GLM-4.7-Flash 与 GLM-4.7:哪个更适合你的项目?

你好,我的朋友们。我是Dora。如果这听起来很熟悉,你并不孤单。我一直都在那里:盯着一队微小、重复的提示,只需要快速、可靠的回复——而同时,一些固执的、多步骤推理任务坐在角落里,悄悄地要求更强大得多的能力。
所以我终于大声问出了这个问题:轻量级、闪电般快速的GLM-4.7-Flash到底在哪里表现出色,而你又需要在哪里引入更重、更深思熟虑的GLM-4.7?这是我得出的直率、无夸张的答案——基于实际运行、相关基准,以及让你的日常堆栈感到明显更轻的静默目标。如果你曾在”我应该在这里使用哪个模型?“这个问题前犹豫过,这就是为你准备的。
30秒答案
如果速度和低成本是你的主要杠杆,GLM-4.7-Flash可能会感觉正确。如果你的工作倾向于推理深度、工具使用或更高保真输出,GLM-4.7是更稳定的选择。其余的都是围绕延迟预算、上下文大小以及你的提示在压力下如何表现的细微差别。
如果满足以下条件,选择Flash…
Flash并不是”较弱”——它只是对自己擅长的事情非常诚实。
- 你正在分配许多小工作:摘要、标签、草稿、快速转换。
- 延迟比挤出最后10%的质量更重要。
- 你在进行实验、原型制作或构建应该感觉即时的UI交互。
- 偶尔的长推理步骤中的波动不会让你偏离轨道。
- 你想要一个更便宜的默认模型,只在需要时升级到GLM-4.7。
如果满足以下条件,选择GLM-4.7…
这是你的”别搞砸这个”模型。
- 你关心代码可靠性、多步推理或工具使用精确性。
- 提示很长、指令严格,或输出需要保持一致。
- 你正在运行评估器、测试或工作流,其中一个错误代价很高。
- 你需要在编码和长上下文任务中获得更强的结果。
- 你可以容忍更高的成本和更多的延迟以获得更好的结果。
架构差异
 我不追求参数计数来消遣,但架构解释了很多关于行为的事情:为什么一个模型感觉敏捷,而另一个感觉深思熟虑。
我不追求参数计数来消遣,但架构解释了很多关于行为的事情:为什么一个模型感觉敏捷,而另一个感觉深思熟虑。
参数计数与活跃专家
GLM-4.7看起来运行一个更大的骨干,并且(从公开说明来看)使用优先考虑推理的专家路由。Flash针对吞吐量进行了调整,路由更轻,每个标记的活跃专家更少,并且应用了激进的效率设置。在实践中,这往往表现为:
- Flash:较低的单标记计算、快速首标记时间,但在压力下可能会丢弃推理链。
- GLM-4.7:每标记更多计算、更稳定的推理路径、更好的工具调用选择。
如果你浏览提供商图表,你会看到混合专家(MoE)和激活稀疏性的提示。确切的数字在版本间漂移,所以我将它们视为方向性的,而不是绝对的。大思路是:Flash每标记的”思考”更少,所以它更快地移动;GLM-4.7思考更长,更少在边界情况上绊倒。
上下文窗口与输出限制
两个实际问题比标题上下文数字更重要:
- 在长提示中,质量保持到多远?
- 当输出变长时,模型是否失去了思路?
Flash通常宣传一个健康的上下文窗口,但对于非常长的提示或密集的指令,质量往往会更快地减弱。GLM-4.7在长上下文中保持更深的连贯性,并在长输出中对结构的遵守更加顺从。如果你正在填充知识库,GLM-4.7是更安全的默认选择。如果你正在分块输入或使用检索来保持提示简洁,Flash通常足够好——并且快得多。
基准比较
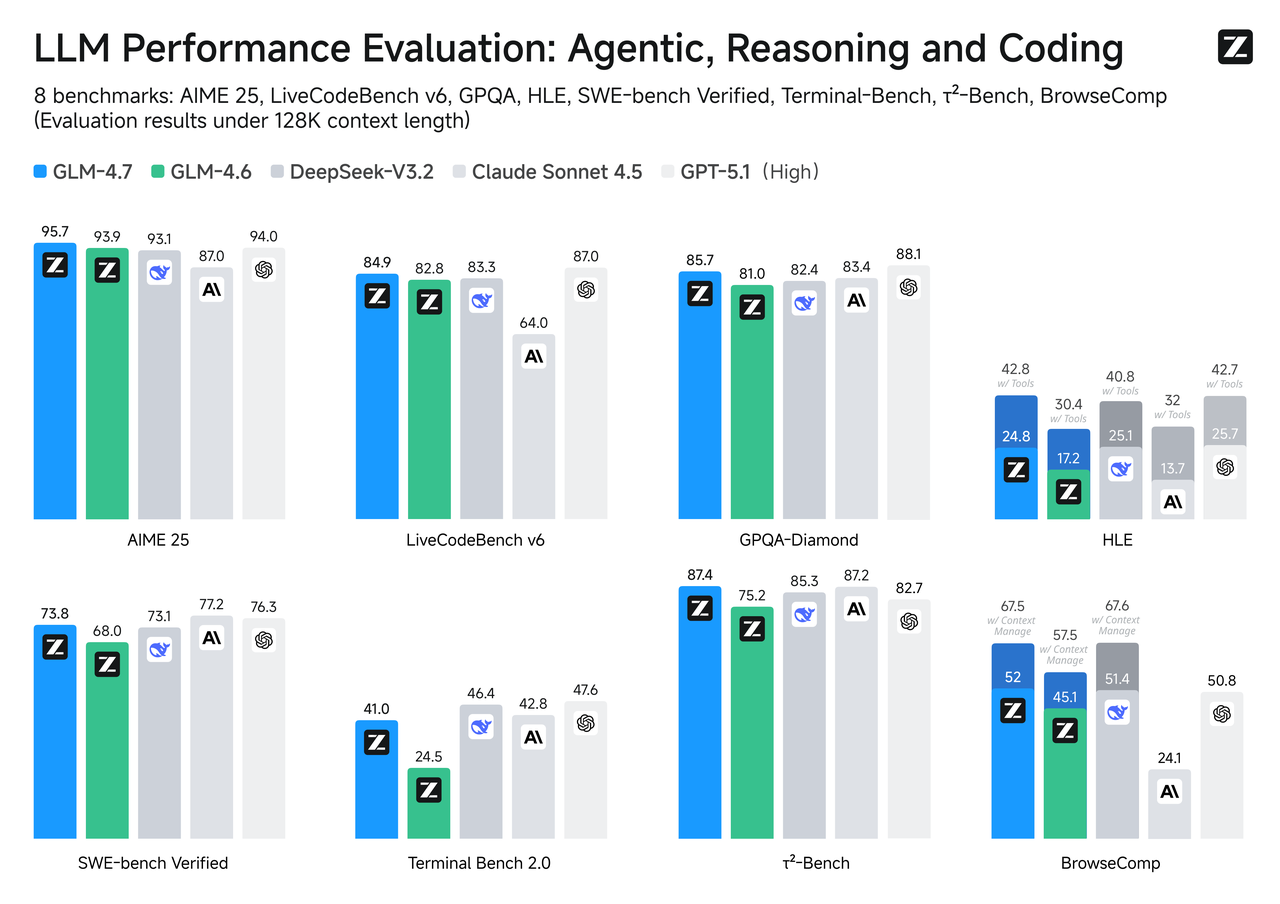 基准并不是全部,但它们是一个有用的指南针,特别是当你的用例与任务一致时。
基准并不是全部,但它们是一个有用的指南针,特别是当你的用例与任务一致时。
SWE-bench验证
对于必须实际编译和通过测试的代码更改,GLM-4.7往往排名高于其Flash兄弟。这与你从为推理深度和工具使用调整的模型中期望的一致。Flash可以很好地起草修复和解释代码,但当补丁需要跨文件的多个协调编辑时,GLM-4.7更可能遵循链而不丢弃步骤。
如果你的管道包括自动PR或修复循环,值得用小样本先进行健全性检查。差异在多跳问题中比单文件调整中更明显。
LiveCodeBench / τ²-Bench
在实时或时间轮换编码基准上,GLM-4.7通常与给定其更重推理预算的顶级追踪更接近。Flash,针对速度优化,坐在更低的等级但响应很快。如果你的产品依赖于代码合成质量而不是交互速度,GLM-4.7是保守的选择。如果代码是咨询性的(你无论如何都会审查它)并且响应性很重要,Flash可以是正确的权衡。
速度与延迟
这是分裂感觉最清楚的地方。Flash通常明显更快地返回第一个标记,而总的最后一个标记时间对于短中型输出保持较低。如果你运行许多小调用或向UI流式传输,这会累积。
GLM-4.7启动较慢,运行更重,但在长生成和复杂的工具调用序列上更稳定。你会看到更少的停滞、更少的奇怪迂回,以及对函数模式的更好遵守。
如果你正在构建一个系统:
- 对高流量UX时刻使用Flash:自动完成、快速摘要、内联帮助。
- 对慢车道使用GLM-4.7:评估器、代码操作、政策检查、最后通过。
一个简单的路由规则往往能为自己付出代价:从Flash开始,当信心下降或阈值被超越时升级到GLM-4.7。让规则决定,这样你就不必。
价格分解
价格因地区和提供商而异,所以我将数字视为移动目标,保持结构稳定。
Flash免费层对比GLM-4.7按标记付费
-
Flash:许多平台为Flash类模型提供免费或低成本层,与旗舰模型相比具有慷慨的速率限制。非常适合原型制作、后台任务和UI打磨。
-
GLM-4.7:通常按更高费率按标记计费。在严肃任务上更好的成本价值,但如果你将其作为默认值,很容易超支。
 实际建议:
实际建议: -
默认限制输出标记。只在需要的路由中提高上限。
-
使用检索保持提示简短:不要将整个语料库倒入窗口中。
-
缓存确定性子结果(正则表达式映射、模式片段、少样本块),这样你就不必再为它们付费。
-
记录每条路由的标记成本。你实际阅读的报告是坐在你的每周工作流中的报告,而不是有最多图表的报告。
如有疑问,从便宜开始,测量,然后升级。升级胜过乐观。
按用例选择
以下是我在目标是减少麻烦时如何分配它们:
- 高流失内容操作(片段、主题线、元数据):Flash。赢得之处是低成本的吞吐量和一致性。
- 支持宏和快速分流:首先Flash,如果检测标记复杂性或政策风险,则升级到GLM-4.7。
- 研究笔记、综合、结构化摘要:Flash用于浏览;GLM-4.7用于必须忠于来源且精良的通过。
- 代码协助:Flash用于解释和”这是做什么的?“;GLM-4.7用于多文件编辑、迁移和测试意识的更改。
- 数据清理和转换:Flash对于简单映射是可以的;GLM-4.7对于严格的模式、验证和多步骤连接。
- 代理和工具使用:GLM-4.7。你会获得更可靠的函数参数和更少的重试。
- 长上下文阅读或文档接地QA:如果你正在推动窗口,则为GLM-4.7;如果你保持块精益,则为Flash。
我保持接近的一些实地笔记:
- 短提示隐藏差异。当指令密集或输出必须遵循结构时,间隙显示。
- 路由有帮助。即使是一个简单的规则,“Flash除非提示> N个标记,然后GLM-4.7”,也能节省成本而不闹剧。
- 对于重复任务,护栏比模型选择更重要。验证、重试和小检查器防止下游混乱。
- 不要妖魔化速度。在一秒以下感觉”即时”对大多数用户。超过这一点,稳定行为胜过削减100毫秒。
为什么这很重要:当工具减少心理负荷时,它们就会老得好。Flash保持小东西轻。GLM-4.7携带重箱子而不掉它们。大多数堆栈都需要两者。
如果你不确定,从Flash作为你的默认值开始,并为GLM-4.7创建清晰的车道。让路由,而不是心情,决定。你的里程可能会有所不同,这很好。
我仍然注意到,在安静的日子里,这个分裂如何减少决策疲劳。没有什么花哨的——只是更少的麻烦。
我实际上如何在实践中运行这个分裂
 当我需要将快速工作路由到Flash并将更重的工作升级到GLM-4.7而不用照看脚本时,我使用WaveSpeed——我们自己的平台。
当我需要将快速工作路由到Flash并将更重的工作升级到GLM-4.7而不用照看脚本时,我使用WaveSpeed——我们自己的平台。
我们构建它来干净地处理模型切换、并发和批量调用,所以”Flash第一,在需要时升级”的模式保持简单而不是脆弱。
如果你运行大量小调用并且不想让路由逻辑成为另一件要维护的事情,试试Wavespeed!
常见问题:GLM-4.7-Flash 对比 GLM-4.7
1. GLM-4.7-Flash和GLM-4.7之间的主要区别是什么?
GLM-4.7-Flash是GLM-4.7的轻量级、优化变体。它通过减少活跃专家的数量、简化路由和应用效率调整来实现更快的推理和更低的成本。GLM-4.7保留了更大的骨干和更强的推理能力,在复杂多步推理、长上下文连贯性和精确工具调用中表现出色。
简而言之: Flash用一些智力交换速度;GLM-4.7优先考虑深度和可靠性。
2. 哪个模型更快,在哪些场景中速度差异最明显?
GLM-4.7-Flash具有显著较低的首标记时间(TTFT)和单标记延迟。它在实时UI交互、内容摘要、元数据生成和快速原型制作等高吞吐量、低延迟用例中表现出色。
GLM-4.7具有更高的启动开销和更重的计算,但在长输出或复杂的工具调用序列上仍然更稳定。在实践中,Flash对于短到中型输出(在500个标记以下)明显更快。
3. 哪个模型在智能和推理方面更强?
GLM-4.7在多步推理、代码可靠性、工具使用和长上下文任务中优于Flash。例子:
- SWE-bench验证: GLM-4.7在多文件代码编辑和协调补丁中领先。
- LiveCodeBench / τ²-Bench: GLM-4.7提供更高质量的代码,特别是对于深推理场景。
Flash适合单文件编辑或容忍人工审查的辅助任务,但在长推理链或密集提示上恶化更快。
4. 上下文长度和输出限制如何比较?
两个模型共享相似的上下文窗口,但GLM-4.7在非常长的上下文(>32k标记)或密集提示上保持更好的连贯性和指令遵循。Flash在极端提示长度或密度下更快恶化——配对它与分块或RAG以获得最佳结果。
5. 我应该如何根据价格和成本控制进行选择?
GLM-4.7-Flash通常提供更高的免费配额和更低(甚至零)的单标记价格,使其理想用于原型制作、后台任务和高容量低风险调用。GLM-4.7具有更高的单标记成本,但对关键任务具有更好的价值。
建议: 默认为Flash,对于复杂工作升级到GLM-4.7,并始终设置标记上限和缓存以防止超支。





