Gemini 3.1 Flash-Lite:功能、使用场景及与Flash的对比
Gemini 3.1 Flash-Lite 是 Google 成本最低的推理模型。了解其功能、实际使用场景,以及与 Gemini Flash 的直接对比。

当 Google 在 3 月 3 日发布 Gemini 3.1 Flash-Lite 时,我注意到一件奇怪的事。通常,他们会先推出更强大的 Flash 型号——或者直接跳过 Lite 档位。这次,他们直接上了预算版。这个转变让我开始关注。
我是 Dora。过去一天我一直在测试它,让我措手不及的不只是速度,而是这种定价结构突然让某些工作流程变得……以前无法企及的亲民。

什么是 Gemini 3.1 Flash-Lite
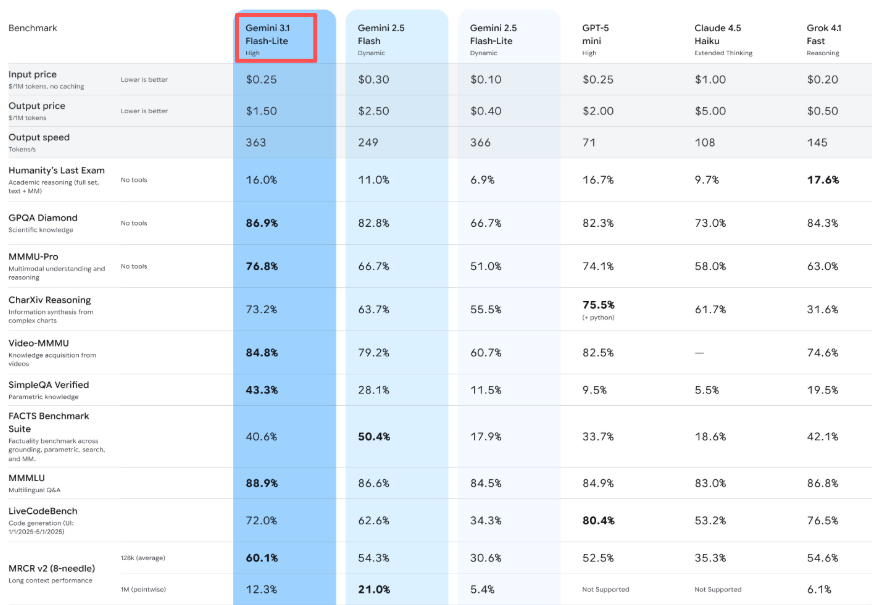
Gemini 3.1 Flash-Lite 在 Google 最新模型阵容中位于底端,但”底端”已经不是以前的意思了。根据 Google 官方文档,它是 Google 最具成本效益的 Gemini 模型,针对低延迟场景和高并发流量进行了优化。它的目标是在关键能力方面匹敌 Gemini 2.5 Flash,同时速度更快、价格更低。
它在 Gemini 3.1 产品线中的位置
Gemini 3 家族现在有三个清晰的层级。顶端是 Gemini 3.1 Pro——适用于复杂推理任务的重量级选手。中间是 Gemini 3 Flash,将 Pro 级智能与 Flash 级速度相结合。而 Flash-Lite 则占据了高并发、成本敏感的位置。
有趣的地方在于,Flash-Lite 并不是 Flash 的削减版。它实际上基于 Gemini 3 Pro 的架构,然后专门针对吞吐量和延迟进行了优化。这种架构选择体现在基准测试中——它不仅更快,而且比同价位下你预期的更聪明。
Pro / Flash / Flash-Lite 分级逻辑如何运作
分层方式与功能无关——它关乎算力分配。Pro 在复杂问题上投入更多 token 进行思考。Flash 在推理与速度之间取得平衡。Flash-Lite 默认将内部推理降到最低,但你可以调整。
最后这点是全新的。Google 添加了他们所称的”思考级别”——最小、低、中或高。对于简单的翻译任务,调到最小级别可以即时得到结果。对于需要更高准确性的任务,调高级别,接受略高的延迟和成本。
我用一批客户支持工单测试了这一点。在最小思考模式下,响应在两秒内返回。在中等模式下,耗时五秒,但捕捉到了快速处理时遗漏的细节。这种控制感觉很实用。
Gemini 3.1 Flash-Lite 主要特性
超低推理成本
定价为每百万输入 token $0.25,每百万输出 token $1.50。作为对比:Gemini 3.1 Pro 在复杂工作负载下,每百万输入 token 起步价为 $2.00,每百万输出 token $18。Flash-Lite 处理基础任务的成本大约是 Pro 的八分之一。
但让我惊讶的是——它比 Gemini 2.5 Flash($0.30/$2.50)还便宜,尽管能力更强。这很不寻常,通常升级意味着要多付钱。
高吞吐量与低延迟
Google 声称 Flash-Lite 的输出速度为每秒 363 个 token,在我的测试中,这个数据感觉准确。更重要的是,首 token 时间——你停止等待、开始看到输出的那一刻——比 Gemini 2.5 Flash 快 2.5 倍,根据他们的内部基准测试。
在构建一个简单的内容审核管道时,我对此感受最深。三秒等待和一秒等待的差距听起来不大,但当你处理数百个条目时,这种延迟会累积放大。使用 Flash-Lite,管道感觉流畅而不拖沓。
多模态输入支持
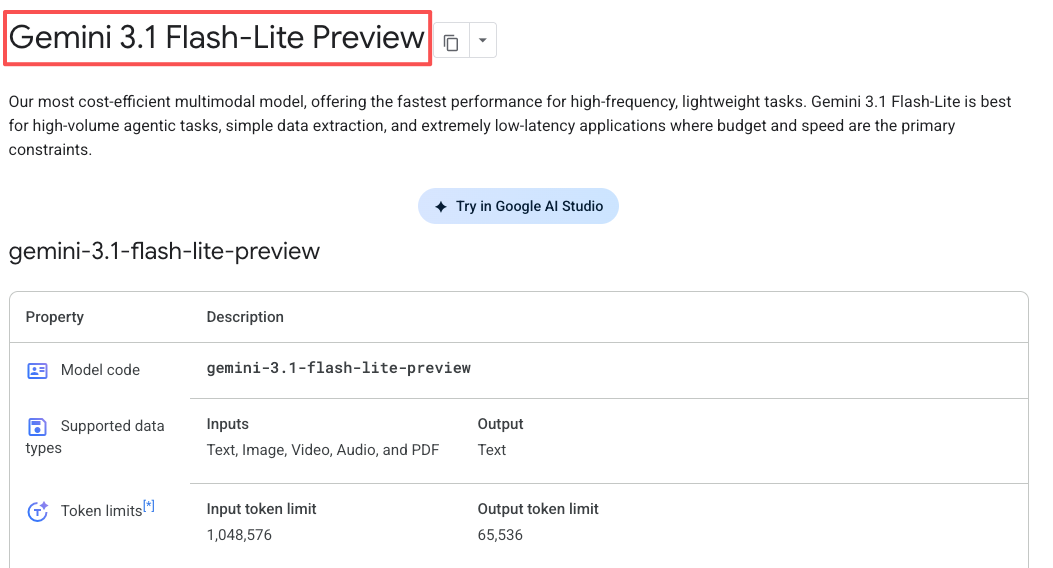
Flash-Lite 支持文本、图像、音频和视频。上下文窗口最高达 100 万 token,可生成最多 64,000 个 token 的文本输出。
我用一批电商原型的产品图片和描述进行了测试。它打标签既一致又快速——早期用户 Whering 报告称,在复杂时尚品类的商品打标任务中达到了 100% 的一致性。当你构建不能出现漂移的系统时,这种可靠性至关重要。
长上下文窗口
100 万 token 的上下文窗口意味着你可以直接输入完整文档、长对话记录或大型数据集,无需先将其切分成小块。我不常用满整个窗口,但当我需要时——比如分析多页 PDF——这决定了工作流程是顺畅还是令人沮丧。
Gemini 3.1 Flash-Lite vs Flash:直接对比
何时使用 Flash-Lite
当你需要运行数千乃至数百万个类似任务时,使用 Flash-Lite。翻译管道、内容审核队列、规模化情感分析、基础数据提取——任何任务定义明确、每 token 成本比深度推理更重要的场景。
我还发现它很适合用作路由器。你可以用 Flash-Lite 将传入请求分类为”简单”或”复杂”,然后将复杂请求路由到 Flash 或 Pro。这样可以在不牺牲关键质量的前提下节省费用。
何时应该选择 Flash
如果任务需要多步推理、创造性解决问题,或处理模糊指令,Flash 是更好的选择。它价格是 Flash-Lite 的两倍,但也更聪明——尤其在编码任务上,它在某些基准测试中与 Pro 持平甚至超越 Pro。
我用两者测试了一个根据自然语言提示生成 UI 组件的任务。Flash-Lite 能处理直接的请求(“创建一个登录表单”),但在模糊请求上表现挣扎(“设计一些现代简洁的东西”)。Flash 两者都能处理。
Gemini 3.1 Flash-Lite 应用场景
AI 智能体路由与任务分类
我见过的最清晰的用例之一是将 Flash-Lite 用作流量控制器。当用户提交请求时,Flash-Lite 读取请求,判断复杂程度,然后路由到合适的模型——中等任务交给 Flash,困难任务交给 Pro。
这种模式已经在生产工具中使用。开源的 Gemini CLI 就是这样使用 Flash-Lite 的,之所以有效,是因为该模型足够快且足够便宜,可以添加路由步骤而不会明显增加延迟或成本。
高并发聊天与客服自动化
客户支持是成本节省真正体现的地方。如果你每天处理数万张支持工单,每百万输入 token $0.25 与 $2.00 的差距会迅速放大。
Flash-Lite 可以处理直接的问题、提取意图,并将需要人工处理的工单路由出去。它不会解决复杂的技术问题,但也不需要。它只需要可靠且快速。
内容审核与标签
我快速构建了一个测试管道来审核用户生成内容——标记垃圾信息、不当语言和偏离主题的帖子。Flash-Lite 在一分钟内处理了约 500 条内容,准确率稳定一致。
关键在于一致性。有些模型会随时间漂移,或对相似输入给出不同答案。Flash-Lite 在重复运行中保持了可预测性,这在构建需要每次行为一致的系统时非常重要。
文档预处理管道
Flash-Lite 在结构化数据提取方面表现出色。给定一批发票或收据,它可以提取关键字段——日期、金额、供应商名称——并以 JSON 格式输出。
我用一批 PDF 发票测试了这一点,它干净利落地处理了大部分。处理失败的是文字质量差的低分辨率扫描件,但这是输入的限制,而非模型的问题。
Flash-Lite 对 AI 基础设施设计意味着什么

分层模型架构模式
Flash-Lite 的发布完善了一种越来越像行业标准的模式:三层模型架构。一个用于解决难题的重量级选手、一个日常使用的均衡选项,以及一个用于高并发重复工作的轻量级模型。
这并不新鲜——OpenAI 有 GPT-5 / GPT-5 mini,Anthropic 有 Claude Opus / Sonnet / Haiku——但 Google 的实现很有意思,因为价格差距更大。Flash-Lite 与 Pro 相比真的很便宜,这使得某些以前在经济上不可行的工作流程成为可能。
廉价路由器 + 强推理引擎——为什么这很重要
我反复看到的模式是:用廉价模型来判断你面对的是什么类型的任务,然后只在必要时路由到更昂贵的模型。这不仅仅是为了省钱,它还改善了简单任务的延迟,因为你不需要等待重量级模型启动。
我用一批 100 个混合任务测试了这一点——一半简单,一半复杂。使用 Flash-Lite 作为路由器,简单任务在几秒内完成,复杂任务被路由到 Flash。总成本比将所有任务都通过 Flash 处理低约 40%,而复杂任务的质量没有任何损失。
这种架构只有在路由器足够快且足够便宜、不会成为瓶颈的前提下才有效。Flash-Lite 做到了。
当前可用性与 API 状态
Gemini 3.1 Flash-Lite 现在可通过 Google AI Studio 的 Gemini API 和 Vertex AI 以预览版获取。它不在面向消费者的 Gemini 应用中——这是面向开发者的。
预览版模型在正式稳定之前可能会发生变化,且速率限制更严格。实际上,在正常测试中我没有触及这些限制,但如果你计划在严重规模下进行生产部署,这是需要关注的点。
该模型也在持续更新。Google 的发布说明显示,指令跟随、音频输入质量和推理能力正在持续改进。现在还处于早期阶段——未来几个月可能会变得更好。
一个挥之不去的想法
我反复思考的不是速度或成本,而是 Flash-Lite 让某些工作流程从实验变成了日常工具这个事实。当成本低到一定程度,你就不再问”我应该为这个用 AI 吗?“,而是开始问”我怎样构建这个才能让它规模化?”
这种转变——从新奇到基础设施——正是工具开始长久存在的地方。



