Nano Banana Pro API on WaveSpeed:如何呼叫及定價說明

曾經盯著WaveSpeed上的Nano Banana Pro API文檔,心想「我接下來到底該做什麼?」你不是唯一一個。我是Dora,我親自測試過數十個API,也經歷過文檔不全的端點和驚人的賬單郵件。在這份指南中,我會一步步帶你如何乾淨地調用Nano Banana Pro API,並避免可能讓你的項目預算措手不及的定價陷阱。
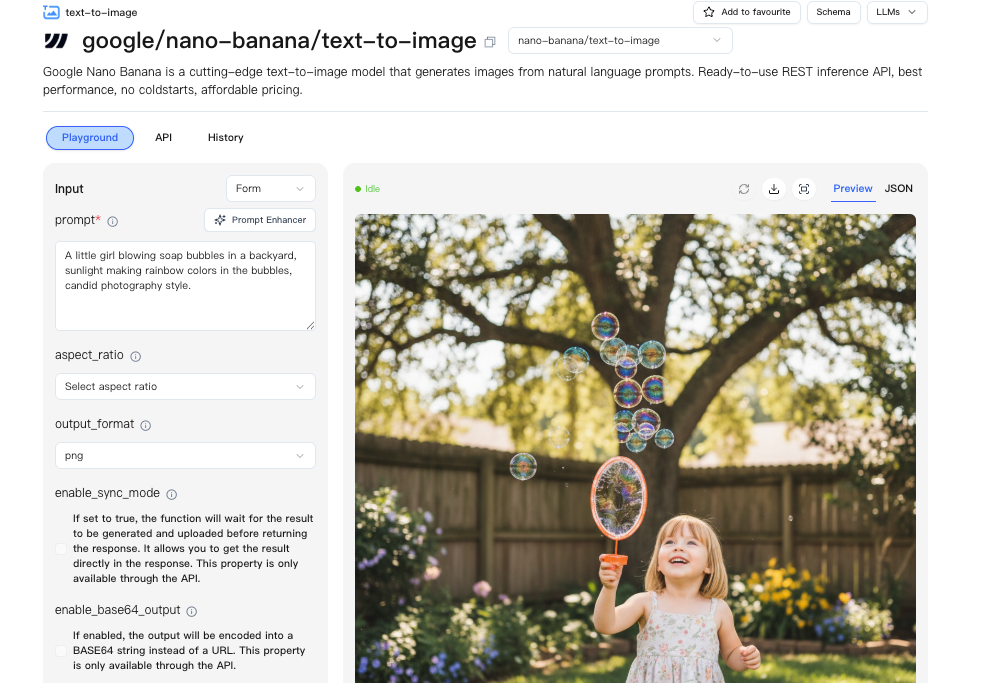
端點/流程
我沒有改變整個堆棧。我在Nano Banana Pro後面包裝了一個小適配器服務,這樣我就可以在提供商之間切換而不用拆除代碼。WaveSpeed的儀表板比我預期的更容易。一個端點、一致的身份驗證,以及一個簡單的配額視圖,我不需要四處尋找。
我的流程是這樣的:
- 一個小的預處理器清理輸入(將術語轉換為小寫、移除多餘空格、統一時區戳記)。
- 我向Nano Banana Pro端點發送請求,配合穩定的系統指令和一小組範例。
- 我快取穩定的提示詞和常見回應。沒什麼花哨的,只是本地TTL快取和WaveSpeed自身對相同載荷的回應快取。
- 我存儲追蹤資料:提示詞哈希、參數、延遲、令牌計數,以及出現時的錯誤代碼。
最有幫助的是可預測性。端點不會試圖代表我進行聰明的路由。如果我要求Nano Banana Pro,我就會得到它。在我的運行中,中位延遲在穩定的範圍內徘徊,方差在美國工作時間沒有我預期的那樣尖刺。不完美,但比我的基線更平靜。
 如果你更在乎穩定的路由和透明的使用情況而不是追求最便宜的成本項,試試我們的Wavespeed。我們專注於可預測的端點、乾淨的身份驗證,以及不需要猜測的使用可見性。
如果你更在乎穩定的路由和透明的使用情況而不是追求最便宜的成本項,試試我們的Wavespeed。我們專注於可預測的端點、乾淨的身份驗證,以及不需要猜測的使用可見性。
有一個小問題:串流選項有效,但在我的使用中它沒有足夠減少感知延遲。對於短文本,串流感覺像額外的麻煩。對於較長的摘要,它很愉快但並非必需。除了手動審查會話外,我都關掉了它。
關鍵參數
我通常不會調整參數,除非有理由。這裡有一些實際上很重要。
- 模型選擇:在我的測試期間,Nano Banana Pro保持一致(截至2026年1月)。沒有意外交換。這種穩定性是我持續使用的主要原因。
- 溫度:對於標籤和分類,我將其設置在接近零。這減少了不一致。對於有一點合成的摘要,0.3–0.4給了我更流暢的措辭而不偏離簡報。
- 最大令牌數:我為短任務設置了緊密的上限以避免膨脹的輸出。對於長摘要,我提供了慷慨的限制並依靠事後的硬字符計數。
- 系統指令:一個簡短、清晰的指令打敗了長策略塊。我用一句話設置角色,加上一個小的「不推斷,當不確定時顯示證據」的標準。我添加得越多,它就越多地對沖。
- Top-p vs. 溫度:我在調整溫度時保持top-p固定在1.0。混合兩者使差異更難追蹤。
令我驚訝的是模型對範例放置的敏感度有多高。指令後面的兩個具體範例比分散在五個範例中效果更好。當我將範例移到最後時,邊界情況的質量下降了。API沒有強制格式,但一致性有回報:相同的字段名稱、相同的順序、相同的標點符號。
質量調整
除了溫度和令牌上限之外,一些舉動改變了輸出的感覺:
- 短入門詞優於長策略。一行意圖+兩個範例比一頁指導產生的過度解釋要少。
- 證據提示有幫助。要求「引用觸發此標籤的短語」大大減少了虛構標籤。它也使質量保證更平靜,因為我可以快速發現幻覺。
- 軟約束>硬約束。說「目標是3–5個要點」比「恰好4個要點」效果更好。模型尊重邊界而不會變得緊張。
- 決定性框架:我在末尾添加了一點結構,「返回:標籤、信心(0–1)、證據(文本)。」它保持輸出整潔而不感覺像模式監獄。
在兩種情況下質量下降:混亂的OCR輸入和領域俚語。修復不是更聰明的提示。這只是一個小的預步驟:修剪垃圾字符、統一連字符,以及在頂部列出未知術語為「看到的術語」。一旦我這樣做了,模型就停止猜測奇怪的標籤。這在第一天沒有為我節省時間,但到第四次運行時,我注意到我沒有重新閱讀那麼多。更少的心理努力是有意義的。
定價考量
 我沒有追求最低的成本項。我想要可預測的支出以換取可預測的輸出。
我沒有追求最低的成本項。我想要可預測的支出以換取可預測的輸出。
在我的測試中,Nano Banana Pro在WaveSpeed上每千令牌的成本落在中等範圍。無聲的好處是更一致的令牌使用。因為有正確的提示形狀,模型不會嘮叨,我看到更少的意外尖刺。在我添加軟要點約束後,摘要的平均輸出長度穩定下來。
兩個小習慣在不傷害質量的情況下降低成本:
- 對於重複的指令和範例進行提示快取(WaveSpeed做了部分工作:我的適配器做了其餘的,所以相同的請求可以短路)。
- 對無操作情況進行早期退出。如果輸入太短或明顯無關,跳過調用並返回默認值。這聽起來很明顯,但我傾向於忘記它直到我看到賬單。
如果你處理的是不穩定的工作負載,即用即付模型對我來說是有道理的。如果你的使用是穩定且繁重的,你可能會看一下承諾的信用,但只能在一個月真實數字後進行。我不會基於直覺預先承諾。
批處理提示
我在試用期間進行了兩次每週批次。一些模式有幫助:
- 小的、穩定的批次大小。我定居在50個項目的塊上。並發是適度的(10–12)。吞吐量是好的,錯誤處理保持健全。
- 使用退避的重試預算。對於暫時性問題進行一次快速重試,然後是較長的退避,然後停放該項目。沒有無限迴圈。
- 冪等性令牌。相同的輸入、相同的哈希、相同的請求鑰匙。如果重試著陸,我不會支付兩次或雙重記錄。
- 預驗證。我在向API發送任何內容之前拒絕了缺少必需字段的輸入。無趣,但它節省了時間。
一個摩擦點是速率限制透明度。WaveSpeed的儀表板清楚地顯示使用情況,但在高峰期間的每分鐘上限感覺有點不透明。我通過在我的適配器中添加移動平均保護並將429s視為信號而不是錯誤來解決它。在那之後,批次運行得沒有戲劇。
錯誤處理
我保持錯誤處理簡單且可觀測,遵循REST API錯誤處理最佳實踐。
- 超時:我設置了保守的客戶端超時。如果請求運行很長,我將其標記為較慢的重試通道。長請求通常在重試時完成:關鍵是不堵塞快速通道。
- 4xx vs 5xx:4xx被停放以進行手動審查,除非是速率限制。5xx得到一短重試爆發。這避免了在壞輸入上浪費周期。
- 輸出中的保護欄:我要求模型始終包括信心分數。當分數下降到0.6以下時,我將該項目發送到人工審查隊列。簡單的分類,更少的遺憾。
- 日誌記錄:我只為標記的情況記錄原始提示和回應,而不是全部。隱私保持更乾淨,我的日誌更小。
有一些真正的模型錯誤,對諷刺的標籤充滿信心但錯誤。我沒有試圖通過更聰明的提示來克服這一點。我添加了一個諷刺檢查作為一個單獨的輕量級傳遞,然後才應用主標籤器。兩個步驟,更少的混亂。
範例載荷邏輯(非代碼解釋)
這是我發送的內容的形狀,用平淡的語言。
- 系統角色:關於工作的一句話。例如,「你是一個仔細的分類器,用一小組標籤標記營銷文案,並指出驅動決策的詞語。」
- 背景:任何奇怪術語的小詞彙表,加上兩個清晰的範例,一個乾淨的,一個棘手的。
- 指令:要返回的內容及其順序(標籤、信心、證據),以及語氣約束(簡短、無對沖語言)。
- 輸入:原始文本,除了空格清理外未觸及。
- 限制:證據的請求最大長度和標籤數量的上限。
在適配器方面,我從系統角色+範例+指令生成了一個穩定的哈希。如果該哈希與具有相同輸入的先前請求匹配,我檢查了快取。如果沒有,我使用溫度和為工作負載設置的令牌上限調用WaveSpeed的Nano Banana Pro端點。我通過鍵解析輸出,而不是按位置,所以小的措辭變化不會破壞任何東西。
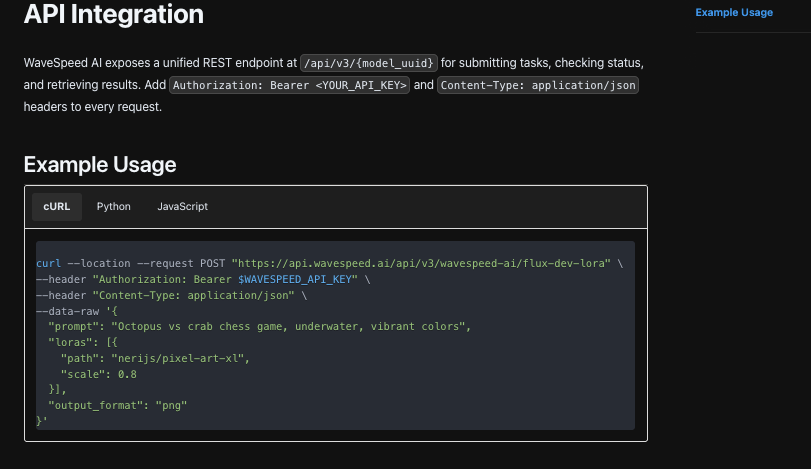 如果回應缺少任何必需的鑰匙,我沒有要求模型就地修復自己。我用短提醒重新發出提示:「僅返回三個鑰匙。」最多重試一次。在那之後,它進入了審查隊列。這使系統不會將自己循環到胡言亂語中。
如果回應缺少任何必需的鑰匙,我沒有要求模型就地修復自己。我用短提醒重新發出提示:「僅返回三個鑰匙。」最多重試一次。在那之後,它進入了審查隊列。這使系統不會將自己循環到胡言亂語中。





