SkyReels V4是什么?首个统一视频音频AI模型详解
SkyReels V4是首个开源AI,能够同时生成视频和音频——分辨率达1080p/32FPS。本文介绍它的功能、工作原理及其重要意义。

你好,我是 Dora。那天我生成了我的第一个 SkyReels V4 视频。十五秒,一只猫在黄昏时分穿过一条被雨水浸透的小巷。视频效果不错——1080p,动作流畅,光线自然。但让我驻足的是音频。脚步声踩在水坑里溅起的声音。远处的车流声。小巷墙壁隐约的回响。所有这些同步生成,完美配合,而我根本没有碰过任何音频编辑工具。
这才是让我觉得不一样的地方。
V4 之前所有视频 AI 工具都存在的问题
为什么纯视频生成总让人感觉不完整
大多数视频 AI 工具生成的都是无声片段。 Runway、Pika,甚至早期的 SkyReels 版本——它们只产出画面,仅此而已。你得到的是一段美丽的十秒海浪拍岸镜头,却完全是无声的。浪打不响,风吹无声,没有任何环境音。
这并非技术上的疏忽。在生成视频的同时同步生成音频,确实是件极难的事。音频不仅需要匹配整体场景,还需要匹配具体的视觉事件——脚踩到地面时的脚步声、门关上时门扇摆动的声音、声音与口型的同步。
“后期加音频”的瓶颈
标准工作流变成了:生成视频、导出、打开音频编辑器、手动添加音效或音乐、逐帧同步、再次导出。一段 15 秒的片段,这套流程可能需要 20 到 30 分钟。
上个月我用 Pika 的输出试过这套流程。视频看起来很专业,但寻找合适的环境音、把它们与视觉提示对齐、再想办法避免那种”显然是后期加上去的”感觉,花的时间比生成视频本身还要长。整个工作流程感觉很割裂——就像买了辆车,却还得自己另外安装发动机。
SkyReels V4 究竟是什么
由 SkyworkAI 构建(V1/V2/V3 版本演进说明)
SkyworkAI 于 2025 年初发布了 SkyReels V1,这是一个基础的文本生视频模型。V2 随后推出,采用扩散强制架构,通过自回归序列实现了无限时长的生成。V3 于 2026 年 1 月发布,引入了多模态上下文学习——你可以输入参考图像、音频片段或现有视频,它会生成连贯的续接内容。

V4 于 2026 年 2 月 25 日正式上线,代表着一种截然不同的跨越。V3 是在原有基础上添加功能,而 V4 则是围绕一个双流系统对整体架构进行了重构,能够同时生成视频和音频。
“统一视频-音频基础模型”究竟意味着什么
技术论文将 V4 描述为采用了多模态扩散 Transformer(MMDiT),具备两条并行分支。一条分支合成视频帧,另一条生成时间对齐的音频。两条分支共享一个基于多模态大型语言模型的文本编码器,这意味着它们对你的提示词拥有相同的语义理解,并在整个生成过程中保持同步。
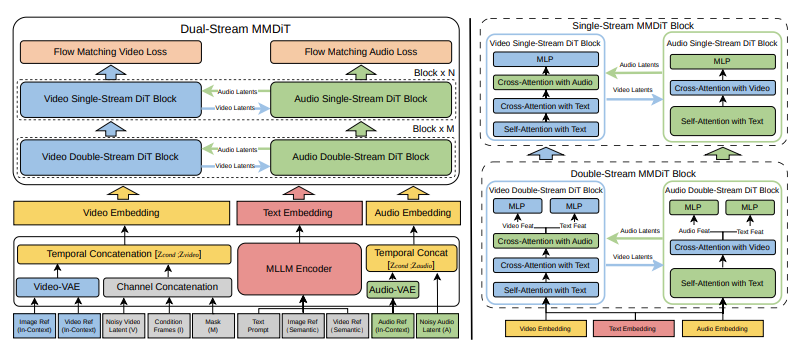
这不是在视频生成上硬加一个音频模块,而是一个单一模型,将视觉与声音视为同等重要的输出,基于对场景相同的潜在理解同步生成。
在实际使用中,这意味着当你输入”一位女性在讲台上发言”时,模型既生成她嘴唇动作的视觉画面,也生成实际的语音音频,并在帧级别保持同步。当你生成”大雨打在金属屋顶上”时,你得到的既有雨滴滑落的视觉画面,也有那种特有的金属敲击声——不是大致匹配,而是作为一个统一的视听事件同步生成。
核心功能一览
单一提示词同时生成视频与音频
单提示词生成是其核心能力。 你输入”雷声滚过沙漠地貌”,V4 就会生成 15 秒的乌云汇聚、闪电划过,以及与视觉时机完美匹配的隆隆雷声。无需单独的音频生成步骤,无需手动同步工作。
我用对话场景测试了这一功能。输入”两个人在嘈杂的咖啡馆里争吵”,得到的不只是对话的视觉画面,还有背景嘈杂声、餐具碰撞声,以及说话者随着手势力度起伏的声音。口型同步并不完美——我注意到有几处时机轻微漂移——但已经比我手动同步的任何结果都要好。
1080p / 32FPS / 15 秒输出
技术规格:分辨率最高可达 1080p,每秒 32 帧,最大时长 15 秒。作为参照,大多数竞争工具的上限是 720p,或者生成高清输出需要明显更长的时间。
15 秒的时限比听起来更重要。大多数社交媒体内容就活在 10 到 15 秒这个区间里。YouTube Shorts 上限 60 秒,Instagram Reels 上限 90 秒。对于这类使用场景,15 秒带同步音频的内容,比 30 秒需要后期制作的无声视频更实用。
多模态输入:文本、图像、视频、蒙版、音频参考
V4 接受五种输入类型:文本提示词、参考图像、视频片段、用于局部重绘的二值蒙版,以及音频参考。你可以组合使用——上传特定人物的图像,提供碎石路上脚步声的音频样本,并输入提示词”黎明时分在森林中行走”。模型会利用这三种输入来引导生成。
我用一张特定建筑风格的参考图像和一段街道环境音频片段测试了多模态提示。生成的视频保留了图像中的建筑细节,同时叠加了音频参考中的环境声。不够完美——部分音频元素感觉略显通用——但这个功能确实奏效了。
三合一任务:生成、局部重绘、编辑
除了生成,V4 还通过通道拼接的方式处理局部重绘和编辑。 提供一段视频和一个标注需要修改区域的蒙版,模型将只重新生成那些区域,同时保留其余部分。这使得移除物体、更换背景或替换特定元素成为可能,无需重新生成整个片段。
V4 与之前的版本相比如何
V4 与 SkyReels V1/V2/V3 的演进对比
V1 仅支持文本生视频。V2 通过扩散强制机制增加了时长。V3 引入了多模态输入,但生成的视频依然没有原生音频。V4 是第一个将音频视为与视频同步生成的一等公民输出的版本。
谁应该关注 SkyReels V4?

内容创作者与影视制作人
任何为社交平台制作短视频内容的人都能立即受益。 工作流程的压缩——从提示词到完成的视听片段——消除了让 AI 视频工具感觉比节省工作量更多的那个瓶颈。
我看着一位做电影的朋友用 V4 为纪录片生成 B-roll 素材。提示词如”城市灯光在黄昏亮起的延时摄影”或”雨水打在玻璃窗上的特写镜头”,并配以合适的环境音。输出内容与真实素材并非无法区分,但作为背景镜头已经足够,而且每条都能在 60 秒内准备就绪,不需要外出拍摄或购买版权素材授权。
构建视频处理管道的开发者
如果你正在构建生成或处理视频的应用程序,V4 用于生成、局部重绘和编辑的统一接口能够简化整个技术栈。不再需要将独立的视频生成、音频合成和同步校正模型串联在一起,一次 API 调用就能处理整个流程。
模型架构有详细文档,而且 SkyworkAI 此前一直有开源历史版本的惯例,这意味着开发者访问权限将会扩大。V3 的权重已经可以在 Hugging Face 和 GitHub 上获取。
当前访问状态及后续计划
截至 2026 年 3 月 2 日,V4 处于有限预览阶段。官网提供带每日生成限额的免费层,但目前尚无 API 访问权限。参考 V3 的时间线——从论文发布到公开 API 大约用了两周——我预计更广泛的可用性将在三月中旬前到来。
技术论文指出,未来的工作包括突破 15 秒限制以及改进精细的音频控制。这些局限目前看来相当明显,尤其是时长上限。但对于 V4 所解决的那个具体问题——无需后期制作地生成短小的同步视听片段——它的表现比我测试过的任何其他工具都要好。
自从第一次测试之后,我就将 V4 保留在了我的工作流程中。并非用于一切——仍有些任务更适合用实拍素材或版权视频。但对于需要同步音频的快速 B-roll、环境场景或社交媒体片段,V4 消除了足够多的摩擦,让我如今第一个就会想到用它。
这种统一架构的感觉,与其说是功能上的渐进迭代,不如说更像是纠正了一个从一开始就应该这样运作的问题。



