Z-Image-Turbo LoRA現已登陸WaveSpeed:套用自訂風格(最多3個LoRA)
使用Z-Image-Turbo LoRA套用自訂風格、角色與品牌識別。最多可疊加3個LoRA,每張圖片僅需$0.01。內含訓練指南(每1000步$1.25)。

嗨,我是 Dora。你是否也和我一樣,希望模型原型不再偏離品牌風格——那個老是偏向青色的藍、邊緣逐漸柔化的品牌標誌、看起來……幾乎正確的產品照片。草稿階段差不多就算了,但這會產生雜訊。所以上週,我嘗試了在 WaveSpeed 上使用 LoRA 搭配 Z-Image-Turbo。不是為了追求新奇,而是想看看能否不用一直盯著提示詞,就把「差不多夠好」變成「好,可以出貨了」。
以下是我的筆記——哪些有效、哪裡卡住、以及我如何設定它,讓它一旦調好就不再礙事。
什麼是 LoRA?
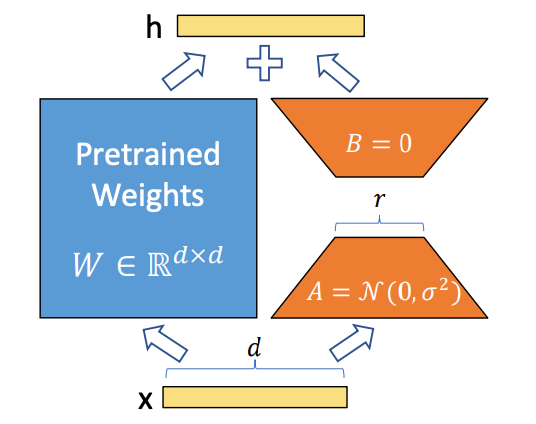 LoRA(低秩自適應)是一個小型、針對性的層,能將大型模型引導向特定風格、角色或美感,而無需重新訓練整個模型。把它想像成一個可以加上或取下的柔和濾鏡。基底模型保有其廣泛能力,而 LoRA 則教它一種偏好。
LoRA(低秩自適應)是一個小型、針對性的層,能將大型模型引導向特定風格、角色或美感,而無需重新訓練整個模型。把它想像成一個可以加上或取下的柔和濾鏡。基底模型保有其廣泛能力,而 LoRA 則教它一種偏好。
在實際操作中,LoRA 檔案體積小、訓練快、切換成本低。最後這點對工作流程很重要。我不想為每個品牌色調或角色準備一個獨立的模型檢查點。我想要一個快速的骨幹(Z-Image-Turbo)加上幾個可替換的調節旋鈕。
為何在 Z-Image-Turbo 上使用 LoRA?
 WaveSpeed 上的 Z-Image-Turbo 針對速度進行了優化,非常適合快速迭代,但速度本身無法解決「風格一致性」的問題。LoRA 填補了這個缺口。我可以:
WaveSpeed 上的 Z-Image-Turbo 針對速度進行了優化,非常適合快速迭代,但速度本身無法解決「風格一致性」的問題。LoRA 填補了這個缺口。我可以:
- 保持基底模型的高效能,
- 為某種視覺風格或角色套用預製 LoRA,
- 或針對自己的素材訓練一個小型客製化 LoRA。
讓我驚訝的是 scale(強度)參數給了我多大的控制空間。較低的 scale(0.3–0.6)保留了基底模型的優勢;較高的 scale(0.8–1.0)則會更強力地往學習到的風格推進,有時甚至過了頭。我從低值開始,慢慢往上調直到感覺對了。這個簡單習慣在那週幫我減少了約三分之一的重新渲染次數。
使用預製 LoRA
我先嘗試預製 LoRA,因為在摸清邊界之前我不想自行訓練任何東西。WaveSpeed 將 LoRA 當作外掛元件處理,指向一個檔案、設定 scale,就可以開始了。
尋找相容的 LoRA
相容性取決於格式和基底模型系列。如果某個 LoRA 是針對相似的擴散模型骨幹訓練的(並標註為與 Z-Image-Turbo 或其同系列相容),通常都能正常運作。我保留了一份簡短的檢查清單:
- 相同或相近的基底模型系列,
- 有提供的話查看版本說明(日期 + 模型標籤),
- 預覽圖庫要呈現多樣性,而不只是精心挑選的亮眼範例。
當某個 LoRA 看起來「太完美」時,我會猜測是過擬合。在我的測試中,這類 LoRA 在偏離特定範疇的提示詞下往往表現崩潰。品質較好的 LoRA 在我更換光線或鏡頭描述時依然能保持穩定。
API 參數:path 與 scale
 WaveSpeed 的 API 對每個 LoRA 使用簡單的結構:path(LoRA 檔案的位置)和 scale(套用強度)。path 可以是託管於 WaveSpeed 的資產或你自己控制的簽名 URL。scale 是一個浮點數。我大多數時間都在 0.35 到 0.7 之間操作。低於 0.3 時,我常常感覺不到它有在作用;高於 0.8 時,它有時會把整個構圖推倒重來。
WaveSpeed 的 API 對每個 LoRA 使用簡單的結構:path(LoRA 檔案的位置)和 scale(套用強度)。path 可以是託管於 WaveSpeed 的資產或你自己控制的簽名 URL。scale 是一個浮點數。我大多數時間都在 0.35 到 0.7 之間操作。低於 0.3 時,我常常感覺不到它有在作用;高於 0.8 時,它有時會把整個構圖推倒重來。
從實際使用中的小提示:如果 path 錯誤或資產在沒有正確 token 的情況下設為私有,你不一定會收到明顯的錯誤——你只會得到看起來像基底模型輸出的圖像。當結果感覺莫名地平淡時,我會再次檢查 path。
疊加多個 LoRA(最多 3 個)
你可以疊加最多三個 LoRA。我嘗試過一個用於色彩處理、一個用於品牌質感、一個用於角色特徵。這樣可行,但前提是我平衡好各自的 scale。如果兩個 LoRA 互相衝突(比如一個堅持柔和的底片顆粒感,另一個要加上清晰的產品光澤),圖像就會顯得優柔寡斷。我的原則是:
- 每個都從 0.3 開始,
- 找出錨點 LoRA(不可妥協的核心視覺),
- 緩慢地提高那個 LoRA 的 scale,
- 微調其他的,直到它們互補而非競爭。
當我同時需要品牌感和固定角色時,疊加幫我省下了不少時間。但當我試圖強行融合三個風格鮮明的 LoRA 時,它並沒有省時——那只會把我推回試錯的迴圈。
API 實作
以下是我在一個小腳本中的接法。我用的是實際出貨的提示詞:附帶背景變化的產品模型圖,加上幾張用於內部文件的角色照。
LoRA 參數結構
請求本體包含一個 loras 陣列,每個項目包含:
- path:字串(WaveSpeed 資產路徑或簽名 URL)
- scale:浮點數(0.0–1.0;建議從 0.3–0.7 開始)
其他 Z-Image-Turbo 參數(prompt、negative_prompt、seed、steps、width/height)照常使用。固定 seed 幫助我在調整 scale 時進行同等條件的比較。
Python 程式碼範例
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/v1/z-image-turbo/generate"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# 根據帳號設定,預期回傳 base64 圖片或 URL
print(result.get("images", []))在我的測試中,Z-Image-Turbo 用 16 步就足以達到預覽品質。最終圖像我會調到 22–24 步,這在我的帳號上每張圖大約多花 0.3–0.6 秒,完全可以接受。
平衡 LoRA Scale
我的迭代方式如下:
- 固定 seed,
- 將所有 LoRA 設為 0.3,
- 選出錨點 LoRA,每次提高 0.1 直到感覺正確,
- 以 0.05–0.1 的幅度微調其他 LoRA。
在調整 scale 時保持 seed 固定,讓我能直接觀察效果。滿意平衡後,再解除固定 seed 以增加變化。這一開始並沒有幫我省時——我花了 15–20 分鐘只是在找感覺。但到了第三天,我注意到自己已經停止調整提示詞了。風格由 scale 負責承載,我可以專心處理版面和文案。
訓練客製化 LoRA
試過預製 LoRA 之後,我為客戶的瓶身形狀和標籤風格訓練了一個小型 LoRA。目的是減少來回溝通——因為瓶頸角度和標籤光澤一直在飄移。
準備訓練資料(ZIP 上傳)
我蒐集了 18 張圖片、清理背景、並保持 metadata 一致。我將它們壓縮成 ZIP,簡單的資料夾結構、小寫檔名、無空格,然後上傳。當標籤文字很重要時,我為每張圖片新增了 3–4 條說明文字;不重要時,說明文字保持精簡。更多說明文字有助於讓標籤保持清晰可讀。
有個小阻力:看起來幾乎相同的圖片沒什麼幫助。我移除了近似重複的圖片後,過擬合的情況減少了。
訓練參數
我保持輕量設定:
- 解析度:768 正方形裁切,
- 批次大小:1,
- 學習率:保守的預設值,
- 訓練步數:3,000–6,000 步,適合風格 + 形狀,
- 網路秩(r):適中;設太高會讓它比我想要的「更強勢」。
當步數超過約 8,000 時,它開始在我沒有要求的提示詞中強行插入瓶子。不理想。步數少一點加上更乾淨的資料集,才是正確做法。
定價:每 1,000 步 $1.25
 我的兩次訓練(3,500 步和 5,000 步)以每 1,000 步 $1.25 計算,合計花費 $10.63。如果這個 LoRA 能使用幾個月,這個費用是合理的。
我的兩次訓練(3,500 步和 5,000 步)以每 1,000 步 $1.25 計算,合計花費 $10.63。如果這個 LoRA 能使用幾個月,這個費用是合理的。
典型訓練預算
我現在會這樣預估預算:
- 純風格 LoRA:2,000–4,000 步($2.50–$5.00),
- 含表情的角色:5,000–8,000 步($6.25–$10.00),
- 產品形狀 + 標籤細節:3,000–6,000 步($3.75–$7.50)。
我會先跑一次較短的訓練,確認結果沒問題,再視需要補足步數。兩次較小的訓練,勝過一次漫長的過擬合。
使用案例
以下是 LoRA 搭配 Z-Image-Turbo 幫我加速出貨的場景——不是每天都用得上,但只要任務符合,就很可靠。

品牌風格一致性
如果你厭倦了每次提示詞都要重新輸入品牌風格描述,一個 scale 設在 0.4–0.6 的輕度風格 LoRA 就能保持色彩、對比和質感的一致性。我用這個來製作社群變體和網頁橫幅。它不會讓圖片變得出色,只是讓它們保持一致——這正是重點。每份交付物省下了大約 5–7 分鐘,跳過了第二輪「調整氛圍」的步驟。
角色 LoRA
為了內部文件和出現在引導畫面中的輕量吉祥物,角色 LoRA 讓各種角度下的特徵保持穩定。將它與柔和的色彩處理疊加是可行的,但前提是我把角色 LoRA 的 scale 降到 0.35。再高一點就會把光線效果全部蓋掉。調好之後,它消除了一種奇怪的心理負擔:我不再擔心臉部特徵會飄移。
產品特定美感
客製化的瓶子 LoRA 減少了標籤變形,並在近景拍攝中保留了瓶頸的幾何形狀。並不完美——緊湊的反射仍然需要試幾次,但它降低了無法使用的渲染結果數量。最安靜的收穫是可預測性。當我輸入「亞麻布上的四分之三角度」時,我得到的就是那個,而不是意外的變體。
適合哪些人:已經清楚知道自己想要什麼、不想再每次跟模型重新磨合的人。不適合哪些人:每次都在探索全新狂野風格的人。LoRA 是一個穩定器,當你重視「更少驚喜」勝過「更多花樣」時,它才真正發光。





