Arrêtez d'entraîner, commencez à créer : Utilisez LoRA sur WaveSpeedAI


Introduction
Qu’est-ce que la LoRA ? Pensez-y comme une méthode d’ajustement fin légère : au lieu de réentraîner le modèle entier, vous pouvez simplement ajouter une petite couche « d’adaptation rapide » à un modèle existant pour verrouiller votre propre style — plus rapidement et moins cher.
Dans ce tutoriel, nous commencerons de zéro et vous montrerons comment trouver les modèles LoRA que vous aimez en ligne et les utiliser dans WaveSpeedAI. Même si vous êtes novice, vous serez opérationnel en un rien de temps.
Sélection du modèle
Lors de la création d’images et de vidéos avec l’IA générative, nous ne pouvons généralement contrôler le modèle que par le biais d’invites, ce qui rend difficile la gestion des détails fins. Si vous dépendez du modèle pour « comprendre par lui-même » des choses comme les poses des mains, les plis du tissu ou les éléments vestimentaires, les résultats sont souvent insatisfaisants.
À ce stade, vous pouvez explorer des plateformes ouvertes pour trouver des modèles LoRA partagés par des créateurs. Du style artistique global et de la texture de la caméra aux poses spécifiques, tenues et minuscules accessoires. Les LoRAs ciblées peuvent améliorer les détails et vous donner plus de contrôle — sans réentraîner un modèle.
Cependant, n’oubliez pas une règle importante lors de la sélection d’une LoRA : elle doit correspondre exactement au modèle de base AIGC que vous utilisez — même nom de modèle, même version, et même taille de paramètre.
Par exemple, une LoRA conçue pour Wan 2.2 ne peut pas être utilisée sur Wan 2.1 ou tout autre modèle. De même, une LoRA Wan 2.2 14B ne peut pas être utilisée sur Wan 2.2 5B.
Si ces éléments ne correspondent pas, le style pourrait changer au mieux. Au pire, vous pourriez rencontrer des erreurs. Vérifiez toujours deux fois les informations sur la page du modèle avant de l’utiliser !
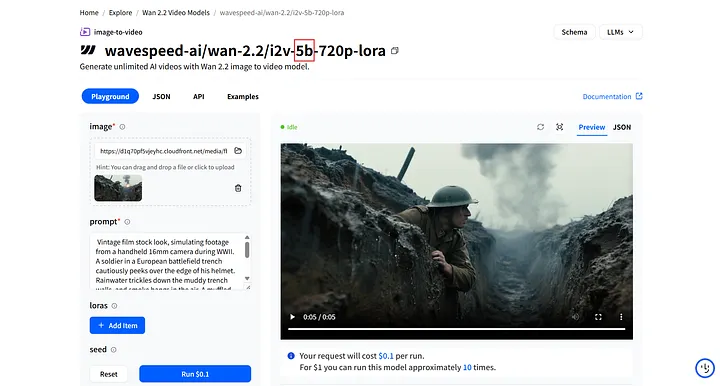 Vérifiez deux fois la version et les paramètres
Vérifiez deux fois la version et les paramètres
P.S. Sur WaveSpeedAI, les LoRAs s’exécutent à partir d’un seul fichier .safetensors. Importez-le simplement et c’est tout. Évitez .PickleTensor, .zip, .GGUF, etc., car WaveSpeedAI ne supporte pas ces formats.
Surveillez la taille du fichier. Les LoRAs font généralement moins de 2 GB (souvent juste quelques centaines de MB). Si votre téléchargement est beaucoup plus volumineux, vous avez peut-être sélectionné le mauvais fichier (comme le modèle de base complet ou un ensemble compressé), et l’importation échouera. Vérifiez deux fois le nom de fichier et l’extension avant de réessayer !
Voici deux plateformes couramment utilisées : Civitai et Hugging Face.
 Plateforme Civitai
Plateforme Civitai
 Plateforme Hugging Face
Plateforme Hugging Face
LoRA sur Hugging Face
Hugging Face est l’un des plus grands hubs de modèles open-source du monde, offrant un vaste catalogue de modèles et d’ensembles de données. Vous pouvez rechercher des LoRAs et trouver des poids officiels et des guides d’inférence pour les modèles de base populaires.
Dans cette partie, nous allons nous concentrer sur la LoRA — comment la localiser, la sélectionner sur Hugging Face et l’utiliser sur WaveSpeedAI.
Commencez par taper LoRA dans la barre de recherche en haut du site pour voir les dépôts associés.
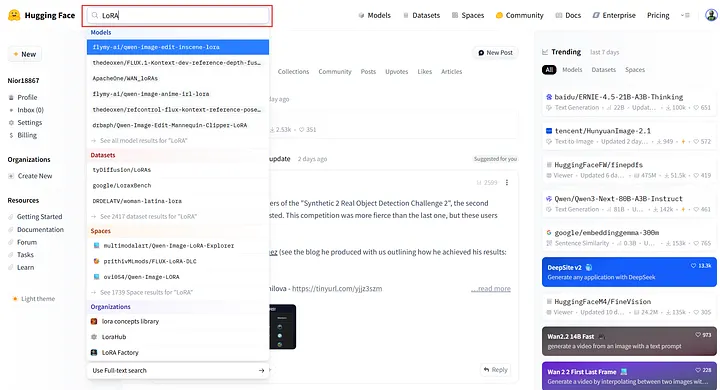 Rechercher LoRA
Rechercher LoRA
Ensuite, cliquez sur See all model results for “LoRA” pour afficher la page complète des résultats LoRA.
Pour vos propres recherches, incluez des qualificatifs comme le nom du modèle de base, la version et la taille des paramètres (par exemple, 7B/14B). Cela réduit la recherche et affiche des résultats plus pertinents.
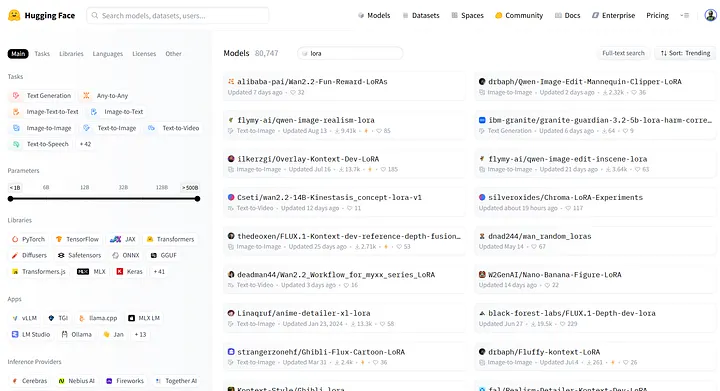 Page des résultats du modèle
Page des résultats du modèle
Sur Hugging Face, les modèles LoRA spécifient généralement le modèle de base compatible et la taille des paramètres dans le titre ou la description.
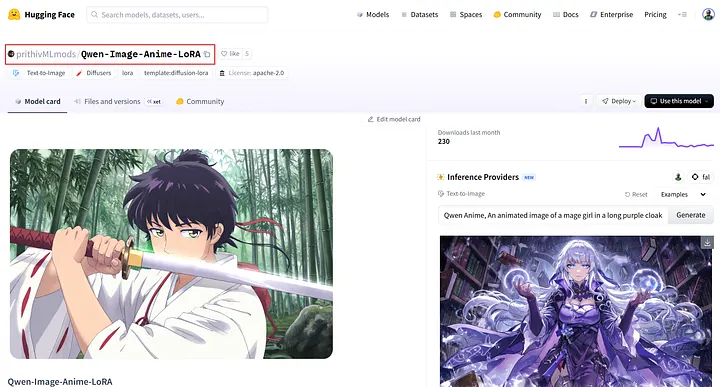
Par exemple, prithivMLmods/Qwen-Image-Anime-LoRA est une LoRA créée pour Qwen-Image et utilisée pour générer des images de style anime japonais.
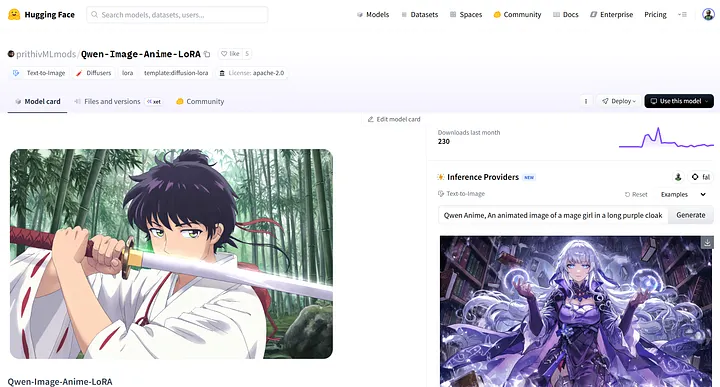 prithivMLmods/Qwen-Image-Anime-LoRA
prithivMLmods/Qwen-Image-Anime-LoRA
Comme le montre la page, Qwen-Image-Anime-LoRA est publié par prithivMLmods et est spécifiquement conçu pour le modèle de base Qwen-Image.
Ensuite, passez à WaveSpeedAI et ouvrez le modèle wavespeed-ai/qwen-image/text-to-image-lora. Nous l’utiliserons pour charger et exécuter cette LoRA.
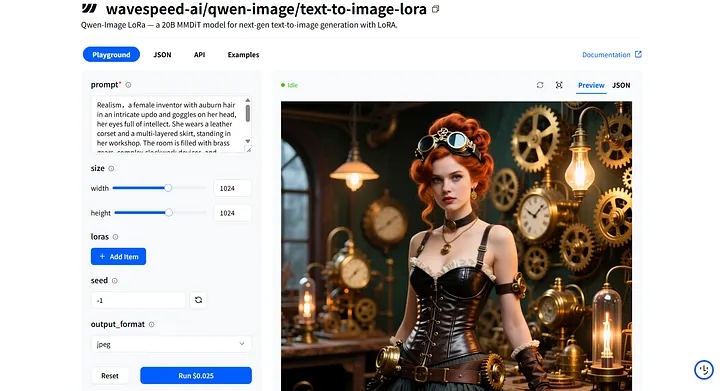 wavespeed-ai/qwen-image/text-to-image-lora
wavespeed-ai/qwen-image/text-to-image-lora
Sur la page Playground du modèle, vous trouverez le champ d’entrée prompt pour entrer votre invite, ainsi que la section loras pour ajouter un modèle LoRA.
Lorsque vous écrivez votre invite, en plus de décrire clairement la scène, le style et les détails que vous voulez, n’oubliez pas d’inclure le mot déclencheur de la LoRA ! Vous pouvez généralement trouver cette information sur la page Hugging Face dans la Model Card.
Par exemple, sur la page du modèle prithivMLmods/Qwen-Image-Anime-LoRA, faites défiler la Model Card pour trouver des détails supplémentaires, comme la façon d’utiliser le modèle et le mot déclencheur exact requis.
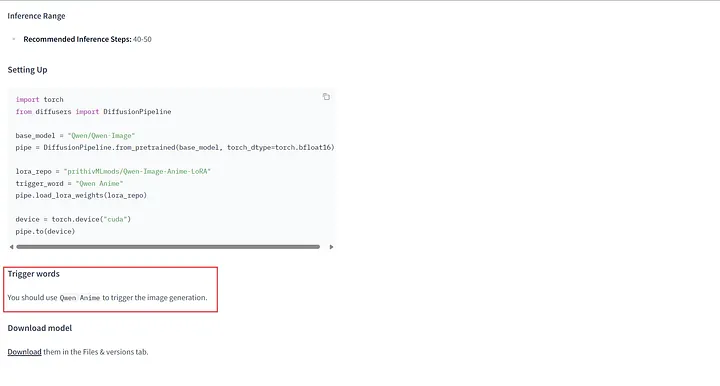 Mots déclencheurs dans la Model Card
Mots déclencheurs dans la Model Card
Après cela, nous modifierons les paramètres liés au modèle LoRA.
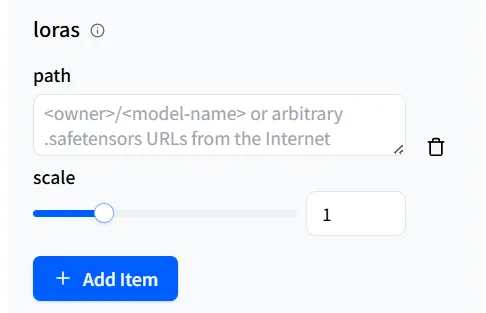
Le premier est le path. C’est le chemin que WaveSpeedAI utilise pour appeler le modèle LoRA que vous souhaitez.
Cliquez sur + Add Item pour révéler un champ d’entrée. Le pipeline qwen-image/text-to-image-lora permet d’ajouter jusqu’à trois modèles LoRA.
De plus, si le modèle LoRA est hébergé sur Hugging Face, WaveSpeedAI propose deux façons de le référencer : l’une est <owner>/<model-name>.
Exactement comme dans cet exemple, le nom de l’auteur plus le nom du modèle tel qu’il apparaît sur la page du modèle.
 Copiez ceci et collez dans le chemin !
Copiez ceci et collez dans le chemin !
L’autre méthode consiste à aller à Files and versions du modèle, cliquer avec le bouton droit sur l’icône de téléchargement, sélectionner Copy link address, et coller l’URL copiée dans le path.
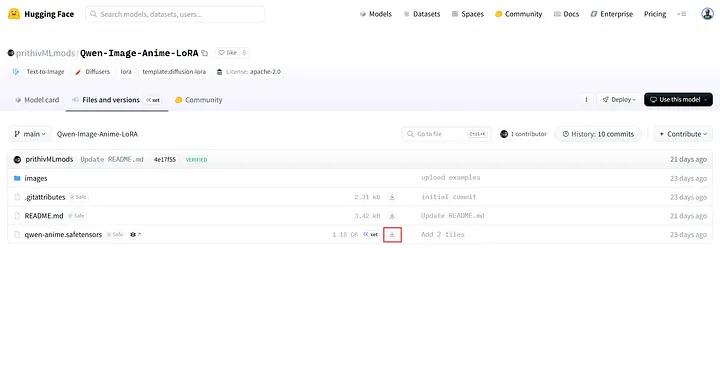 Bouton de téléchargement dans Files and versions
Bouton de téléchargement dans Files and versions
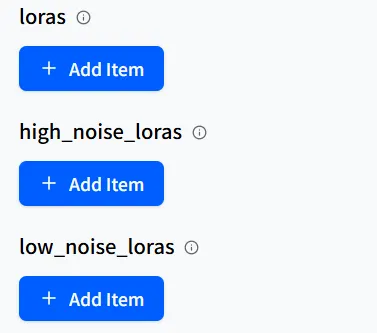
Parfois, vous pouvez voir les options high-noise LoRA et low-noise LoRA sur la page du modèle. Celles-ci ne sont généralement pas couramment utilisées, mais Hugging Face fournit généralement des informations détaillées à ce sujet.
Remplissez simplement le modèle LoRA avec le nom correspondant dans le champ approprié comme vous le feriez avec une LoRA normale, et cela fonctionnera bien.
Dans les paramètres loras, il y a un curseur appelé scale, que vous pouvez considérer comme un bouton de volume « influence/concentration ». Il règle l’intensité avec laquelle la LoRA affecte le modèle de base.
Dans la plupart des cas, la valeur par défaut 1 vous donnera de bons résultats. Si le résultat ne correspond pas à vos attentes, vous pouvez légèrement augmenter le scale.

Le Seed est utilisé pour contrôler l’aléatoire. Pensez-y comme un « index de départ ».
Lorsque vous utilisez la même graine, puis ajustez l’invite, le style général et la composition resteront largement cohérents. Seules les parties que vous avez modifiées dans l’invite seront différentes, ce qui facilite la comparaison et la reproduction.
Excellent ! Vous avez terminé tous les préparatifs ! Commençons à utiliser le modèle LoRA !
Dans le champ de l’invite, entrez d’abord le mot déclencheur Qwen Anime pour le modèle LoRA. Ensuite, fournissez la description du résultat que vous souhaitez générer.
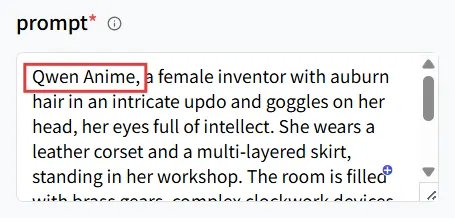 Entrez le mot déclencheur
Entrez le mot déclencheur
Ensuite, dans le champ loras, dans le path, entrez prithivMLmods/Qwen-Image-Anime-LoRA ou son URL, et gardez le scale à 1.
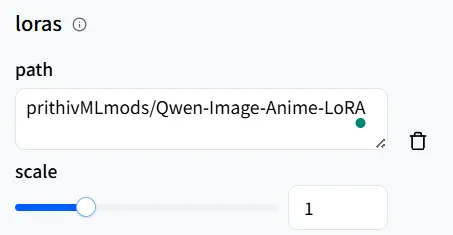 Définissez le chemin
Définissez le chemin
Définissez ensuite le seed pour pouvoir facilement reproduire les résultats que vous souhaitez plus tard.
 Numéro de graine aléatoire
Numéro de graine aléatoire
Enfin, cliquez sur le bouton Run pour générer une image de style anime !
 Le résultat
Le résultat
Comme nous avons déjà défini une graine plus tôt, si vous êtes satisfait du fond et des détails de style (comme les vêtements) mais que vous souhaitez changer le genre du personnage, modifiez simplement l’invite et cliquez sur Run à nouveau.
 Vous savez, je voulais juste comparer les résultats
Vous savez, je voulais juste comparer les résultats
À quoi ça ressemble ? Pouvez-vous voir les changements ? Essayez vous-même ! WaveSpeedAI a de nombreux modèles de base qui peuvent appeler la LoRA. N’hésitez pas à expérimenter, puis partagez votre travail dans Inspiration avec nous et la plus grande communauté créative !
 Page Inspiration
Page Inspiration
LoRA sur Civitai
Civitai est une communauté axée sur les créateurs qui partage des modèles, présentant une grande variété de ressources LoRA. Vous pouvez rechercher par style ou thème, parcourir les résultats et paramètres d’exemple, et trouver rapidement un modèle adapté.
 Page Civitai
Page Civitai
La méthode de recherche sur Civitai est similaire à Hugging Face : entrez des détails comme la version du modèle et la taille des paramètres dans la zone de recherche. Ajoutez le mot-clé « LoRA » pour filtrer rapidement un grand nombre de modèles pertinents (par exemple : « Wan 2.2 14B LoRA »).
L’utilisation de base est similaire à l’appel de modèles sur Hugging Face, nous expliquerons donc uniquement les différences en détail.
Utilisant la conception de jeux comme exemple, si vous souhaitez créer un personnage avec un style similaire à Baldur’s Gate 3, vous pouvez directement essayer la LoRA [WAN2.1] Baldur’s Gate 3 [STYLE].
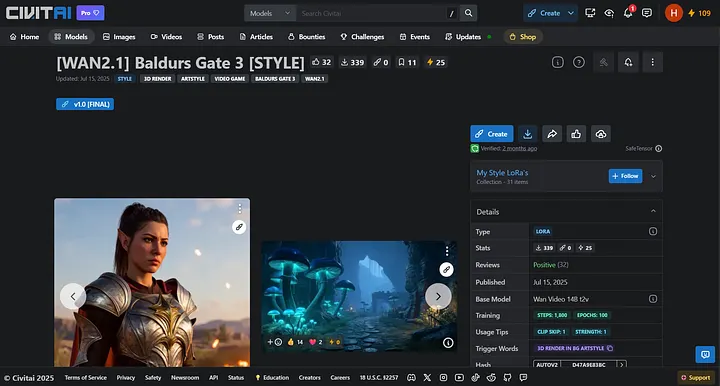 Page [WAN2.1]Baldur’s Gate 3 [STYLE]
Page [WAN2.1]Baldur’s Gate 3 [STYLE]
Cependant, veuillez noter que pour les modèles sur la plateforme Civitai, WaveSpeedAI ne supportera pas l’invocation des modèles LoRA en utilisant le format <owner>/<model-name>.
Ils ne peuvent être appelés que via URL. Par conséquent, assurez-vous de consulter les informations du modèle avant de l’invoquer.
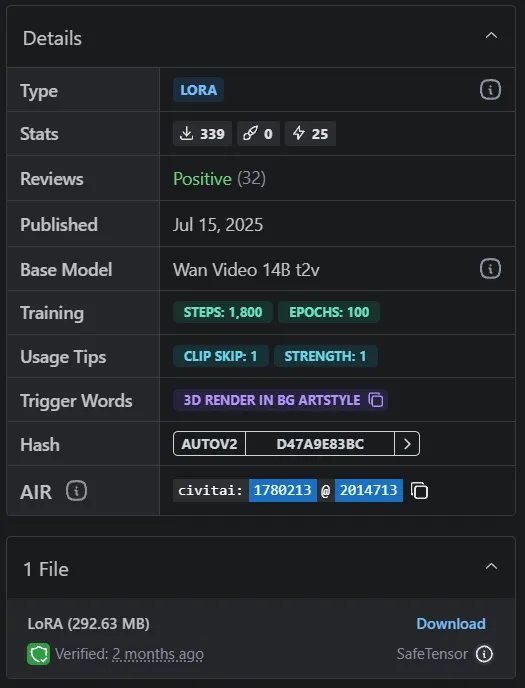 Détails du modèle LoRA
Détails du modèle LoRA
Dans la section Details du modèle, vous pouvez voir diverses informations sur le modèle.
Les principaux éléments sur lesquels se concentrer sont Base Model et Trigger Words. Ici, nous voyons que le modèle de base de cette LoRA est Wan Video 14B t2v, et le mot déclencheur est 3d render in bg artstyle.
Ouvrez WaveSpeedAI et recherchez wavespeed-ai/wan-2.1/t2v-720p-lora. Bien sûr, vous pouvez également choisir d’autres modèles qui supportent l’invocation de LoRA (comme wavespeed-ai/wan-2.1/i2v-720p-lora).
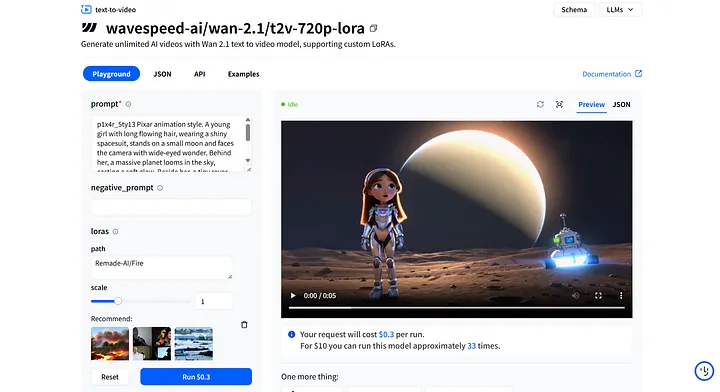 Page wavespeed-ai/wan-2.1/t2v-720p-lora
Page wavespeed-ai/wan-2.1/t2v-720p-lora
Tout comme sur la plateforme Hugging Face, vous n’avez besoin que de modifier l’invite et d’ajouter le mot déclencheur LoRA dans Prompt, puis d’inclure l’URL pour appeler le modèle LoRA dans path.
Utilisez scale pour contrôler l’influence de la LoRA sur le modèle de base (la valeur par défaut 1 est généralement suffisante. Si cela semble trop faible ou trop fort, faites de petits ajustements), et enfin utilisez seed pour la reproduction et la comparaison.
Certains modèles ont des paramètres spécifiques, mais sur WaveSpeedAI, nous avons déjà défini les valeurs par défaut pour vous. Les utiliser directement vous donnera de bons résultats !
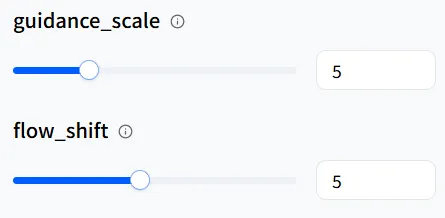
Si vous souhaitez affiner davantage les détails, vous pouvez essayer de les ajuster. Cependant, veuillez noter que pour des paramètres comme num_inference_steps, plus la valeur est élevée, plus l’augmentation du temps de génération vidéo sera perceptible.
Vous trouverez la section de téléchargement du modèle LoRA ici. Assurez-vous de choisir le type de modèle SafeTensor pour un fonctionnement correct.
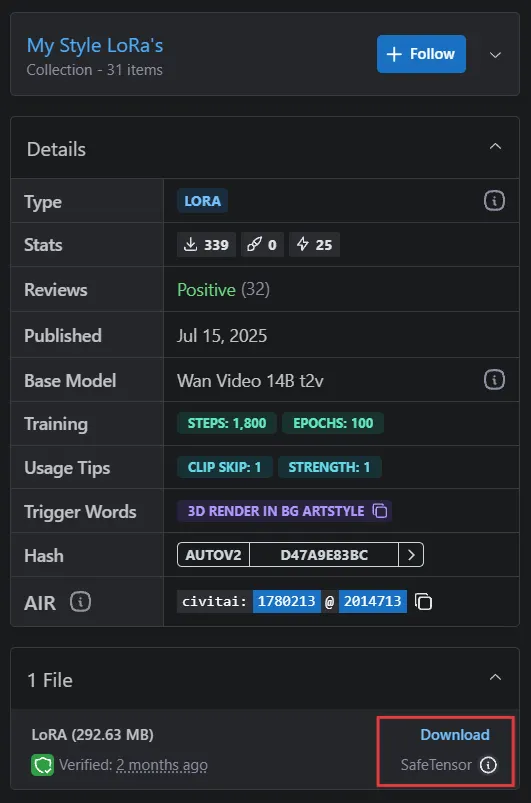 Télécharger LoRA
Télécharger LoRA
Cliquez avec le bouton droit sur Download, puis copiez l’adresse du lien — c’est l’URL que vous utiliserez pour invoquer le modèle LoRA.
De même, dans le Playground de wavespeed-ai/wan-2.1/t2v-720p-lora, trouvez la section loras, cliquez sur + Add Item, et collez l’URL que vous venez de copier dans le path.
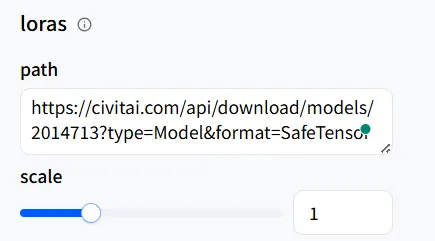 Collez dans path
Collez dans path
Si vous ne savez pas comment utiliser la LoRA plus efficacement, vous pouvez consulter les références sur Civitai. Les auteurs de modèles fournissent souvent des exemples sur lesquels vous pouvez cliquer et consulter.
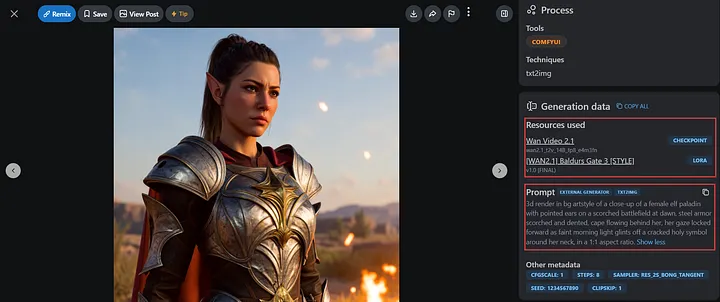 Page d’exemple avec ressources et invite
Page d’exemple avec ressources et invite
Ici, nous copierons l’invite de l’exemple de l’auteur pour essayer de créer notre propre personnage de jeu.
Le résultat que nous avons créé !
N’est-ce pas incroyable ? Le résultat généré peut varier légèrement de celui de l’auteur, mais vous pouvez ajuster l’invite vers votre objectif (clarifier le style, les matériaux, la caméra et l’ambiance, et ajouter ou supprimer des modificateurs selon les besoins) pour atteindre progressivement l’effet souhaité.
Après tout, les travaux les plus significatifs ne sont pas des copies des autres, mais ceux qui mettent toujours en avant votre texture et votre style uniques — c’est exactement là que réside la compréhension implicite entre la LoRA et votre création.
Conclusion
À ce stade, vous avez appris à utiliser les modèles LoRA que vous préférez sur WaveSpeedAI. Mais rappelez-vous, la LoRA ne fera pas les choix esthétiques à votre place. Elle stabilise uniquement les détails après que vous ayez défini la direction. Ce qui rend vraiment une œuvre unique, c’est toujours votre goût et votre imagination.
Soyez donc audacieux — essayez, apprenez et continuez à vous améliorer. Lorsque vous partagez vos premiers résultats sur Inspiration et grandissez avec la communauté, vous verrez que l’efficacité n’est que le début. Avoir votre style reconnu est le véritable objectif.
Nous vous souhaitons une création fluide et un succès tel que vous l’aviez envisagé !
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Examen de Vidu Q3 : Comment il se compare à Sora 2, Wan 2.6, Seedance 1.5, Veo 3.1 et Grok Imagine Video

Grok Imagine Video vs Sora 2, Veo 3.1, Seedance 1.5, WAN 2.5/2.6, et Vidu Q3 : Comparaison complète
