Nano Banana Pro API en WaveSpeed: Cómo Llamarlo + Notas de Precios

Alguna vez miraste la documentación de Nano Banana Pro API en WaveSpeed y pensaste “¿Qué se supone que debo hacer ahora?” No estás solo. Soy Dora, he probado personalmente docenas de APIs, y he tenido mi buena parte de endpoints sin documentar y correos sorpresa de facturación. En esta guía, te camino paso a paso a través de cómo llamar a Nano Banana Pro API de manera limpia y evitar trampas de precios que pueden sorprender a tu presupuesto de proyecto.
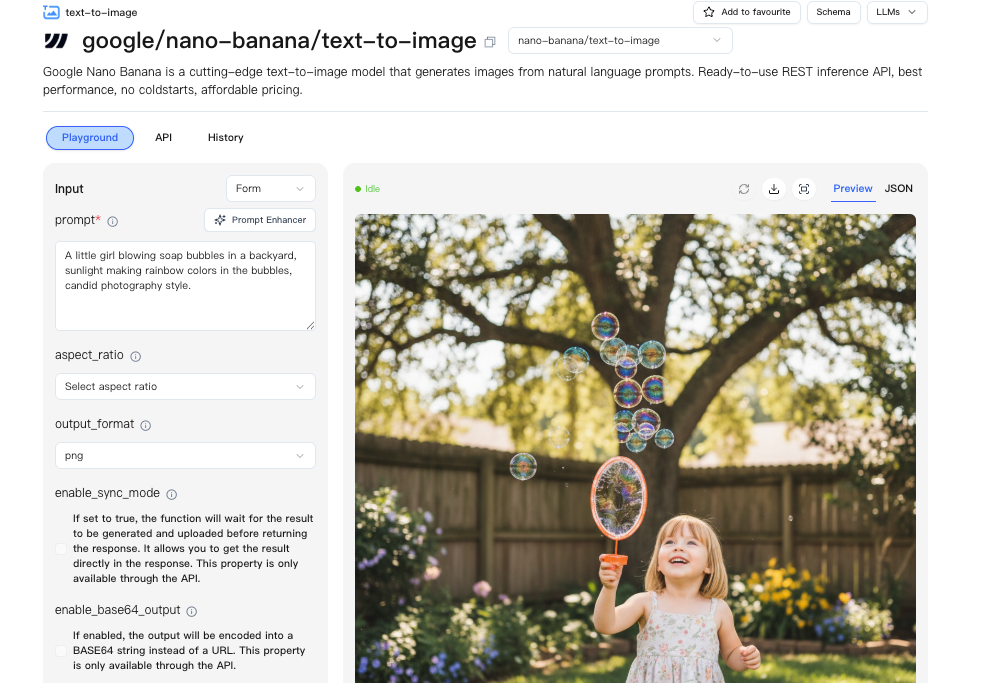
Endpoint / flujo
No cambié mi pila completa. Envolví Nano Banana Pro detrás de un pequeño servicio adaptador, para poder alternar entre proveedores sin arrancar código. El dashboard de WaveSpeed hizo eso más fácil de lo que esperaba. Un endpoint, autenticación consistente, y una vista de cuota simple que no me hizo buscar.
Mi flujo fue así:
- Un pequeño preprocesador limpió entradas (minúsculas para jerga, eliminación de espacios en blanco extra, unificación de marcas de tiempo de zona horaria).
- Envié solicitudes al endpoint de Nano Banana Pro con una instrucción de sistema estable y un pequeño conjunto de ejemplos.
- Almacené en caché prompts estables y respuestas comunes. Nada sofisticado, solo un caché TTL local y el almacenamiento en caché de respuesta de WaveSpeed para payloads idénticos.
- Almacené trazas: hash de prompt, parámetros, latencia, recuentos de token, y códigos de error cuando aparecían.
Lo que ayudó más fue la previsibilidad. El endpoint no intentó hacer enrutamiento inteligente en mi nombre. Si pedía Nano Banana Pro, lo obtenía. Durante mis ejecuciones, la latencia mediana rondaba un rango estable, y la varianza no se disparaba durante las horas de trabajo en EE.UU. tanto como esperaba. No perfecto, pero más tranquilo que mi línea de base.
 Si te importa más el enrutamiento estable y el uso transparente que perseguir el elemento de línea más barato, prueba nuestro Wavespeed. Nos enfocamos en endpoints predecibles, autenticación limpia, y visibilidad de uso que no requiere adivinanza.
Si te importa más el enrutamiento estable y el uso transparente que perseguir el elemento de línea más barato, prueba nuestro Wavespeed. Nos enfocamos en endpoints predecibles, autenticación limpia, y visibilidad de uso que no requiere adivinanza.
Una pequeña complejidad: la opción de streaming funcionó, pero en mi uso no redujo la latencia percibida lo suficiente como para importar. Para textos cortos, el streaming se sintió como ceremonia extra. Para resúmenes más largos, fue agradable pero no necesario. Lo dejé apagado para todo excepto sesiones de revisión manual.
Parámetros clave
Intento no ajustar perillas a menos que haya una razón. Un puñado realmente importó aquí.
- Selección de modelo: Nano Banana Pro se mantuvo consistente durante mi período de prueba (a partir de enero de 2026). Sin cambios sorpresa. Esta estabilidad es la razón principal por la que continué.
- Temperatura: Para etiquetado y clasificación, la aparqué cerca de cero. Eso redujo inconsistencia. Para resumir con un poco de síntesis, 0.3–0.4 me dio fraseado más suave sin desviarse del resumen.
- Token máximo: Establecí límites estrictos para tareas cortas para evitar salidas infladas. Para resúmenes largos, di límites generosos y confié en un conteo de caracteres duro en post.
- Instrucción de sistema: Una instrucción corta y clara venció bloques de política largos. Usé una oración para establecer el rol, más una rúbrica diminuta para “no inferir, mostrar evidencia cuando no estés seguro.” Cuanto más agregaba, más se protegía.
- Top-p vs. temperatura: Mantuve top-p fijo en 1.0 mientras ajustaba la temperatura. Mezclar ambos hizo las diferencias más difíciles de rastrear.
Lo que me sorprendió fue cuán sensible era el modelo a la colocación de ejemplos. Dos ejemplos concretos justo después de la instrucción funcionaron mejor que cinco distribuidos. Cuando moví ejemplos al final, la calidad bajó en casos extremos. La API no impuso formato, pero la consistencia se pagó: los mismos nombres de campo, el mismo orden, la misma puntuación.
Perillas de calidad
Más allá de temperatura y límites de token, algunos movimientos cambiaron la sensación de las salidas:
- Los primers cortos vencen las políticas largas. Una intención de una línea + dos ejemplos produjeron menos sobre-explicaciones que una página de orientación.
- Los prompts de evidencia ayudaron. Preguntar “cita la frase que activó esta etiqueta” redujo el etiquetado imaginativo mucho. También hizo que el QA fuera más tranquilo porque podía detectar alucinaciones rápidamente.
- Restricciones suaves > restricciones duras. Decir “apunta a 3–5 viñetas” funcionó mejor que “exactamente 4 viñetas.” El modelo respetó los límites sin volverse nervioso.
- Encuadre determinista: Agregué un poco de estructura al final, “Devuelve: etiqueta, confianza (0–1), evidencia (texto).” Mantuvo las salidas ordenadas sin sentirse como una prisión de esquema.
La calidad bajó en dos casos: entradas OCR desordenadas y jerga de dominio. La solución no era prompting más inteligente. Era solo un paso previo diminuto: recortar caracteres de basura, unificar guiones, y listar términos desconocidos en la parte superior como “términos vistos.” Una vez que hice eso, el modelo dejó de adivinar etiquetas raras. Esto no me ahorró tiempo el primer día, pero en la cuarta ejecución noté que no estaba releyendo tanto. Menos esfuerzo mental cuenta.
Consideraciones de precios
 No perseguí el elemento de línea más bajo. Quería gasto predecible para salida predecible.
No perseguí el elemento de línea más bajo. Quería gasto predecible para salida predecible.
En mis pruebas, Nano Banana Pro aterrizó en el rango medio de costo por mil tokens en WaveSpeed. El beneficio silencioso era un uso de token más consistente. Porque el modelo no divagaba con la forma correcta de prompt, vi menos picos sorpresa. Mi longitud de salida promedio para resúmenes se estabilizó después de agregar la restricción suave de viñetas.
Dos pequeños hábitos redujeron costos sin perjudicar la calidad:
- Almacenamiento en caché de prompt para instrucciones recurrentes y ejemplos (WaveSpeed hizo parte de esto: mi adaptador hizo el resto para que solicitudes idénticas se cortocircuiten).
- Salidas tempranas para casos no-op. Si la entrada es demasiado corta u obviamente irrelevante, omite la llamada y devuelve un valor por defecto. Esto suena obvio, pero tiendo a olvidarlo hasta que veo la factura.
Si estás tratando con cargas de trabajo impredecibles, el modelo de pago por uso tenía sentido para mí. Si tu uso es constante y pesado, podrías mirar créditos comprometidos, pero solo después de un mes de números reales. No me precomprometería basándome en una corazonada.
Consejos por lotes
Ejecuté dos lotes semanales durante la prueba. Algunos patrones ayudaron:
- Tamaño de lote pequeño y estable. Me asentí en fragmentos de 50 elementos. La concurrencia fue modesta (10–12). El rendimiento fue fino, y el manejo de errores se mantuvo cuerdo.
- Presupuesto de reintento con retroceso. Un reintento rápido para problemas transitorios, luego un retroceso más largo, luego aparcar el elemento. Sin bucles infinitos.
- Tokens de idempotencia. Misma entrada, mismo hash, misma clave de solicitud. Si un reintento aterrizaba, no pagaba el doble o no registraba el doble.
- Prevalidación. Rechacé entradas que carecían de campos requeridos antes de enviar algo a la API. Aburrido, pero ahorró tiempo.
La única fricción fue transparencia de límite de velocidad. El dashboard de WaveSpeed mostró el uso claramente, pero los límites por minuto se sentían un poco opacos durante el pico. Lo resolví agregando un guardia de promedio móvil en mi adaptador y tratando 429 como señales, no errores. Después de eso, los lotes se ejecutaron sin drama.
Manejo de errores
Mantuve el manejo de errores simple y observable, siguiendo mejores prácticas de manejo de errores de API REST.
- Tiempos de espera: Establecí un tiempo de espera de cliente conservador. Si una solicitud se ejecutaba larga, la marcaba para un carril de reintento más lento. Las solicitudes largas a menudo se completaban en el reintento: la clave era no obstruir el carril rápido.
- 4xx vs 5xx: 4xx se aparcó para revisión manual a menos que fuera un límite de velocidad. 5xx obtuvo un corto estallido de reintento. Esto evitó quemar ciclos en entradas malas.
- Guardrails en salidas: Pedí al modelo que siempre incluyera una puntuación de confianza. Cuando la puntuación caía por debajo de 0.6, enviaba el elemento a una cola de revisión humana. Triaje simple, menos arrepentimientos.
- Registro: Registré el prompt y la respuesta sin procesar solo para casos marcados, no todo. La privacidad se mantuvo más limpia, y mis registros fueron más pequeños.
Hubo algunos errores de modelo genuinos, etiquetas confiadas pero incorrectas en sarcasmo. No intenté salirme de eso con prompting. Agregué una verificación de sarcasmo como un paso ligero separado y solo entonces apliqué el etiquetador principal. Dos pasos, menos desorden.
Lógica de payload de ejemplo (explicación sin código)
Aquí está la forma de lo que envié, en lenguaje plano.
- Rol de sistema: una oración sobre el trabajo. Por ejemplo, “Eres un clasificador cuidadoso que etiqueta copias de marketing con un pequeño conjunto de etiquetas y señala las palabras que impulsaron la decisión.”
- Contexto: un glosario diminuto para términos extraños, más dos ejemplos nítidos, uno limpio, uno complicado.
- Instrucción: qué devolver y en qué orden (etiqueta, confianza, evidencia), y la restricción de tono (breve, sin lenguaje de cobertura).
- Entrada: el texto sin procesar, sin tocar excepto limpieza de espacios en blanco.
- Límites: una longitud máxima solicitada para la evidencia y un techo en el número de etiquetas.
En el lado del adaptador, generé un hash estable del rol del sistema + ejemplos + instrucción. Si ese hash coincidía con una solicitud anterior con la misma entrada, revisaba el caché. Si no, llamé al endpoint de Nano Banana Pro de WaveSpeed con temperatura y límites de token configurados para la carga de trabajo. Analicé la salida por claves, no por posición, así que pequeños cambios de fraseado no rompieron nada.
 Si la respuesta carecía de cualquier clave requerida, no pedí al modelo que se arreglara en el lugar. Reemití el prompt con un pequeño recordatorio: “Devuelve las tres claves solo.” Un reintento máximo. Después de eso, fue a la cola de revisión. Esto mantuvo el sistema de hacer bucles en disparates.
Si la respuesta carecía de cualquier clave requerida, no pedí al modelo que se arreglara en el lugar. Reemití el prompt con un pequeño recordatorio: “Devuelve las tres claves solo.” Un reintento máximo. Después de eso, fue a la cola de revisión. Esto mantuvo el sistema de hacer bucles en disparates.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes
