Z-Image LoRA : Qu'est-ce que c'est et quand en avez-vous besoin (Amical pour les débutants)

Bonjour, mes amis. Dora est là. Je n’avais pas prévu d’entraîner quoi que ce soit la semaine dernière. Je voulais juste un petit assistant cohérent, un personnage illustré à placer dans le coin de mes captures d’écran. Les prompts m’en rapprochaient, puis s’en éloignaient. Les sourcils changeaient. Les couleurs glissaient. Mardi (13 janvier 2026), après quelques presque-réussites, j’ai essayé Z-Image LoRA. Je m’attendais à un trou de lapin. C’était plutôt un petit couloir.
Ce n’est pas une victoire. Ce n’était pas instantané. Mais la configuration a enlevé assez de friction pour que j’arrête de penser aux paramètres et que je commence à penser à mes images. Voici ce qui a fonctionné, ce qui n’a pas fonctionné, et quand vous n’aurez probablement pas besoin d’une LoRA du tout.
Z-Image LoRA en une minute
Une LoRA (Low-Rank Adaptation) est un petit ajout que vous entraînez sur un modèle d’image de base pour le pousser vers un style ou un sujet spécifique sans réentraîner le modèle entier.
 Ce que Z-Image LoRA (Convivial pour les débutants) fait bien :
Ce que Z-Image LoRA (Convivial pour les débutants) fait bien :
- Cache les boutons effrayants. Vous choisissez toujours quelques éléments de base (images, légendes, cible), mais les valeurs par défaut sont sensées.
- S’entraîne assez vite pour itérer. Ma première tentative (10 images) a pris environ 12-18 minutes sur un GPU de milieu de gamme.
- Se charge comme une couche. Vous l’activez dans votre outil de génération et vous promptez normalement, plus un mot déclencheur facultatif.
Ce que vous obtenez : un minuscule fichier qui oriente le modèle quand vous avez besoin de cohérence, de logos, d’un personnage, d’une apparence d’aquarelle brossée, sans vous enfermer. Si vous ne l’activez pas, le modèle de base se comporte comme d’habitude.
Quand vous N’AVEZ PAS besoin de LoRA
Je dis cela avec affection : beaucoup d’entre nous recourent à l’entraînement trop rapidement. Quelques cas où je ne m’embête pas :
- Le modèle de base est déjà proche. Si un prompt court avec une image de référence vous donne 8/10 résultats utilisables, c’est terminé. Un IP-Adapter ou un prompt d’image peut suffire.
- Vous avez besoin de variation, pas de cohérence. Si chaque sortie doit divaguer, une LoRA peut trop vous diriger.
- Des visuels ponctuels. Pour une bannière unique, je vais passer cinq minutes supplémentaires à prompter plutôt que de configurer l’entraînement.
- La contrainte réside dans la composition, pas l’identité. Des outils comme ControlNet ou la guidance de pose façonnent la mise en page sans enseigner au modèle un nouveau concept.
Un test rapide que j’utilise : si un simple balayage de seed et 2-3 ajustements de prompt ne peuvent pas maintenir l’élément qui m’importe (même personnage, mêmes proportions de logo) sur cinq images, c’est alors que je considère une LoRA. Sinon, je garde les choses simples.
Quand LoRA aide
J’ai ressenti la différence surtout dans deux situations cette semaine (janvier 2026) :
- Une petite mascotte que je voulais réutiliser sur plusieurs documents. Les prompts gardaient une instabilité sur les yeux et la couleur de la chemise. Après une courte LoRA, ceux-ci se sont stabilisés, et j’ai pu me concentrer sur les poses et les arrière-plans.
- Une texture de crayon doux pour les diagrammes. Je pouvais prompter « crayon sketch », mais l’ombrage changeait à chaque fois. Une LoRA de style de 15 images m’a donné une qualité de ligne constante sans verrouiller le contenu.
Signaux qu’une LoRA aidera probablement :
- Vous avez besoin du même sujet dans de nombreuses scènes.
- Une texture d’art spécifique compte (hachures croisées, points risographe, épaisses arêtes de gouache) et continue de dériver.
- Vous voulez réduire les acrobaties de prompts. Après l’entraînement, mes prompts sont passés de 80-100 tokens à 30-40. L’effort mental a diminué plus que le temps.
Ce qui m’a surprise, c’est la discrétion de l’impact. Pas de dramatique avant/après. Juste moins de retries, moins de « presque ».
Exigences en matière de données
 J’ai gardé cela simple et cela a fonctionné mieux que je ne l’espérais. Quelques notes de deux courtes exécutions la semaine dernière :
J’ai gardé cela simple et cela a fonctionné mieux que je ne l’espérais. Quelques notes de deux courtes exécutions la semaine dernière :
Quantité
- Personnage/sujet : 8-20 images peuvent suffire si elles sont variées (angles, éclairage, légers changements de tenue). J’en ai utilisé 12.
- Style/texture : 10-30 images qui partagent la même apparence mais un contenu différent. J’en ai utilisé 15.
Qualité
- Résolution : fournissez des images qui correspondent à peu près à votre taille de génération. Si vous prévoyez de générer à 1024, ne vous entraînez pas sur de minuscules cultures de 256.
- La variété surpasse le volume : Cinq copies de la même pose enseignent très peu au modèle et le poussent vers le surapprentissage.
- Les arrière-plans propres aident pour les personnages : Les scènes chargées brouillent le signal.
Légendes
- Court et littéral : « une petite mascotte bleue avec des yeux ronds, chemise rouge », « crayon sketch, hachures croisées, ombre douce ».
- Soyez cohérent avec la dénomination. Si vous inventez un nom unique pour un personnage (comme « mori-kiko »), utilisez-le dans chaque légende pour pouvoir le déclencher plus tard.
- Vous pouvez commencer par des légendes automatiques, puis les nettoyer légèrement. J’ai supprimé les adjectifs qui ne reflétaient pas l’idée centrale.
Processus que j’ai utilisé
- 12 photos de sujet (de face/trois quarts/profil), arrière-plans neutres.
- 15 cadres de style de mes propres diagrammes, même texture de papier.
- Une seule passe, rang par défaut, régularisation légère. Temps d’entraînement : ~16 minutes sur un A10G loué. Configuration : ~10 minutes. La deuxième exécution a utilisé 20% d’étapes en moins et a tenu bon.
Si vous ne vous souvenez que d’une chose : moins d’images claires surpassent les dossiers volumineux et bruyants.
Style vs LoRA de personnage
J’avais l’habitude de les regrouper. Ils se comportent différemment.
LoRA de personnage/sujet
- Objectif : enseigner une identité spécifique (une personne, une mascotte, un produit).
- Données : sujet cohérent, contextes variés : gros plans du visage si l’identité faciale compte.
- Prompts : gardez le nom déclencheur plus une brève description. Laissez la LoRA gérer l’identité : vous dirigez la pose/la scène.
- Risques : surapprentissage sur les tenues ou les arrière-plans. Variez-les.
LoRA de style/texture
- Objectif : enseigner une qualité de surface (travail au trait, palette, coup de pinceau, grain).
- Données : de nombreux sujets différents, un style.
- Prompts : aucun nom déclencheur nécessaire, mais un marqueur simple aide (« style sketchline »).
- Risques : le style engloutissant le contenu. Si tout devient la même peinture molle, réduisez la force.
Force et mélange
- La plupart des outils exposent un poids LoRA. Je dépasse rarement 0,8 pour les personnages ou 0,6 pour les styles. De petites impulsions comptent.
- Vous pouvez empiler deux LoRAs (une style, une personnage). J’ai obtenu les meilleurs résultats quand l’une était dominante et l’autre restait en dessous de 0,4.
J’ai appris à penser à la LoRA de personnage comme « qui » et à la LoRA de style comme « comment ». Simple, mais cela m’empêche de blâmer la mauvaise chose.
Mythes courants
Quelques affirmations que je rencontre beaucoup, et ce que j’ai réellement vu :
- « Vous avez besoin de centaines d’images. » J’ai entraîné un personnage utilisable avec 12. Plus aide, mais seulement s’il y a variété et propreté.
- « Cela prend des heures. » Avec un GPU modeste et un préset pour débutants, mes exécutions ont duré moins de 20 minutes. Les configurations lourdes et personnalisées peuvent prendre plus longtemps.
- « LoRA remplace l’ingénierie des prompts. » Elle réduit le bricolage mais ne l’élimine pas. Je fais toujours des prompts pour la composition, l’éclairage et l’ambiance.
- « Une LoRA s’adapte à tous les modèles. » Pas toujours. Une LoRA entraînée sur une base peut se transférer correctement vers un modèle frère, mais les résultats changent. Je les traite comme liés, pas interchangeables.
- « Une force plus élevée = mieux. » Au-delà d’un certain point, les images s’effondrent en uniformité. Si les détails s’estompent, réduisez le poids.
- « Les légendes automatiques non éditées vont bien. » C’est un bon départ. Je trimme toujours les adjectifs bizarres (« sinistre », « cinématique ») qui ne faisaient pas partie du concept.
Rien de cela n’est magique. Ce sont de petits ajustements répétables qui s’accumulent.
Glossaire rapide
- LoRA : Un ensemble compact de mises à jour de poids apprises qui adapte un grand modèle vers un concept cible sans réentraîner tout. Selon la documentation LoRA d’IBM, elle peut réduire les paramètres entraînables jusqu’à 10 000 fois par rapport à l’affinement complet.
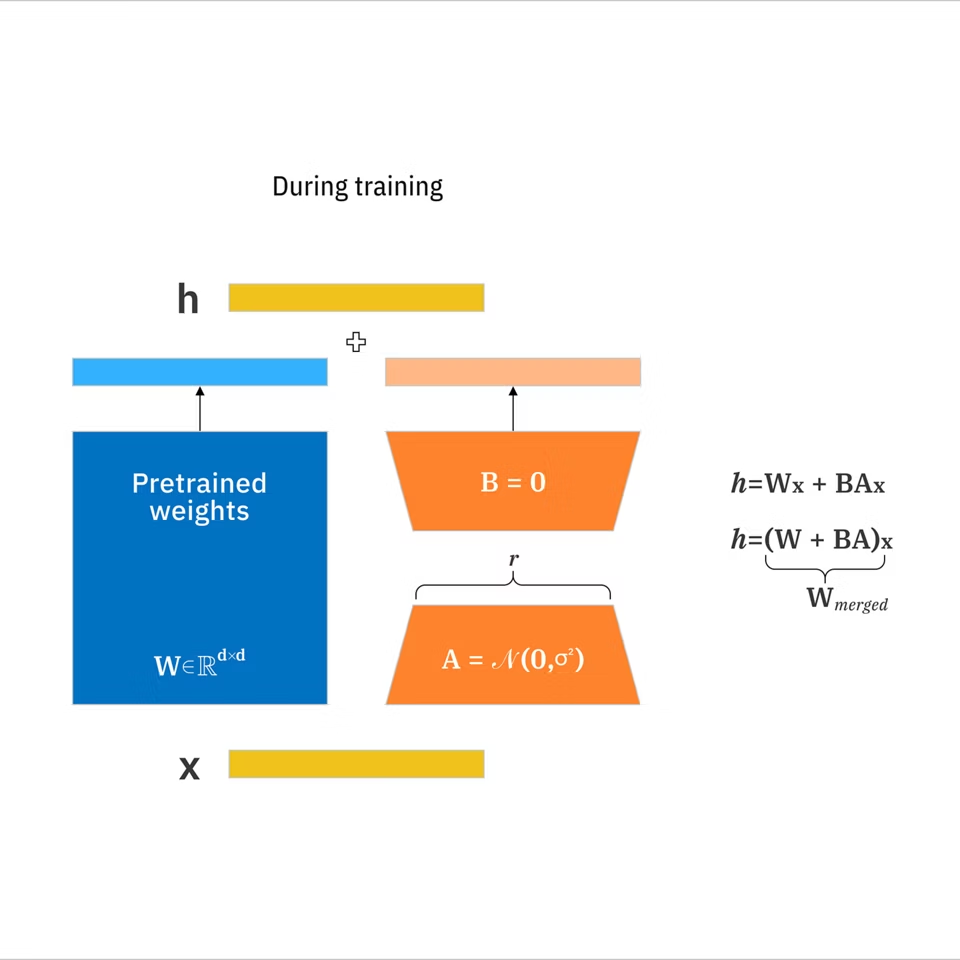
- Modèle de base : La fondation à partir de laquelle vous générez (ce que vous chargez avant toute LoRA).
- Rang (r) : Un paramètre qui contrôle l’expressivité de la LoRA. Un rang plus élevé peut capturer plus de nuances mais peut surapprentissage et gonfler la taille.
- Poids/Force : La force avec laquelle la LoRA influence la génération au moment de l’inférence.
- Mot déclencheur : Un jeton unique que vous utilisez dans les prompts pour appeler une LoRA de sujet (par exemple, le nom inventé que vous avez utilisé dans les légendes).
- Surapprentissage : Quand le modèle mémorise les images d’entraînement et cesse de généraliser. Apparaît comme des quasi-doublons.
- Régularisation : Techniques ou données supplémentaires pour prévenir le surapprentissage.
- UNet/Encodeur de texte : Parties du modèle qui gèrent les images et le texte. Certains entraînements mettent à jour les deux : les présets pour débutants touchent souvent davantage le côté image.
- Légende : Le texte associé à chaque image d’entraînement.
- Checkpoint : Un état enregistré d’un modèle ou d’une LoRA.
Si l’un de ceux-ci semble flou, vous pouvez toujours vous entraîner. Le préset pour débutants est conçu pour vous tenir à l’écart des ennuis.
Prochaines étapes sur WaveSpeed
J’ai utilisé le chemin convivial pour débutants sur WaveSpeed pour exécuter Z-Image LoRA sans chasser les paramètres. Le flux était calme :
- Choisissez un modèle de base.
- Déposez 8-20 images et de courtes légendes.
- Choisissez « style » ou « personnage ».
- Commencez l’entraînement et prenez un thé.
- Chargez la LoRA pour la génération et essayez deux poids (0,4 et 0,8) pour sentir l’étendue.
Ce qui a aidé le plus, c’était de traiter la première exécution comme un croquis. J’ai cherché deux choses : l’identité s’est-elle maintenue sur cinq prompts, et le style a-t-il gardé sa texture sans engloutir le contenu ? Si l’un échouait, j’ajustais l’ensemble de données, pas seulement les curseurs.
Si vous faites face aux mêmes contraintes, des personnages qui dérivent, des textures qui vacillent, c’est worth a look. Cela a fonctionné pour moi : vos résultats peuvent varier.
C’est exactement pourquoi nous avons construit WaveSpeed. Quand les personnages dérivent, les styles vacillent, et les prompts se transforment en acrobaties, nous voulions un moyen plus calme d’obtenir de la cohérence sans sur-ingénierie. Sur WaveSpeed, nous exécutons Z-Image LoRA avec un flux convivial pour débutants — des valeurs par défaut claires, une itération rapide, et juste assez de contrôle pour garder les identités et les textures stables, afin que vous puissiez passer moins de temps à réessayer et plus de temps à vraiment créer des images.
→ Entraînez une simple LoRA sur WaveSpeed
 Une petite note que je me garde pour moi : moins je me bats avec les mots du prompt, plus j’ai d’attention pour l’image devant moi. C’est la partie que je ne veux pas automatiser.
Une petite note que je me garde pour moi : moins je me bats avec les mots du prompt, plus j’ai d’attention pour l’image devant moi. C’est la partie que je ne veux pas automatiser.
Articles associés

Seedance 2.0 arrive bientôt : Le modèle vidéo nouvelle génération de ByteDance avec audio natif

Guide Complet Seedance 2.0 : Création Vidéo Multimodale

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1 : La Comparaison Ultime de la Génération Vidéo

Guide Complet Seedream 5.0-Preview : Génération d'Images Intelligente

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image : Comparaison Complète
