Seedance 1.5 Pro:邁向原生音視訊生成的重大進展

隨著生成式視頻進入真實製作,僅有視覺已經不再足夠。現代工作流程越來越需要視頻和音頻一起生成——原生且同步。
Seedance 1.5 Pro 是字節跳動用於原生音視頻共生成的下一代模型,現已在 WaveSpeedAI 上推出。該模型從零開始構建,專為可靠、可控且生產就緒的同步而設計,標誌著邁向真正統一多模態生成的重要一步。
在即將推出的技術文章中,我們將深入探討 Seedance 1.5 Pro——探索其模型能力、實用用例、基準洞察和背後的多模態架構。
核心模型能力(特性與實際應用)
1. 高保真同步的原生音視頻生成
Seedance 1.5 Pro 最根本的突破是其音視頻原生生成範式。在單次推理過程中,該模型同時生成視頻幀和相應的音軌,保持語音節奏、唇部運動、角色動作和攝像機動態在同一時間參考內對齐。
在多個評估輪次中,Seedance 1.5 Pro 始終優於主流的「視頻 + TTS」拼接管道——尤其是在長對話、快速唇動和動作配音場景中,傳統方法往往會出現漂移。
提示詞:一個英俊的男子站在霧氣籠罩的山脊頂部。他穿著光滑、實用的戶外裝備——深灰色防風夾克、專業登山褲和雙肩背包。山風輕輕吹動他的頭髮;他的表情平靜而堅定。身後,浪湧般的雲霧和薄霧在崎嶇的岩石中旋轉,偶爾分開,露出遠方被冰雪覆蓋的山峰。攝像機從身後緩慢推進,當他凝視下方翻滾雲層的深淵時。在寒冷的空氣中,他的呼吸凝聚成白色霧氣,增添了自然的大氣細節。他略微轉向鏡頭,銳利的眼睛充滿不屈的決心,用穩定有力的聲音說:「我喜歡挑戰。」
2. 多語者、多語言和方言感知生成
Seedance 1.5 Pro 支持跨主要全球語言和地區方言的音視頻生成。它保持語言特定的時序、音素和表達方式,提供精確的唇形同步和自然的情感對齐——即使跨越多個語者和快速語言切換。
提示詞:一部高度電影化的日本動漫風格短片,描繪夏日煙火節的宏大場景。強調高細節紋理(和服面料、頭髮、皮膚)、細微微表情、自然流暢的動作和精緻情感豐富的敘事。煙火類似於柔和電影照明,增強了情感氛圍。(省略提示詞…)她用日語溫柔地說:「我非常喜歡你」。男子微微鞠躬,決心說:「其實,我也喜歡你」。(省略提示詞…)
3. 富有表現力的動作與情感表演
Seedance 1.5 Pro 超越了保守、低風險的動作策略。角色動畫表現出更大的幅度、更豐富的節奏變化和更清晰的情感意圖——同時保持整體穩定性。
面部表情從僅僅可辨識進步到真正具有表演性:微表情、情感過渡和肢體語言自然地與講話對白對齐。結果是感覺明顯更生動的動作。
提示詞:一位身穿破舊太空服的年輕宇航員坐在昏暗的飛船駕駛艙中。頭盔面罩被霧氣和劃痕覆蓋,控制板閃爍著橙黃色光線,營造出緊張孤獨的氛圍。視頻以這個靜態開場幀開始。攝像機隨後快速放大到宇航員的臉部,然後切換到外部,揭示飛船穿過類似暴風雪的宇宙碎片風暴。科幻驚悚風格。背景音樂:低電子合成器配合迅速膨脹的弦樂營造懸念。音效:急促的引擎嗡嗡聲和嚎叫的太空風暴噪音。對白:「在太空的虛無中,一個錯誤…」,然後短暫沉寂,以「求救…系統故障」結束。
4. 電影、逼真導向的視覺美學
視覺上,Seedance 1.5 Pro 傾向於自然的實拍外觀,而不是重度風格化或過度渲染的效果。
照明、構圖、色彩和諧和景深始終保持穩定,產生接近商業級電影製作而非合成影像的輸出。
提示詞:第一人稱視角,來自巨型鋼製過山車前座。過山車攀升到頂峰,然後直線俯衝進一個黑暗隧道。周圍景物(日落時的遊樂園)略微模糊,風表現為呼嘯的空氣粒子。
5. 自動視頻時長適應
通過將視頻長度參數設置為 -1,Seedance 1.5 Pro 自動在 4–12 秒 範圍內選擇最合適的時長(僅整秒)。
該模型評估敘事節奏、動作完整性和音視頻結束點,選擇自然的終點。這減少了由選擇不當的固定時長導致的浪費生成和手動調整。
提示詞:8 位像素藝術風格,一位英雄在日落下跑動和跳躍,配有掃描線效果和復古電子遊戲音樂。
6. 通過提示詞控制的內置效果
Seedance 1.5 Pro 在基礎模型內包含一系列內置效果。這些可以通過提示詞指令觸發,而不是完全依賴於後期製作合成。
這對於動畫密集或風格化內容特別有價值——例如動作漫畫——其中效果密度和時序至關重要。
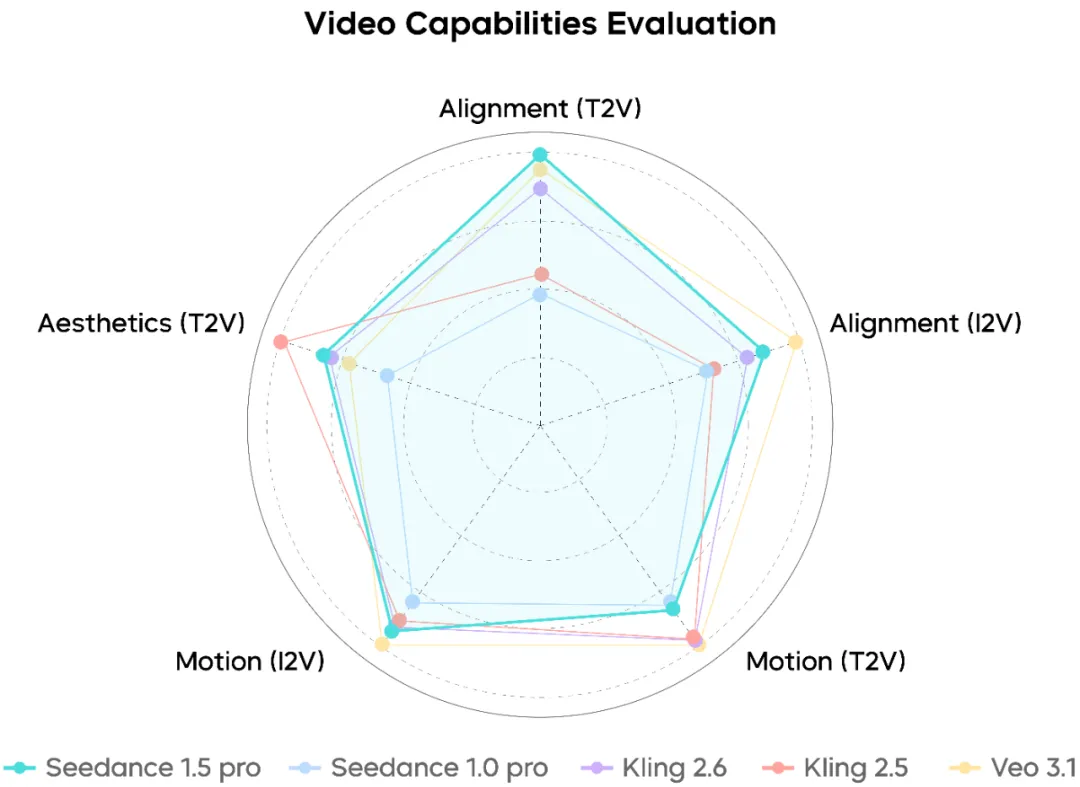
視頻生成性能
Seedance 1.5 Pro 展示了對涉及攝像機編舞、動作排序和敘事節奏的複雜提示詞的強大理解。面部特寫看起來自然,而長鏡頭和複合攝像機動作保持相對平穩和連貫。
也就是說,在極度高強度運動場景下,仍有進一步提高穩定性的空間。
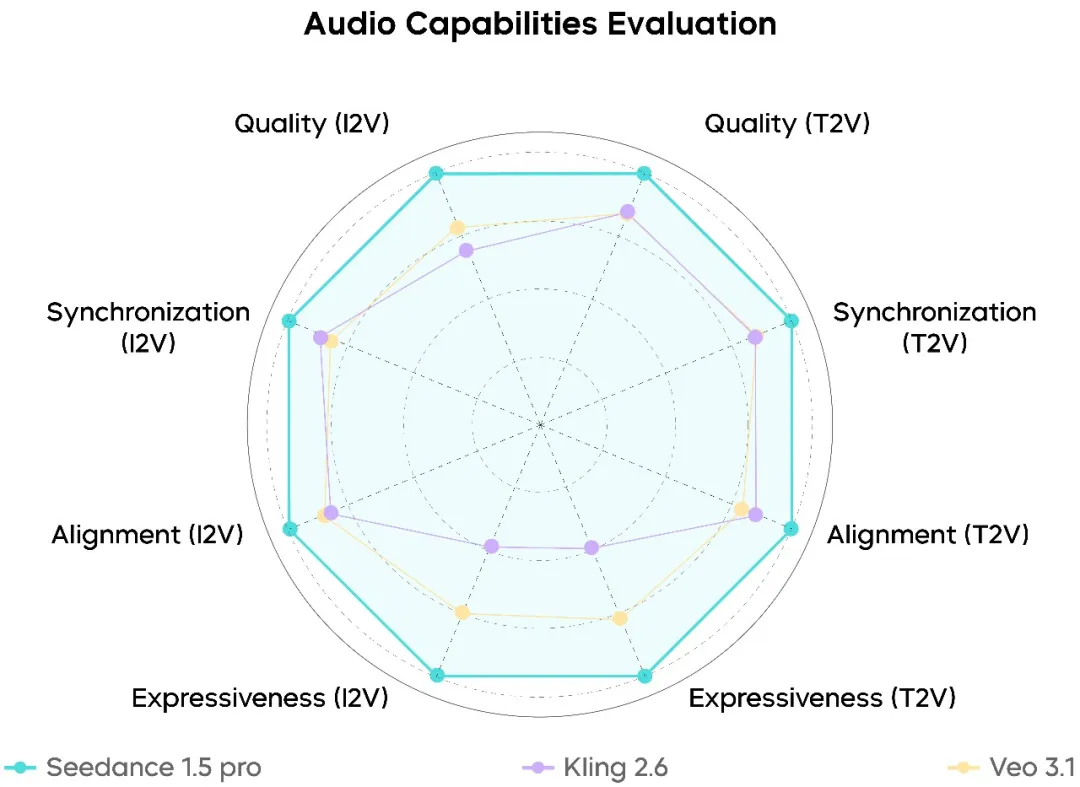
音頻生成性能
在音頻方面,Seedance 1.5 Pro 穩居當前模型的最頂層:
- 高度自然的人聲,機械制品明顯減少
- 更逼真的空間音頻和混響特性
- 明顯更少的音視頻對齐錯誤
性能在中文和方言密集的對白中特別強,其中發音完整性和清晰度已經滿足真實製作要求。
多模態共生成架構:視覺和音頻如何保持同步
Seedance 1.5 Pro 不是獨立模塊的拼湊——其訓練和推理管道從端到端進行了重新設計。
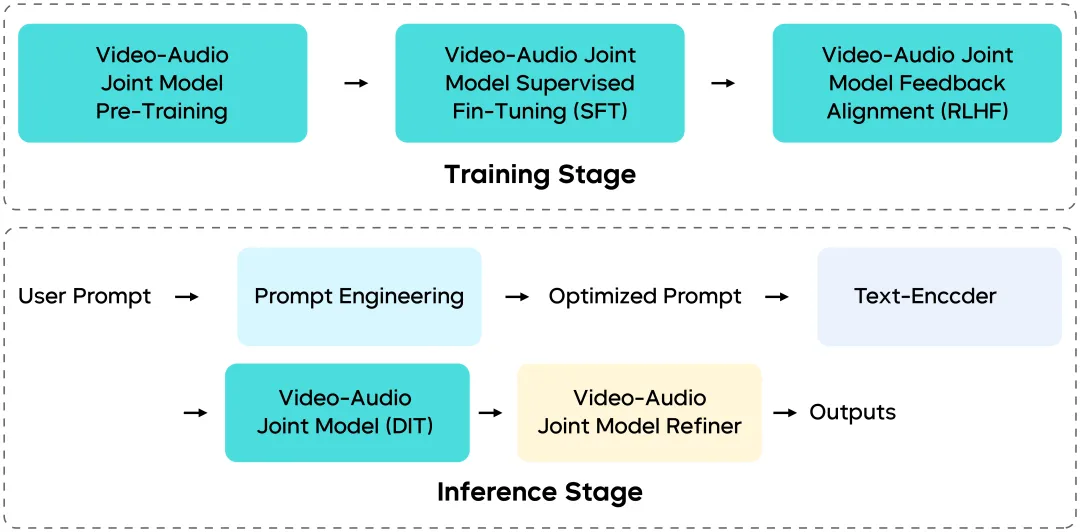
統一多模態架構(基於 MMDiT)
基於增強的 MMDiT 式架構 構建,該模型在同一時間空間內實現了視覺和音頻流之間的深度交互,確保:
- 時間同步
- 語義一致性
- 協調的情感和節奏
大規模混合模態、多任務訓練進一步提高了跨下游任務的泛化能力。
多階段數據管道
數據管道設計用於平衡:
- 音視頻對齐
- 運動表現力
- 基於課程的訓練時間表
除了傳統的視頻字幕數據外,還系統地引入了結構化音頻描述,使模型能夠內化更豐富的聯合音視頻語義空間。
細粒度後期訓練與 RLHF
高質量音視頻數據集用於監督式微調,以及專為音視頻輸出設計的 RLHF 模型,強化:
- 運動質量
- 視覺美感
- 音頻保真度
高效推理與部署就緒
通過多階段蒸餾、量化和並行推理優化:
- 函數評估數量 (NFE) 大幅減少
- 端到端推理實現 10 倍以上加速,同時保持質量
這種效率是 Seedance 1.5 Pro 能夠在 WaveSpeedAI 上可靠部署的關鍵原因。
生產就緒的用例
Seedance 1.5 Pro 特別適合:
- 跨境電商和本地化廣告
- 短篇敘事和劇集內容
- 動作漫畫和富有表現力的動畫
- 品牌故事講述和電影營銷
- 電影前期可視化和概念驗證
最後的思考
Seedance 1.5 Pro 的價值不在於證明模型可以生成聲音——而在於為音視頻協調成為可靠的默認選項奠定基礎。
對於追求可擴展內容製作的團隊,這種統一的、從零開始構建的方法承諾 更少的後期製作修復、更大的創意自由和一個設計用於在真實製作環境中堅持的生成視頻工作流。





