DeepSeek V4 對比 Claude Opus 4.5 編程能力:基準測試比較

嘿各位!我是Dora。上週日早上,我在編輯器和聊天視窗之間跳來跳去,想修一個不穩定的測試,結果模型一直編造一個根本不存在的import。沒什麼大不了的,只是這種紙紙剪紙似的小煩惱拖慢了我的手速。我想看看換一個模型是否能減輕負擔,不只是掛鐘時間,還有信任我提交到倉庫的代碼所需的心智努力。
所以我花了上週(1月27日–2月1日,2026年)做了一個簡單、可重複的循環:相同的任務、相同的倉庫快照、在DeepSeek V4和Claude Opus 4.5之間交替。這不是實驗室研究。這是我在把模型接入CI之前會做的那種檢查。如果你也在權衡DeepSeek V4和Claude Opus 4.5用於編程,這些是我在做出改變前想讀的筆記。

當前基準領導者
SWE-bench驗證排名
當我需要快速瞭解風向何處,我從公共排行榜開始。在SWE-bench驗證排行榜上,DeepSeek的最新模型和Anthropic的較新Claude系列都坐在頂端附近,隨著提示、工具和評估框架每週都在變化,差距很小。對我來說重要的不是單一數字,而是模式:哪些模型能一致地解決端到端的問題而不依賴工具拐杖,它們對提示調整有多敏感。
根據2026年2月初的我的快速判讀:
- DeepSeek V4在多文件、倉庫規模的任務上表現出強勁的動力,當你給它它要求的所有上下文時。它受益於長提示和明確的文件映射。
- Claude Opus 4.5取得穩定的成果,當我削減上下文或删除系統消息時,往往會回退較少。它不華麗,但下限感覺很高。
HumanEval分數
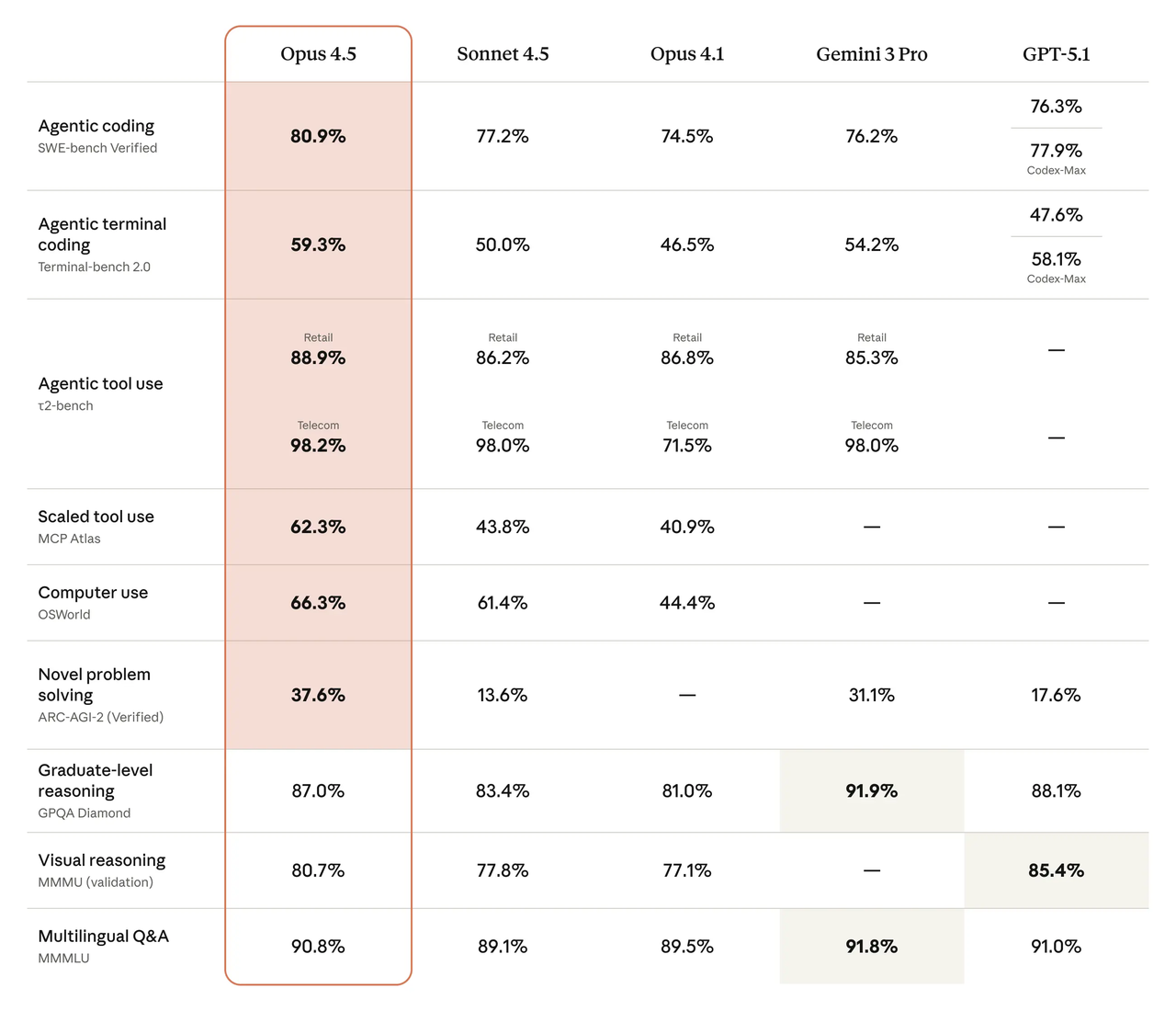
HumanEval更狹隘,是簡短的編程問題,有單位測試,但它對開箱即用的代碼生成是一個有用的氣味測試。OpenAI HumanEval倉庫上的當前摘要和EvalPlus排行榜等社區追蹤器將兩個模型放在頂級層。我在這裡不固守確切的pass@1:我觀察跨種子的穩定性以及模型多久依賴語言技巧而不是寫直接、地道的代碼。
 在我的運行中,DeepSeek V4有時會產生更長、更「解釋性」的解決方案,可以,但不總是我在緊密差異中想要的。Claude Opus 4.5更經常返回緊湊的函數,它們在測試中順利通過,沒有額外的評論。基準暗示這一差異:親身工作使其顯而易見。
在我的運行中,DeepSeek V4有時會產生更長、更「解釋性」的解決方案,可以,但不總是我在緊密差異中想要的。Claude Opus 4.5更經常返回緊湊的函數,它們在測試中順利通過,沒有額外的評論。基準暗示這一差異:親身工作使其顯而易見。
每個模型的優勢
長上下文(DeepSeek)
如果你想端到端地重現此設置,我整理了一個簡短的DeepSeek V4快速入門指南,它帶你瞭解我在這裡依賴的聊天和API基礎知識。
我給兩個模型一個真實任務:重構一個小型FastAPI服務,它已靜靜地長成一團亂麻。大約14個文件很重要,加上一個README,它是…樂觀的。我壓縮了倉庫快照,並提供了文件摘要以及我用簡短腳本生成的調用圖。DeepSeek V4對這種分散感到平靜。它跟踪了跨文件效應,當我要求分階段計劃時不會驚慌:介面優先、測試其次、處理程序最後。令人驚訝的部分是它使用結構提示的效果多麼好,當我交給它一個簡單的檔案名稱和責任的「映射」時,它停止建議編輯不存在的檔案。
兩個實際注意事項:
- 它需要喘息的空間。當我過度削減上下文時,它變得謹慎,開始要求查看我已經提供的檔案。一旦我給了它完整的圖景,它就乾淨地移動。
- 它很好地處理「我缺少什麼?」提示。我根據測試套件要求邊界情況,它浮出我遺忘的三個:空認證頭、損壞的分頁參數和錯誤日誌中的慢路徑。
這最初沒有節省時間。初始設置、打包上下文、寫一個簡短的文件映射,花了大約20分鐘。但經過幾次運行後,心智負擔下降了。我沒有被迫進行那麼多「我有沒有告訴它X?」的擔憂。如果你的編程日看起來像大型差異分散在多個模組中,DeepSeek V4在上下文變寬時有著穩定的手。
代碼可靠性(Claude)
 Claude Opus 4.5以不同的方式說服了我:邊界更少尖銳。當我要求最小修補程式時,它給了我一個。當我要求帶幹運行的三步計劃時,它不會編造命令。而且它抵抗了「改進」我沒有要求的東西的衝動。
Claude Opus 4.5以不同的方式說服了我:邊界更少尖銳。當我要求最小修補程式時,它給了我一個。當我要求帶幹運行的三步計劃時,它不會編造命令。而且它抵抗了「改進」我沒有要求的東西的衝動。
一個小例子:我有一個關於時區數學的不穩定測試。我的提示很直率:「修復測試而不改變生產代碼,並用一句話解釋根本原因。」Claude建議參數化tz固定裝置並調整單一斷言以使用意識日期時間。它第一次通過。DeepSeek也修復了它,但在同樣的呼吸中它嘗試重構助手。沒有錯誤,只是比我想要的要重。
在五個任務中,Claude的差異一致更小。更少的import出現無處。當它確實猜測時,它留下了一個整潔的筆記:「假設pytz可用:如果不是,請用zoneinfo替換。」那種對沖建議很容易審計。
兩個限制出現了:
- Claude在性能上玩得很安全。在一個情況下,它選擇了clarity而不是DeepSeek立即指出的簡單O(n)改進。我不得不推動它:「在相同的約束下最佳化。」它做了,但它不會首先跳躍。
- 非常長的提示,我更快地達到了天花板。摘要有幫助,但當我希望模型「將整個應用保留在其頭部」時,DeepSeek感覺不那麼擁擠。
如果你的日子主要是手術補丁、測試修復和API周圍的膠水代碼,Claude Opus 4.5保持變化精簡和可預測。在實踐中,這是我能感受到的可靠性。
如何運行你自己的比較
 如果你在DeepSeek V4和Claude Opus 4.5用於編程之間搖擺不定,一個簡短、無聊的實驗告訴你比任何排行榜更多。以下是我使用的循環,隨意調整。
如果你在DeepSeek V4和Claude Opus 4.5用於編程之間搖擺不定,一個簡短、無聊的實驗告訴你比任何排行榜更多。以下是我使用的循環,隨意調整。
1. 挑選與你周一致的任務
- 一個倉庫雜務(重構或模組提取)
- 一個不穩定的測試
- 一個API集成變化
- 一個小型演算法調整
保持每個在45分鐘以下。給互動設定時間框,不只是模型的生成。
2. 凍結輸入
- 固定一個特定提交。在你測試時不要移動目標。
- 決定模型可以看什麼:完整檔案對摘錄。如果你傳遞摘錄,寫一個簡短的檔案映射。
- 對兩個模型使用相同的系統提示風格。我保持它平凡:「你是有幫助的編程助手。傾向於最小差異和可運行的代碼。」
3. 寫你可以重複使用的提示
- 任務:「以下是目標、約束和測試。」
- 上下文:檔案列表或摘要,加上已知的陷阱。
- 輸出格式:「提出計劃(項目符號),然後差異,然後是一句風險筆記。」
4. 為兩者捕獲相同的信號
- 嘗試通過測試(1–N)
- 差異中改變的行(粗略沒問題)
- 你必須為模型寫的筆記(「停止編輯X」、「使用現有幫助程式Y」)
- 第一個綠色測試的時間
5. 看守泄漏
- 禁用工具,除非你計劃比較工具使用。如果一個模型撥殼而另一個不這樣做,你沒有測試相同的東西。
- 如果你允許檢索,請將兩者指向相同的文檔快照。
6. 用基準進行理智檢查,不要敬拜它們
- 瞥一眼SWE-bench驗證,看看你的結果是否看起來狂野不同。如果他們這樣做,在你責備模型之前檢查你的提示。
- 對於咬大小的問題,在官方倉庫上或在本地運行一些。跨種子的一致性比單一運行更具啟發性。
7. 可選:添加一個微小的標準
評分1–5:
- 差異極簡主義(它是否只接觸了它需要的東西?)
- 固定裝置紀律(測試、環境、依賴)
- 恢復行為(當你指出錯誤時它是否自我更正?)
- 解釋品質(一或兩個清晰的句子,不是博客文章)
我在實踐中看什麼
- 模型是否第一次尊重約束?
- 當它錯誤時,它是否以一種容易發現的方式錯誤?
- 我是否感到安全讓它提議補丁,同時我在進行上下文切換?
這對我有效,你的里程數可能會有所不同。重點不是選擇一個贏家:它是看哪一個在你的代碼、你的時間表上減少你的認知拖拽。





