Z-Image LoRA:它的含義以及何時需要它(初學者友善)

嗨,朋友們。我是Dora。上週我沒有計畫訓練任何東西。我只是想要一個穩定的小幫手,一個坐在我截圖角落裡的插圖人物。提示詞一次又一次地讓我接近,然後偏離。眉毛改變了。顏色滑落了。週二(2026年1月13日),經過幾次險些成功後,我嘗試了Z-Image LoRA。我預期會掉入兔子洞。但這更像是一條短走廊。
這不是勝利圈。它不是瞬間完成的。但這個設置減少了足夠的摩擦,讓我停止考慮設置,開始考慮我的圖像。以下是什麼有效、什麼無效,以及何時你可能根本不需要LoRA。
Z-Image LoRA 一分鐘速覽
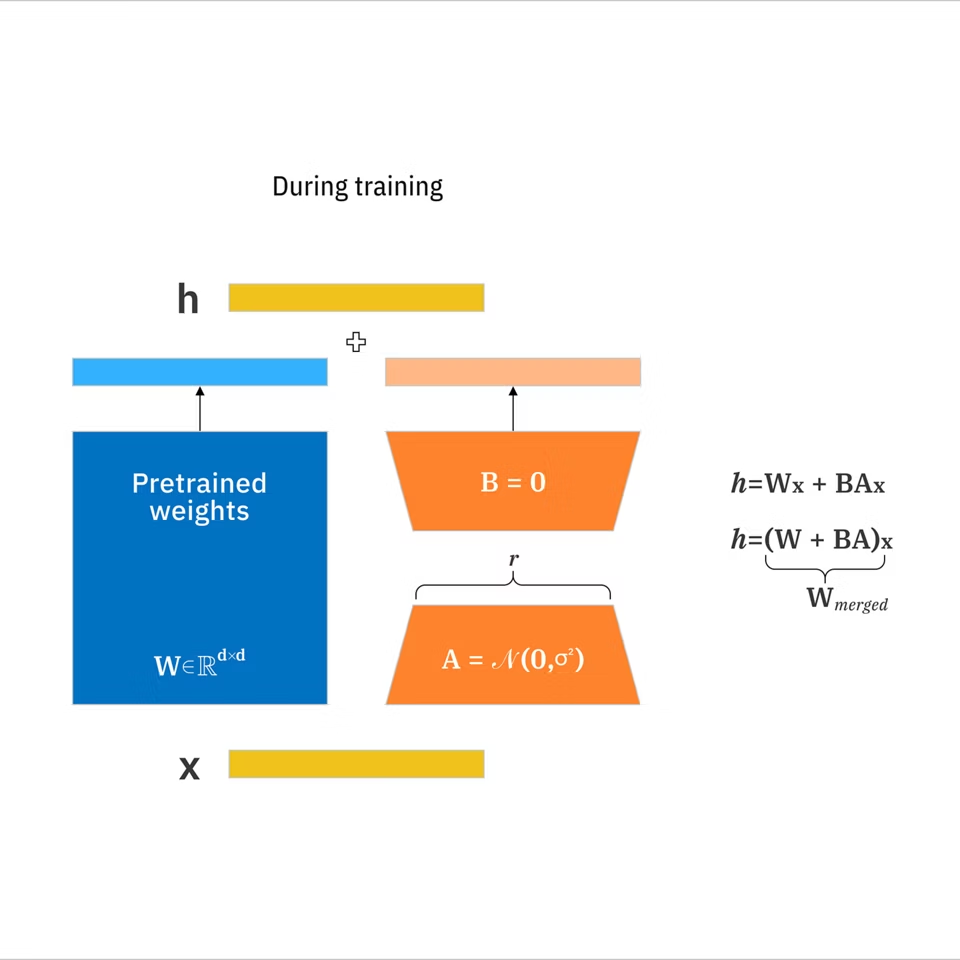
LoRA(低秩適配)是一個小型附加組件,你可以在基礎圖像模型上訓練它,將其推向特定風格或主題,而無需重新訓練整個模型。
 Z-Image LoRA(初學者友好)的優點:
Z-Image LoRA(初學者友好)的優點:
- 隱藏了可怕的旋鈕。你仍然選擇一些基本項目(圖像、標題、目標),但默認值是合理的。
- 訓練速度足以進行迭代。我的第一次嘗試(10張圖像)在中等GPU上耗時約12-18分鐘。
- 加載像一個圖層。你在生成工具中切換它,像往常一樣提示,加上一個可選的觸發詞。
你得到的是:一個小文件,在你需要一致性、標誌、角色、毛筆水彩風格時輕推模型,而不會將你鎖定。如果你不打開它,基礎模型表現如常。
你不需要LoRA的情況
我是帶著愛說的:我們很多人訓練太快了。幾種情況我不會費力:
- 基礎模型已經很接近了。如果一個簡短的提示詞加上參考圖像能給你8/10的結果,你就完成了。IP-Adapter或圖像提示可能就足夠了。
- 你需要變化,而不是一致性。如果每個輸出都應該有所不同,LoRA可能會過度控制。
- 一次性視覺效果。對於單個橫幅,我會花五分鐘時間調整提示詞,而不是設置訓練。
- 約束在構圖而不是身份中。像ControlNet或姿態指導這樣的工具可以形成佈局,而無需教模型新概念。
我使用的快速測試:如果簡單的seed掃描和2-3個提示詞調整無法在五張圖像中保持我關心的元素(相同的角色、相同的標誌比例),那就是我考慮LoRA的時候。否則,我保持簡單。
LoRA何時有幫助
我在本週(2026年1月)的兩種情況下最能感受到差異:
- 一個我想在文檔中重複使用的小吉祥物。提示詞一直在搖擺眼睛和襯衫顏色。經過短期LoRA後,這些穩定了下來,我可以專注於姿態和背景。
- 圖表的柔和鉛筆紋理。我可以提示「鉛筆草圖」,但著色每次都改變。一個15張圖像的風格LoRA為我提供了穩定的線條質量,而不會固定內容。
表明LoRA可能會有幫助的信號:
- 你需要在許多場景中使用相同的主題。
- 特定的藝術紋理很重要(交叉孵化、膠版印刷點、厚重粉彩邊邊)並且不斷漂移。
- 你想減少提示詞體操。訓練後,我的提示詞從80-100個token下降到30-40個。心理努力下降比時間更多。
讓我吃驚的是影響感覺多麼安靜。沒有戲劇性的前後對比。只是更少的重試,更少的「幾乎」。
數據要求
 我保持這個簡單,效果比我預期的要好。上週兩次短運行的一些注意:
我保持這個簡單,效果比我預期的要好。上週兩次短運行的一些注意:
數量
- 角色/主題: 8-20張圖像就足夠了,如果它們多樣化(角度、光線、輕微服裝變化)。我使用了12張。
- 風格/紋理: 10-30張共享相同外觀但內容不同的圖像。我使用了15張。
質量
- 分辨率: 提供與你的生成大小大致匹配的圖像。如果你計畫以1024生成,不要在微小的256裁剪上訓練。
- 多樣性勝過數量: 同一姿態的五個副本對模型教得很少,並將其推向過度擬合。
- 乾淨背景對角色有幫助: 繁忙的場景會模糊信號。
標題
- 簡短而直白:「一個圓眼睛、紅色襯衫的小藍色吉祥物」、「鉛筆草圖、交叉孵化、柔和陰影」。
- 在命名上保持一致。如果你為角色發明唯一名稱(例如「mori-kiko」),在每個標題中都使用它,以便以後可以觸發它。
- 你可以從自動標題開始,然後輕輕清理它們。我削減了不反映核心思想的形容詞。
我使用的過程
- 12張主體照片(正面/三角度/側面),中性背景。
- 15張來自我自己圖表的風格框架,相同的紙張紋理。
- 一次通過,默認等級,輕微正則化。訓練時間:在租用的A10G上約16分鐘。設置:約10分鐘。第二次運行使用了20%更少的步驟並表現良好。
如果你只記得一件事:更少、更清晰的圖像勝過大型、有噪聲的文件夾。
風格vs角色LoRA
我過去常常把這些歸為一類。它們的表現不同。
角色/主題LoRA
- 目標: 教一個特定的身份(人、吉祥物、產品)。
- 數據: 一致的主題,不同的背景:如果面部身份很重要,近距離面部。
- 提示詞: 保持觸發名稱加簡短描述。讓LoRA處理身份:你控制姿態/場景。
- 風險: 過度擬合服裝或背景。混合它們。
風格/紋理LoRA
- 目標: 教表面質量(線條、色調、筆觸、粒度)。
- 數據: 許多不同的主題,一種風格。
- 提示詞: 不需要觸發名稱,但簡單標記有幫助(「sketchline風格」)。
- 風險: 風格吞沒內容。如果一切都變成相同的軟繪畫,降低強度。
強度和混合
- 大多數工具會公開LoRA權重。對於角色,我很少超過0.8,對於風格,我很少超過0.6。小推動很重要。
- 你可以堆疊兩個LoRA(一個風格,一個角色)。當一個佔主導地位,另一個保持在0.4以下時,我取得了最好的結果。
我學會了把角色LoRA看作「誰」,風格LoRA看作「如何」。簡單,但它讓我不會責備錯誤的東西。
常見誤解
我經常碰到的幾個說法,以及我實際看到的:
- 「你需要數百張圖像。」我用12張訓練了一個可用的角色。更多有幫助,但只有在它們多樣化和乾淨時。
- 「它需要數小時。」使用適度的GPU和初學者預設,我的運行時間在20分鐘以內。重型、自定義配置可能需要更長時間。
- 「LoRA取代了提示詞工程。」它減少了調整但沒有消除它。我仍然提示構圖、光線和心情。
- 「一個LoRA適合所有模型。」不總是。在一個基礎上訓練的LoRA可以轉移到兄弟模型,但結果會改變。我把它們視為相關的,而不是可互換的。
- 「更高的強度=更好。」超過一定點,圖像陷入相同性。如果細節模糊,降低權重。
- 「自動標題未編輯就沒問題。」它們是一個很好的開始。我仍然修剪了不是概念一部分的奇怪形容詞(「不祥」、「電影般」)。
這一切都不是神奇的。這些都是小的、可重複的調整,複合在一起。
快速詞彙表
- LoRA: 一套緊湊的學習權重更新,可在不重新訓練所有內容的情況下將大型模型適配到目標概念。根據IBM的LoRA文檔,與完整微調相比,它可以將可訓練參數減少10,000倍。
- 基礎模型: 你生成的基礎(你在任何LoRA之前加載的東西)。
- 等級(r): 控制LoRA表達力的設置。更高的等級可以捕捉更多細微差別,但可能過度擬合並增加大小。
- 權重/強度: LoRA在推理時對生成的影響程度。
- 觸發詞: 你在提示詞中使用的唯一token來調用主題LoRA(例如,你在標題中使用的編造名稱)。
- 過度擬合: 當模型記住訓練圖像並停止泛化時。表現為近似副本。
- 正則化: 防止過度擬合的技術或額外數據。
- UNet/文本編碼器: 處理圖像和文本的模型部分。一些訓練同時更新兩者:初學者預設通常更多地觸及圖像側。
- 標題: 與每個訓練圖像配對的文本。
- 檢查點: 模型或LoRA的已保存狀態。
如果其中任何一個感覺模糊,你仍然可以訓練。初學者預設旨在讓你遠離麻煩。
WaveSpeed上的後續步驟
我使用WaveSpeed上對初學者友好的路徑運行Z-Image LoRA,而無需追趕設置。流程很平靜:
- 選擇基礎模型。
- 放入8-20張圖像和簡短標題。
- 選擇「風格」或「角色」。
- 開始訓練並喝茶。
- 加載LoRA進行生成,並嘗試兩個權重(0.4和0.8)來感受範圍。
最有幫助的是將第一次運行視為草圖。我尋找兩件事:身份是否在五個提示詞中保持,風格是否保持其紋理而不吞沒內容?如果一個失敗了,我調整了數據集,而不是只調整滑桿。
如果你正在處理相同的約束、漂移的角色、搖擺的紋理,這值得一看。這對我有效:你的里程可能不同。
這正是我們構建WaveSpeed的原因。當角色漂移、風格搖擺、提示詞變成體操時,我們想要一種更平靜的方式來實現一致性,而無需過度工程。在WaveSpeed上,我們以初學者友好的流程運行Z-Image LoRA — 清晰的默認值、快速迭代,以及足夠的控制來保持身份和紋理穩定,所以你可以花更少的時間重試,花更多的時間實際製作圖像。
→ 在WaveSpeed上訓練簡單的LoRA
 我為自己保留了一個小筆記:我在提示詞中爭鬥的詞越少,我對眼前圖像的注意力就越多。這是我不想自動化的部分。
我為自己保留了一個小筆記:我在提示詞中爭鬥的詞越少,我對眼前圖像的注意力就越多。這是我不想自動化的部分。





