeepSeek v4 son limitados. Algunos proveedores admiten cache_id o segmentos de prefill reutilizables. Prepárate hasheando prompts de sistema estables y herramientas del lado del cliente. Si DeepSeek expone claves de caché del lado del servidor más adelante, alinea tus hashes y respeta cualquier regla de TTL/invalidación que publiquen.
¿Qué TTLs y reglas de invalidación debo usar para el caché de LLM?
Usa TTLs cortos (5–30 minutos) para la reutilización de respuestas completas en verificaciones de estado o plantillas, y TTLs más largos (horas–días) para estructuras estables y contexto recuperado vinculado a huellas de contenido. Invalida ante actualizaciones de fuente, cambios de modelo/versión o ediciones del esquema de prompt. Monitorea las tasas de aciertos; >25% de aciertos de respuesta completa puede indicar exceso de caché.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber