Z-Image LoRA: Qué significa y cuándo lo necesitas (Guía para principiantes)

Hola, mis amigos. Soy Dora. No planeaba entrenar nada la semana pasada. Solo quería un pequeño asistente consistente, un personaje ilustrado que se sentara en la esquina de mis capturas de pantalla. Los prompts me mantenían cerca, luego se desviaban. Las cejas cambiaban. Los colores se deslizaban. El martes (13 de enero de 2026), después de algunos casi-aciertos, probé Z-Image LoRA. Esperaba un agujero de conejo. Fue más como un pasillo corto.
Esto no es una vuelta de victoria. No fue instantáneo. Pero la configuración eliminó suficiente fricción que dejé de pensar en parámetros y comencé a pensar en mis imágenes. Aquí está lo que funcionó, lo que no, y cuándo probablemente no necesitas un LoRA en absoluto.
Z-Image LoRA en un minuto
Un LoRA (Low-Rank Adaptation) es un pequeño complemento que entrenas en la parte superior de un modelo de imagen base para empujarlo hacia un estilo o tema específico sin reentrenar todo el modelo.
 Lo que Z-Image LoRA (Amigable para Principiantes) hace bien:
Lo que Z-Image LoRA (Amigable para Principiantes) hace bien:
- Oculta los controles aterradores. Aún eliges algunos conceptos básicos (imágenes, títulos, objetivo), pero los valores predeterminados son sensatos.
- Se entrena lo suficientemente rápido para iterar. Mi primer paso (10 imágenes) tomó aproximadamente 12–18 minutos en una GPU de rango medio.
- Se carga como una capa. Lo activas en tu herramienta de generación y haces prompts normalmente, más una palabra desencadenante opcional.
Lo que obtienes: un archivo pequeño que empuja el modelo cuando necesitas consistencia, logos, un personaje, un aspecto acuarela con pinceladas, sin bloquearte. Si no lo activas, el modelo base se comporta como de costumbre.
Cuándo NO necesitas LoRA
Lo digo con amor: muchos de nosotros recurrimos al entrenamiento demasiado rápido. Algunos casos donde no me molesto:
- El modelo base ya está cerca. Si un prompt corto con una imagen de referencia te da resultados 8/10 que puedes usar, ya está. Un IP-Adapter o prompt de imagen puede ser suficiente.
- Necesitas variación, no consistencia. Si cada salida debe divagar, un LoRA puede sobre-dirigir.
- Visuales puntuales. Para un banner único, pasaré cinco minutos extra en prompts en lugar de configurar el entrenamiento.
- La restricción vive en la composición, no en la identidad. Herramientas como ControlNet o guía de poses moldean el diseño sin enseñar al modelo un concepto nuevo.
Una prueba rápida que uso: si un barrido de semilla simple y 2–3 ajustes de prompt no pueden mantener el elemento que me importa (mismo personaje, mismas proporciones de logo) en cinco imágenes, es cuando considero un LoRA. De lo contrario, lo mantengo simple.
Cuándo ayuda LoRA
Sentí la diferencia más en dos situaciones esta semana (enero de 2026):
- Una pequeña mascota que quería reutilizar en toda la documentación. Los prompts mantenían tambaleando los ojos y el color de la camisa. Después de un LoRA corto, esos se estabilizaron, y pude enfocarme en poses y fondos.
- Una textura de lápiz suave para diagramas. Podría hacer prompt “pencil sketch,” pero el sombreado cambiaba cada vez. Un LoRA de estilo de 15 imágenes me dio una calidad de línea constante sin fijar contenido.
Señales de que un LoRA probablemente ayudará:
- Necesitas el mismo tema en muchas escenas.
- Una textura de arte específica importa (sombreado cruzado, puntos de risógrafo, bordes de gouache gruesos) y sigue desviándose.
- Quieres reducir la gimnasia de prompts. Después del entrenamiento, mis prompts bajaron de 80–100 tokens a 30–40. El esfuerzo mental cayó más que el tiempo.
Lo que me sorprendió fue lo silencioso que se sintió el impacto. Sin antes/después dramático. Solo menos reintentos, menos “casi-aciertos”.
Requisitos de datos
 Mantuve esto simple y funcionó mejor de lo esperado. Algunas notas de dos ejecuciones cortas la semana pasada:
Mantuve esto simple y funcionó mejor de lo esperado. Algunas notas de dos ejecuciones cortas la semana pasada:
Cantidad
- Personaje/tema: 8–20 imágenes pueden ser suficientes si son variadas (ángulos, iluminación, cambios leves de vestuario). Usé 12.
- Estilo/textura: 10–30 imágenes que compartan el mismo aspecto pero contenido diferente. Usé 15.
Calidad
- Resolución: alimenta imágenes que coincidan aproximadamente con tu tamaño de generación. Si planeas generar en 1024, no entrenes con cultivos diminutos de 256.
- La variedad vence al volumen: Cinco copias de la misma pose enseñan al modelo muy poco e lo empujan hacia el sobreajuste.
- Los fondos limpios ayudan para personajes: Las escenas ocupadas desdibujan la señal.
Títulos
- Cortos y literales: “una pequeña mascota azul con ojos redondos, camisa roja,” “pencil sketch, crosshatch, soft shadow.”
- Sé consistente con la nomenclatura. Si inventas un nombre único para un personaje (como “mori-kiko”), úsalo en cada título para poder activarlo más tarde.
- Puedes empezar con títulos automáticos, luego limpiarlos ligeramente. Corté adjetivos que no reflejaban la idea central.
Proceso que usé
- 12 fotos de tema (frente/tres cuartos/perfil), fondos neutrales.
- 15 fotogramas de estilo de mis propios diagramas, misma textura de papel.
- Una pasada, rango predeterminado, regularización ligera. Tiempo de entrenamiento: ~16 minutos en un A10G alquilado. Configuración: ~10 minutos. La segunda ejecución utilizó 20% menos pasos y se mantuvo bien.
Si solo recuerdas una cosa: menos imágenes claras vencen a carpetas grandes y ruidosas.
LoRA de estilo vs. personaje
Solía combinar estos. Se comportan de manera diferente.
LoRA de personaje/tema
- Objetivo: enseñar una identidad específica (una persona, mascota, producto).
- Datos: tema consistente, contextos variados: primeros planos faciales si la identidad facial importa.
- Prompts: mantén el nombre desencadenante más una descripción corta. Deja que el LoRA maneje la identidad: tú diriges pose/escena.
- Riesgos: sobreajuste a atuendos o fondos. Mézclelos.
LoRA de estilo/textura
- Objetivo: enseñar una calidad de superficie (trabajo de línea, paleta, trazo de pincel, grano).
- Datos: muchos temas diferentes, un estilo.
- Prompts: no se necesita nombre desencadenante, pero un marcador simple ayuda (“sketchline style”).
- Riesgos: estilo tragándose contenido. Si todo se convierte en la misma pintura borrosa, reduce la potencia.
Potencia y mezcla
- La mayoría de herramientas exponen un peso de LoRA. Raramente voy por encima de 0.8 para personajes o 0.6 para estilos. Los pequeños empujones importan.
- Puedes apilar dos LoRAs (uno de estilo, uno de personaje). Tuve los mejores resultados cuando uno era dominante y el otro se mantenía por debajo de 0.4.
Aprendí a pensar en LoRA de personaje como “quién” y LoRA de estilo como “cómo”. Simple, pero me impide culpar a la cosa equivocada.
Mitos comunes
Algunos reclamos con los que me encuentro mucho, y lo que realmente vi:
- “Necesitas cientos de imágenes.” Entrené un personaje usable con 12. Más ayuda, pero solo si son variadas y limpias.
- “Toma horas.” Con una GPU modesta y un preset para principiantes, mis ejecuciones aterrizaron bajo 20 minutos. Las configuraciones personalizadas pesadas pueden llevar más tiempo.
- “LoRA reemplaza la ingeniería de prompts.” Reduce el ajuste fino pero no lo elimina. Aún hago prompts para composición, iluminación y estado de ánimo.
- “Un LoRA se ajusta a todos los modelos.” No siempre. Un LoRA entrenado en una base puede transferirse bien a un modelo hermano, pero los resultados cambian. Los trato como relacionados, no intercambiables.
- “Mayor potencia = mejor.” Después de cierto punto, las imágenes colapsan en monotonía. Si los detalles se manchan, baja el peso.
- “Los títulos automáticos están bien sin editar.” Son un buen comienzo. Aún corté adjetivos raros (“ominoso,” “cinemático”) que no eran parte del concepto.
Nada de esto es mágico. Son pequeños ajustes repetibles que se componen.
Glosario rápido
- LoRA: Un conjunto compacto de actualizaciones de peso aprendidas que adapta un modelo grande hacia un concepto objetivo sin reentrenar todo. Según la documentación de LoRA de IBM, puede reducir parámetros entrenables en hasta 10,000 veces en comparación con el ajuste fino completo.
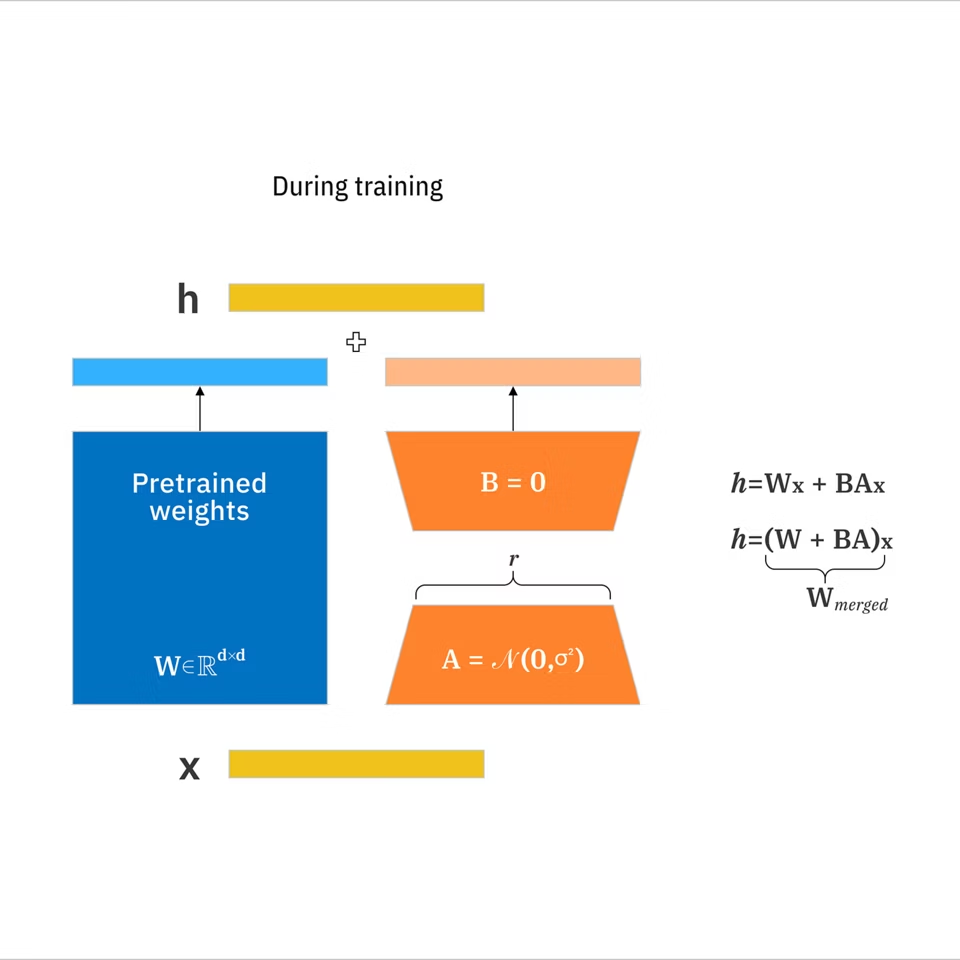
- Modelo base: La fundación desde la que generates (lo que cargas antes de cualquier LoRA).
- Rango (r): Una configuración que controla qué tan expresivo es el LoRA. Un rango más alto puede capturar más matices pero puede sobreajustar e hinchar el tamaño.
- Peso/Potencia: Qué tan fuertemente el LoRA influye en la generación en el tiempo de inferencia.
- Palabra desencadenante: Un token único que usas en prompts para llamar a un LoRA de tema (por ejemplo, el nombre inventado que usaste en títulos).
- Sobreajuste: Cuando el modelo memoriza imágenes de entrenamiento y deja de generalizar. Se muestra como casi-duplicados.
- Regularización: Técnicas o datos adicionales para prevenir el sobreajuste.
- UNet/Codificador de texto: Partes del modelo que manejan imágenes y texto. Algunos entrenamientos actualizan ambos: los presets para principiantes a menudo tocan el lado de imagen más.
- Título: El texto emparejado con cada imagen de entrenamiento.
- Punto de control: Un estado guardado de un modelo o LoRA.
Si alguno de estos se ve borroso, aún puedes entrenar. El preset para principiantes está diseñado para mantenerte fuera de problemas.
Próximos pasos en WaveSpeed
Usé el camino amigable para principiantes en WaveSpeed para ejecutar Z-Image LoRA sin perseguir configuraciones. El flujo fue tranquilo:
- Elige un modelo base.
- Suelta 8–20 imágenes y títulos cortos.
- Elige “estilo” o “personaje.”
- Comienza el entrenamiento y prepara té.
- Carga el LoRA para generación e intenta dos potencias (0.4 y 0.8) para sentir el rango.
Lo que ayudó más fue tratar la primera ejecución como un boceto. Busqué dos cosas: ¿se mantuvo la identidad en cinco prompts, y el estilo mantuvo su textura sin tragarse el contenido? Si uno falló, ajusté el conjunto de datos, no solo los controles.
Si estás tratando con las mismas limitaciones, personajes inestables, texturas errantes, vale la pena echar un vistazo. Esto funcionó para mí: tu kilometraje puede variar.
Es exactamente por eso que construimos WaveSpeed. Cuando los personajes se desplazan, los estilos se tambalean, y los prompts se convierten en gimnasia, queríamos una forma más tranquila de lograr consistencia sin sobre-ingeniería. En WaveSpeed, ejecutamos Z-Image LoRA con un flujo amigable para principiantes—defaults claros, iteración rápida, y el control justo para mantener identidades y texturas estables, para que puedas pasar menos tiempo reintentando y más tiempo realmente haciendo imágenes.
→ Entrena un LoRA simple en WaveSpeed
 Una pequeña nota que estoy guardando para mí: cuantas menos palabras peleo en el prompt, más atención tengo para la imagen frente a mí. Esa es la parte que no quiero automatizar.
Una pequeña nota que estoy guardando para mí: cuantas menos palabras peleo en el prompt, más atención tengo para la imagen frente a mí. Esa es la parte que no quiero automatizar.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa
