Why Is HappyHorse-1.0 Suddenly #1 on Video Leaderboard?
HappyHorse-1.0 hit #1 on Artificial Analysis with no public team. Here's why Elo rewards video quality over brand — and what that means for builders.

Hey, guys. Dora here. I counted the number of times someone in my feed this week asked some version of “what the hell is HappyHorse?” Six. Six separate threads. And each one had a slightly different rumor attached — it’s WAN 2.7, it’s a ByteDance stealth drop, it’s something out of Alibaba. Nobody knows for sure. What everyone does agree on: it appeared on the Artificial Analysis video leaderboard around April 7–8, 2026, and immediately took the #1 spot in Text-to-Video and Image-to-Video.
That’s the fact. Everything after that — who built it, when the weights drop, whether it stays at #1 — is still unresolved.
This piece is about what the leaderboard is actually measuring, why an unknown model can legitimately land at the top of it, and what you should and shouldn’t do with that information as a builder.
How the Artificial Analysis Video Arena Works
Before you trust a ranking, you need to understand what the ranking measures. The Artificial Analysis Video Arena isn’t a benchmark where the model developer submits their own scores — it’s a blind user vote system.
What users see (and don’t see)
You go to the arena, you’re shown two videos generated from the same text prompt or input image, and you pick which one you prefer. You don’t know which model made which video. No labels. No context. Just two clips.
This is how Artificial Analysis describes it directly: “Users compare two videos generated from the same text prompt without knowing which model created each video.” That’s the part that matters. There’s no self-reporting, no developer-supplied benchmarks, no marketing page influencing the result.
Elo: signal-reliable, but not infallible
The ranking uses an Elo system — the same approach borrowed from competitive chess. Every time two models go head-to-head in a vote, the winner gains Elo points and the loser loses some. A model with a high Elo has consistently won more matchups against other models than it’s lost.
Higher Elo scores indicate a model is preferred more often. That’s a real signal. It’s based on thousands of real human choices, not synthetic tests, not cherry-picked examples, not a model card.
Vote count and sample size: the part people skip
Here’s the thing about Elo with new entrants. Established models like Seedance 2.0 have thousands of votes behind their scores — Seedance 2.0 has over 7,500 vote samples in the T2V category. HappyHorse’s sample count isn’t publicly broken out yet. More votes = more stable score. A newer model with fewer matchups can swing more dramatically with each new vote.

These numbers will shift as more votes come in. The direction of that shift is unknown. Keep that in mind before building pipeline decisions around a number that’s two days old.
What HappyHorse-1.0 Is Actually Scoring
The current numbers, pulled from the live leaderboard as of early April 2026:
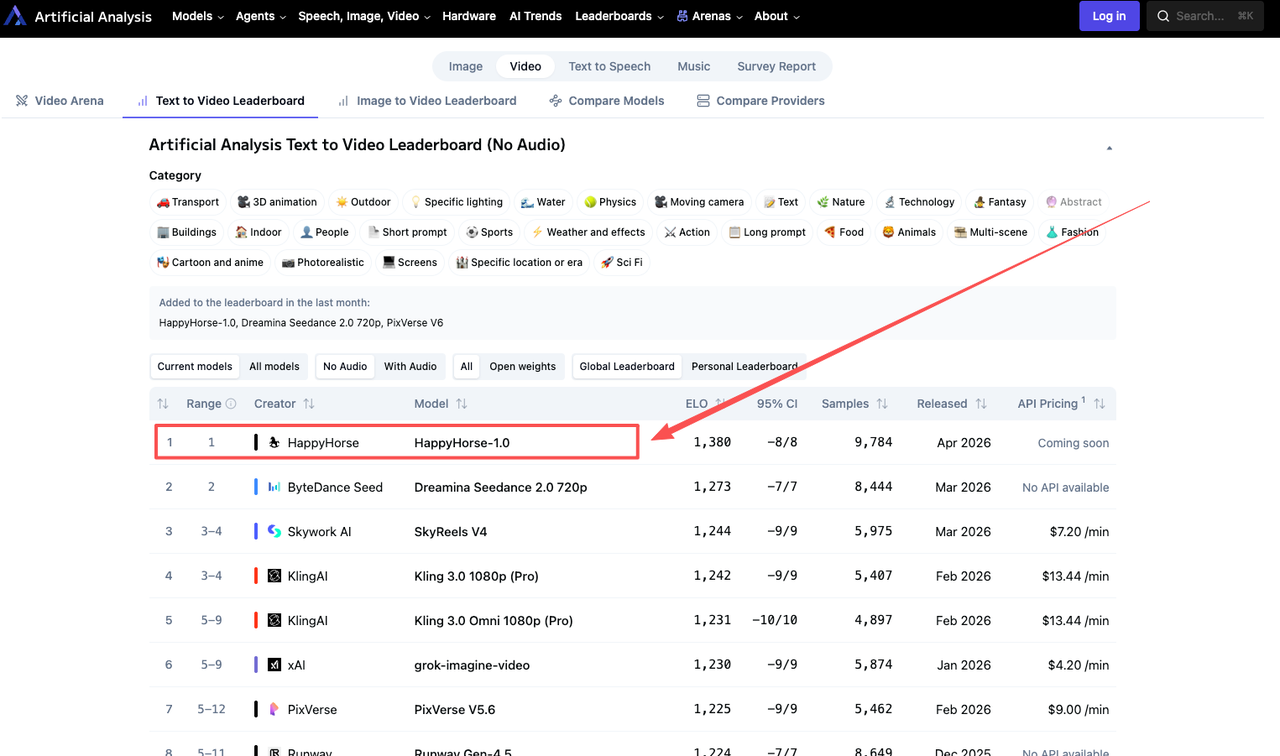
T2V (no audio): HappyHorse-1.0 leads with an Elo score of 1357, ahead of Dreamina Seedance 2.0 at 1273, SkyReels V4 at 1244, and Kling 3.0 Pro at 1243.
I2V (no audio): HappyHorse-1.0 leads with an Elo of 1402, with Seedance 2.0 at 1355 and Grok Imagine Video at 1331.
That 84-point gap in I2V without audio is not small. A 60-point Elo gap means one model wins roughly 58–59% of blind matchups — meaningful. An 80+ point gap is stronger still.
The audio story inverts
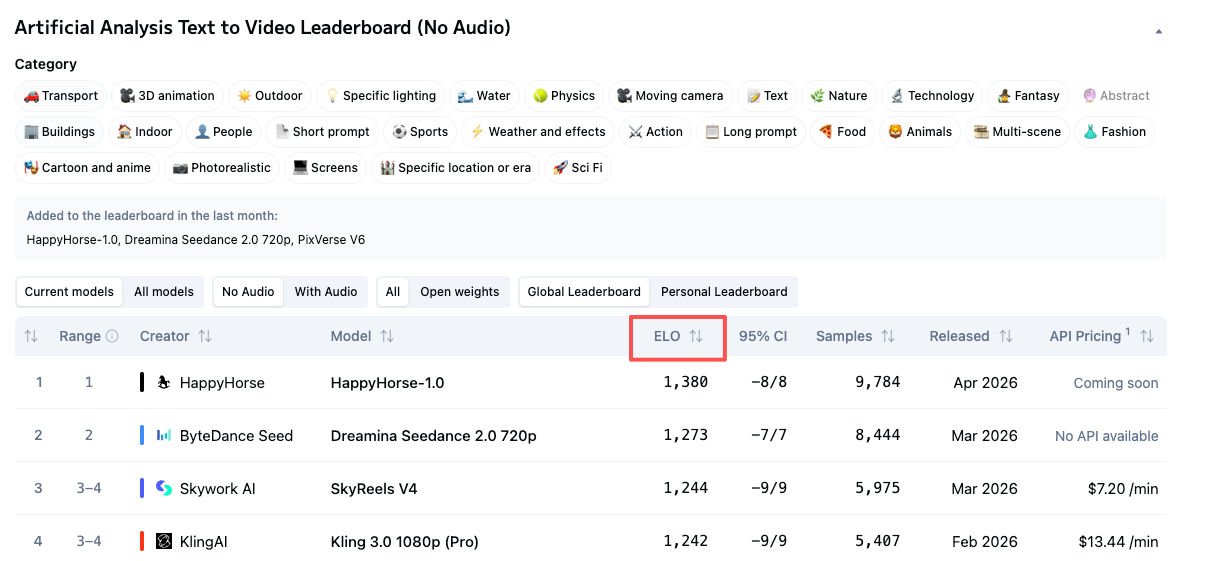
For Image-to-Video with audio, HappyHorse-1.0 currently leads with an Elo score of 1160, with Dreamina Seedance 2.0 at 1158. A 2-point gap is statistical noise. And in T2V with audio, Seedance 2.0 leads at 1220 with HappyHorse at 1215.
So the picture is more nuanced than “HappyHorse is #1 everywhere.” It’s #1 by a significant margin when audio is excluded. When audio quality enters the equation, it’s essentially tied with Seedance 2.0.
What the architecture claims say (and what they don’t prove)
Several sites describing HappyHorse say it runs on a single-stream Transformer architecture with approximately 15 billion parameters, with claimed generation speeds around 38 seconds for a 1080p clip on a single H100. As of April 8, 2026, the GitHub and Hugging Face links on these HappyHorse sites point to “coming soon” pages or return 404 errors. The weights aren’t publicly downloadable.
These architectural claims are plausible — but they’re unverified. No independent technical audit has confirmed the parameter count, architecture type, or inference speeds. Treat them as claimed, not confirmed.
Why Unknown Models Can Win on Elo
This is the thing that confuses people who assume leaderboards reward brand recognition.
Elo doesn’t care who built the model. It doesn’t know if you’re Google or a three-person lab. Artificial Analysis’s Video Arena uses the Elo rating system and relies entirely on real-user blind votes. It ignores parameters, papers, or hype — it only cares about one question: “Which video did you prefer after watching both?”
That’s actually a feature. It’s one of the few evaluation systems where a well-funded brand can’t buy a better result by publishing a favorable paper.
This pattern has happened before
Anonymous pre-launch drops have become a pattern in the Chinese AI ecosystem. The Pony Alpha situation in February 2026 is the clearest precedent — a mystery model appeared on OpenRouter, triggered a guessing game, and turned out to be Z.ai’s GLM-5 doing a stealth stress test. HappyHorse fits this template: unknown name, no team attribution at launch, landing page with “coming soon” GitHub links, strong outputs.
Whether it’s a major lab doing a quiet capability check or a genuinely new team — that’s still unresolved. But the Elo score itself is real regardless.
The limitation Elo can’t hide
Elo measures one thing: which video real users preferred in a blind comparison. It does not measure how the model performs in batch runs. It doesn’t measure API uptime, latency under load, or whether the output quality holds when you’re generating at scale versus cherry-picking arena examples.
A model can have excellent blind-test results and be completely unusable in production. These are separate questions.
What “Leaderboard #1” Doesn’t Mean for Builders
This is where I’d slow down if you’re about to make a tool decision based on HappyHorse’s current ranking.
No API, no production access
Three things would move HappyHorse from “leaderboard entry” to “real option”: a GitHub repository with actual weights and inference code, a HuggingFace model card with verifiable details and a license, or an API endpoint with documented pricing. None exist as of this writing.
If you can’t call it, you can’t use it. The leaderboard position is information about output quality, not availability.
Audio performance changes the calculus
If your workflow requires audio — voiceover, ambient sound, lip sync — HappyHorse’s lead essentially disappears. The gap between it and Seedance 2.0 in the with-audio categories is 5 points in T2V and 2 points in I2V. Those are ties within normal Elo variance.
For audio-required use cases, the practical field right now looks like a Seedance/HappyHorse tie at the top, with SkyReels V4 a meaningful step below.
Team accountability: unknown
Artificial Analysis described HappyHorse as “pseudonymous” when it added the model to the arena. One set of sites connected to the model claims it was built by the Future Life Lab team at Taotian Group (Alibaba), led by Zhang Di, former head of Kling AI. Another analysis connected it to a Sand.ai open-source project called daVinci-MagiHuman, which shares nearly identical specs. Neither has been officially confirmed.
For a production tool, team accountability matters for bug fixes, model updates, and long-term support. With pseudonymous models, you don’t have that clarity.
How to Read the Video Leaderboard as a Builder
Concrete framework, not abstractions.
Use Elo as a quality signal, not a procurement decision. If a model is consistently winning blind comparisons against well-funded competitors, that tells you something real about what it produces. That’s worth noting. It doesn’t tell you anything about API terms, pricing, latency, or whether the team responds to bug reports.
The practical leaderboard starts at #3. The two highest-quality models by Elo — HappyHorse and Seedance 2.0 — are both inaccessible via public API. The next tier — SkyReels V4, Kling 3.0, PixVerse V6 — is where actual integration decisions get made right now.
When to act early on a new leaderboard entrant. If a model is at the top with a meaningful Elo gap, has a verified GitHub release, and documentation exists — worth testing immediately. If it’s at the top but GitHub says “coming soon” — set a reminder to check in two weeks. Don’t restructure a pipeline around vapor.
Check the live leaderboard directly, not articles. Including this one. Elo scores move daily. The numbers I’ve referenced here reflect early April 2026 and will have shifted by the time you read this.
FAQ
How long has HappyHorse-1.0 been on the Artificial Analysis leaderboard?
Artificial Analysis announced it on April 7, 2026, describing it as a newly added pseudonymous model. As of this writing, it’s been live for roughly 48 hours and vote counts are still accumulating.
Can a model stay at #1 on Elo indefinitely?
Not usually. As newer models enter the arena and collect more votes, rankings shift. A model that dominates on day two with a small sample can stabilize lower as the vote pool deepens. The score is always live — it reflects current data, not a permanent judgment.
Does Artificial Analysis verify who submits models to the arena?
Artificial Analysis has not published a formal verification policy for model submissions. They described HappyHorse-1.0 as “pseudonymous” when announcing it, which suggests the identity of the team is known to them but not disclosed publicly. Whether they do any technical audit of submitted models isn’t documented.
Should I choose a model based on Elo score alone?
No. Elo tells you about visual preference in blind comparisons. It says nothing about API availability, cost per generation, latency, uptime, content policy, or whether the model will exist in three months. It’s one signal among several.
What other metrics matter alongside leaderboard rankings?
API access and documentation; pricing per generation or per minute; latency and cold-start behavior at your usage frequency; sample count behind the Elo score (more votes = more stable); and whether the team has a track record of maintaining and updating the model. The WaveSpeed model comparison page tracks several of these dimensions across accessible models if you want a starting point.
That’s where things stand. A model with an unknown team and no public weights just topped the most credible video benchmark we have, by a margin that’s hard to dismiss. Whether it becomes a real production option depends entirely on what gets released in the next few weeks.
Worth watching. Not worth acting on yet.
More to come.
Previous posts:
Related Articles

HappyHorse vs Kling 3.0 vs SkyReels V4: Builder's Guide

HappyHorse-1.0 vs Seedance 2.0: Which Wins Right Now?

Is HappyHorse-1.0 Open Source? What We Can Verify

What Is HappyHorse-1.0? The Mystery #1 AI Video Model

Where to Try HappyHorse-1.0: Access and Availability
