Gemini 3.1 Flash-Lite:機能、ユースケース、そしてFlashとの比較
Gemini 3.1 Flash-LiteはGoogleの最低コスト推論モデルです。機能、実際のユースケース、そしてGemini Flashとの直接比較を解説します。

*Googleが3月3日にGemini 3.1 Flash-Liteをリリースしたとき、私は少し奇妙なことに気づいた。通常、彼らはより高性能なFlashモデルを先にリリースするか、Liteティアを完全にスキップする。今回は、最初からバジェット向けオプションに踏み込んできた。そのシフトが私の注意を引いた。
WaveSpeedAI で利用可能 — トークン単位の透明な料金、OpenAI 互換エンドポイント。 Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Playground を開く →
私はDoraと申します。この一日間テストを続けてきたのですが、私を驚かせたのはスピードだけではありませんでした。価格体系のおかげで、これまでは難しかったワークフローが急に手の届く価格で実現できると感じたことです。

Gemini 3.1 Flash-Liteとは
Gemini 3.1 Flash-LiteはGoogleの最新モデルラインナップの最下位に位置しますが、「最下位」という言葉がかつて持っていた意味とは異なります。Googleの公式ドキュメントによれば、これは最もコスト効率の高いGeminiモデルであり、低レイテンシのユースケースと高ボリュームのトラフィック向けに最適化されています。主要な能力領域でGemini 2.5 Flashのパフォーマンスに匹敵しつつ、大幅に高速かつ低価格を目指しています。
Gemini 3.1ラインナップにおける位置づけ
Gemini 3ファミリーには現在、明確な3つのティアがあります。最上位にはGemini 3.1 Proがあり、複雑な推論タスク向けのヘビー級モデルです。中間にはGemini 3 Flashがあり、ProクラスのインテリジェンスとFlashレベルのスピードを兼ね備えています。そして今回、Flash-Liteが高ボリューム・コスト重視のポジションを占めることになりました。
興味深いのは、Flash-LiteはFlashの機能を削ぎ落としたバージョンではないという点です。実際にはGemini 3 Proのアーキテクチャをベースに、スループットとレイテンシに特化して最適化されています。そのアーキテクチャの選択はベンチマークにも表れています。単に速いだけでなく、価格帯の割に賢いのです。
Pro / Flash / Flash-Liteのティア構造の仕組み
ティア構造は機能の差ではなく、コンピューティングリソースの配分の差です。Proは複雑な問題をじっくり考えるためにより多くのトークンを使います。Flashは推論とスピードのバランスをとります。Flash-Liteはデフォルトでは内部推論を最小化しますが、調整することもできます。
この最後の点が新しいところです。Googleは「思考レベル」と呼ぶ機能を追加しました。minimal、low、medium、highの4段階です。シンプルな翻訳タスクであればminimalに設定して即座に結果を得られます。より高い精度が必要なタスクには設定を上げ、レイテンシとコストが少し高くなることを受け入れます。
カスタマーサポートのチケットのバッチでこれを試してみました。minimal思考では、レスポンスが2秒以内に返ってきました。mediumでは5秒かかりましたが、素早いパスでは見逃していたニュアンスを捉えていました。このコントロール機能は実用的に感じました。
Gemini 3.1 Flash-Liteの主な機能
超低コストの推論
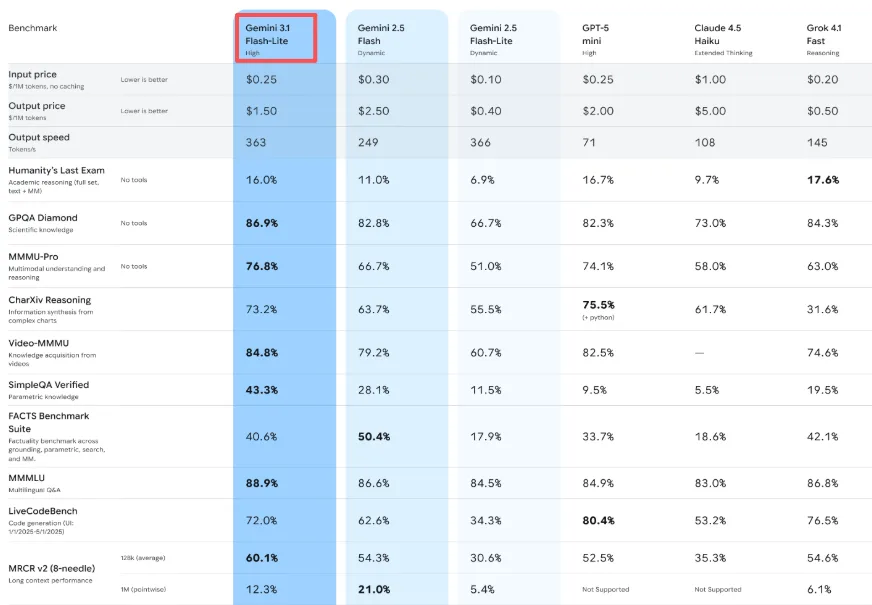
価格は入力100万トークンあたり0.25ドル、出力100万トークンあたり1.50ドルです。比較すると、Gemini 3.1 Proは要求の高いワークロードで入力100万トークンあたり2.00ドル、出力100万トークンあたり18ドルから始まります。Flash-Liteは基本タスクでProの約8分の1のコストです。
しかし私が驚いたのは、より高性能であるにもかかわらず、Gemini 2.5 Flash(0.30ドル/2.50ドル)よりも安いという点です。これは珍しいことです。通常、アップグレードには追加コストがかかります。
高スループットと低レイテンシ
GoogleはFlash-Liteが毎秒363トークンの出力を生成すると主張しており、私のテストではその数字は正確に感じられました。さらに重要なのは、最初のトークンが返ってくるまでの時間 — 待機が終わり出力が始まる瞬間 — が、Googleの内部ベンチマークによればGemini 2.5 Flashより2.5倍速いということです。
これを最も実感したのは、シンプルなコンテンツモデレーションパイプラインを構築したときです。3秒待ちと1秒待ちの差はたいしたことないように聞こえますが、数百件のアイテムを処理していると、その遅延は積み重なります。Flash-Liteを使うと、パイプラインがもたついた感じではなく、レスポンシブに感じられました。
マルチモーダル入力のサポート
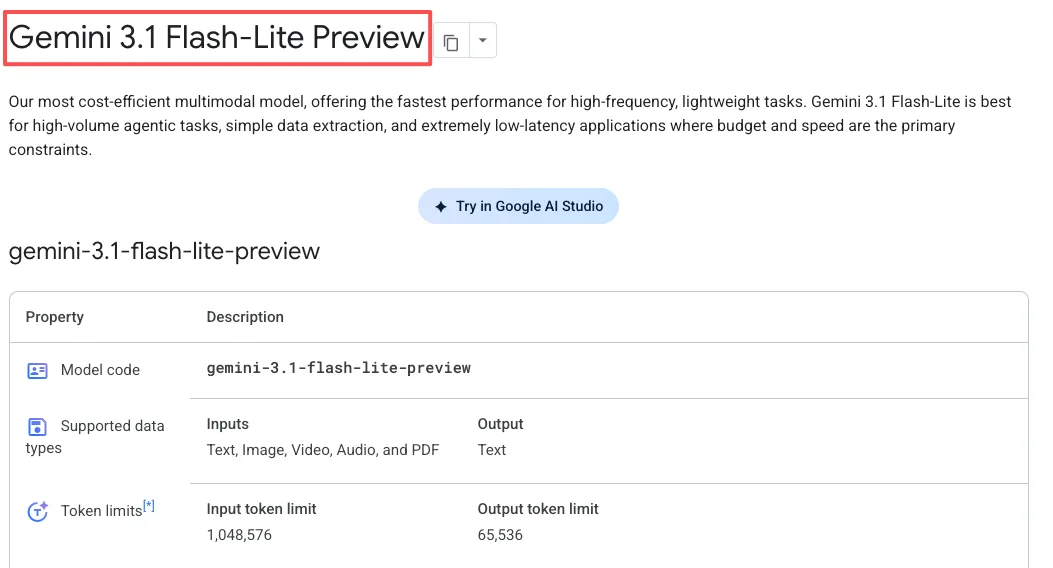
Flash-Liteはテキスト、画像、音声、動画に対応しています。コンテキストウィンドウは最大100万トークンで、最大64,000トークンのテキスト出力を生成できます。
eコマースのプロトタイプ用に、商品画像と説明文を組み合わせてテストしました。タグ付けは一貫していて高速でした。Wheringのような初期ユーザーは、複雑なファッションカテゴリのアイテムタグ付けで100%の一貫性を報告しています。ドリフトを許容できないシステムを構築する際には、こういった信頼性が重要です。
長いコンテキストウィンドウ
100万トークンのコンテキストウィンドウにより、ドキュメント全体、長い会話スレッド、大規模なデータセットをより小さな断片に分割せずに投入できます。フルウィンドウを頻繁に使うわけではありませんが、使う時 — たとえば複数ページのPDFを分析する場合など — スムーズなワークフローとストレスのあるワークフローの違いをはっきりと感じます。
Gemini 3.1 Flash-Lite vs Flash:直接比較
Flash-Liteを使うべき場面
Flash-Liteを使うべき場面は、何千、何百万もの類似タスクを実行するときです。翻訳パイプライン、コンテンツモデレーションキュー、大規模なセンチメント分析、基本的なデータ抽出 — タスクが明確に定義されていて、深い推論よりもトークン単価が重要なあらゆる場面に適しています。
またルーターとしても効果的だと分かりました。Flash-Liteを使って受信リクエストを「シンプル」または「複雑」に分類し、複雑なものをFlashまたはProにルーティングできます。これにより、重要な箇所での品質を犠牲にせずにコストを削減できます。
Flashを使うべき場面
タスクがマルチステップの推論、創造的な問題解決、または曖昧な指示への対応を必要とする場合は、Flashが最適な選択です。価格は2倍ですが、賢さも違います。特にコーディングタスクでは、一部のベンチマークでProと同等か上回る性能を示します。
自然言語プロンプトからUIコンポーネントを生成するタスクで両方をテストしました。Flash-Liteは明確なリクエスト(「ログインフォームを作成して」)は処理できましたが、曖昧なもの(「モダンでクリーンなデザインにして」)は苦労していました。Flashは両方を処理できました。
Gemini 3.1 Flash-Liteのユースケース
AIエージェントのルーティングとタスク分類
私が見てきた中で最もクリーンなユースケースの一つは、Flash-Liteをトラフィックコントローラーとして使用することです。ユーザーがリクエストを送信すると、Flash-Liteがそれを読み取り、複雑さを判断し、適切なモデルにルーティングします。中程度のタスクはFlashへ、難しいタスクはProへ。
このパターンはすでに本番ツールで使用されています。オープンソースのGemini CLIはまさにこの目的でFlash-Liteを使用しており、モデルがこのルーティングステップを追加してもレイテンシやコストを目に見えて増加させないほど高速かつ安価であるため、うまく機能しています。
大量チャットとサポートの自動化
カスタマーサポートこそ、コスト削減効果が最も顕著に現れる場所です。毎日何万件ものサポートチケットを処理している場合、入力100万トークンあたり0.25ドルと2.00ドルの差はすぐに大きくなります。
Flash-Liteは単純な質問への対応、意図の抽出、人間の対応が必要なチケットのルーティングを処理できます。複雑な技術的問題を解決するわけではありませんが、その必要もありません。信頼性が高く高速であればよいのです。
コンテンツモデレーションとタグ付け
ユーザー生成コンテンツをモデレートするクイックテストパイプラインを構築しました。スパム、不適切な言語、スレッド外の投稿にフラグを立てるものです。Flash-Liteは1分以内に約500件のアイテムを処理し、一貫した精度を示しました。
ここで重要なのは一貫性です。一部のモデルは時間とともにドリフトしたり、類似の入力に対して異なる回答を出したりします。Flash-Liteは繰り返し実行しても予測可能な結果を維持し、常に同じように動作することが求められるシステムを構築する際に重要です。
ドキュメント前処理パイプライン
Flash-Liteは構造化データの抽出に優れています。請求書や領収書のバッチを与えると、日付、金額、ベンダー名などの主要フィールドを抽出してJSONとして出力できます。
PDFの請求書の組み合わせでテストしたところ、ほとんどをきれいに処理しました。苦労したのはテキストが不鮮明な低品質スキャンでしたが、それはモデルではなく入力の制限によるものです。
Flash-LiteがAIインフラ設計に意味するもの

階層型モデルアーキテクチャパターン
Flash-Liteのリリースにより、業界標準パターンとなりつつあるものが完成しつつあります。3層モデルスタックです。難しい問題向けのヘビー級、日常使用向けのバランス型、高ボリュームの反復作業向けの軽量型という構成です。
これは新しいものではありません。OpenAIにはGPT-5 / GPT-5 mini、AnthropicにはClaude Opus / Sonnet / Haikuがあります。しかしGoogleの実装が興味深いのは、価格の差がより大きいことです。Flash-LiteはProと比較して本当に安価であり、以前は経済的に実現できなかったワークフローを可能にします。
安価なルーター+強力な推論エンジン — なぜ重要か
繰り返し見かけるパターンは、安価なモデルを使って扱っているタスクの種類を判断し、必要な場合にのみより高価なモデルにルーティングするというものです。これは単にコストを節約するためだけではありません。ヘビー級モデルの起動を待つ必要がないため、シンプルなタスクのレイテンシも改善されます。
100件のタスクの混合バッチでこれを試しました。半分はシンプル、半分は複雑なものです。Flash-Liteをルーターとして使用すると、シンプルなタスクは数秒で完了し、複雑なものはFlashにルーティングされました。複雑なタスクで品質を損なうことなく、総コストはすべてFlashで処理した場合より約40%低くなりました。
このアーキテクチャは、ルーターがボトルネックにならないほど高速かつ安価な場合にのみ機能します。Flash-Liteはその条件を満たしています。
現在の提供状況とAPIステータス
Gemini 3.1 Flash-Liteは現在、Google AI StudioのGemini APIとVertex AIでプレビューとして利用可能です。コンシューマー向けGeminiアプリには含まれていません。これは開発者向けです。
プレビューモデルは安定版になる前に変更される可能性があり、レート制限も厳しくなっています。実際には通常のテストでその制限に達したことはありませんが、大規模な本番デプロイを計画している場合は注意が必要です。
モデルは積極的に更新されています。Googleのリリースノートには、指示への追従、音声入力品質、推論能力の継続的な改善が示されています。まだ初期段階であり、今後数ヶ月でさらに改善される可能性が高いです。
残る思考
私が繰り返し考えることは、スピードやコストではありません。Flash-Liteによって、特定のワークフローが実験のように感じるのではなく、インフラのように感じられるという事実です。コストが十分に低くなると、「これにAIを使うべきか?」という問いから、「どうすればスケールするように構築できるか?」という問いに変わります。
そのシフト — 目新しさからインフラへ — こそが、ツールが定着し始める地点です。





