Versiones del modelo GPT-5 explicadas: De GPT-5 a GPT-5.4
GPT-5 no es un modelo único. Esta guía explica cada versión GPT-5.x y lo que los desarrolladores deben saber sobre la evolución de esta familia de modelos.

Hola, soy Dora. No planeaba escribir sobre los modelos GPT-5 esta semana. Simplemente me quedé atascada eligiendo una versión en el menú desplegable de modelos otra vez. Una pequeña pausa, luego la pregunta de siempre: ¿el 5.2 realmente ayuda aquí, o estoy haciendo clic en lo más nuevo simplemente porque es más nuevo?
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. GPT-5.5 API → · GPT-5.4 API → · Abrir Playground →
Esa pequeña fricción me llevó por un camino de búsqueda. Pasé algunas noches a finales de febrero y principios de marzo de 2026 repitiendo las mismas tareas en la familia 5.x: un resumen de investigación compacto, una extracción de JSON estructurado y una refactorización simple de código con múltiples archivos. Nada llamativo. Solo el tipo de trabajo que o bien se siente más fácil, o no. Estas son mis notas de campo, no un recorrido triunfal.

Por qué GPT-5 es un sistema, no un modelo único
Sigo viendo a la gente hablar de “el” modelo GPT-5, como si fuera un único cerebro que simplemente se intercambia. Eso no coincide con lo que he observado, ni con lo que OpenAI sugiere en su documentación y charlas públicas.
Descripción general de la arquitectura del enrutador
El comportamiento parece un sistema enrutado: una “puerta de entrada” que decide silenciosamente qué especialista interno maneja qué parte de tu solicitud. Puedes pensarlo como un controlador de tráfico con algunos objetivos en mente: mantener la latencia estable, alcanzar un umbral de calidad y evitar ejecutar especialistas costosos a menos que el prompt realmente los necesite. Por eso el mismo prompt puede sentirse un poco diferente entre los ajustes “rápido” y “predeterminado”, o entre versiones adyacentes: hay más de un modelo en juego.
En la práctica, he visto señales de esto cuando:
- La llamada a herramientas se detecta más rápido en ciertas ejecuciones, como si un planificador hubiera intervenido antes.
- La confiabilidad del modo JSON aumenta después de una actualización del lado del sistema, incluso si los parámetros de la API no cambiaron.
- La latencia se mantiene bajo carga mejor de lo que debería para un único monolito.
No puedo ver detrás del telón, pero los resultados sugieren un enrutador que pondera el costo, la velocidad y el tipo de tarea, y luego elige un camino. Ese marco me ayuda a entender por qué dos etiquetas “GPT-5” pueden comportarse de manera diferente.
Cómo funciona el versionado de OpenAI
OpenAI generalmente lanza familias de modelos con versiones con nombre y compilaciones ocasionales de “vista previa”. Con el tiempo, una versión puede convertirse en la predeterminada y luego quedar obsoleta. Las etiquetas pueden moverse más rápido de lo que las publicaciones de blog pueden seguir el ritmo. Cuando no estoy segura, consulto la documentación de modelos de OpenAI y el registro de cambios de la API antes de fijar una versión. También vale la pena revisar la referencia de la API para buscar indicadores pequeños pero importantes (esquema de respuesta, modos JSON, matices de llamada a herramientas) que cambian entre versiones.
Entonces, cuando digo “GPT-5”, me refiero al sistema enrutado expuesto bajo ese nombre de familia. Y cuando digo “5.1” o “5.3”, me refiero a una configuración específica de ese sistema, a menudo con diferentes valores predeterminados, enrutadores ligeramente diferentes y, a veces, nuevas protecciones de seguridad o confiabilidad.
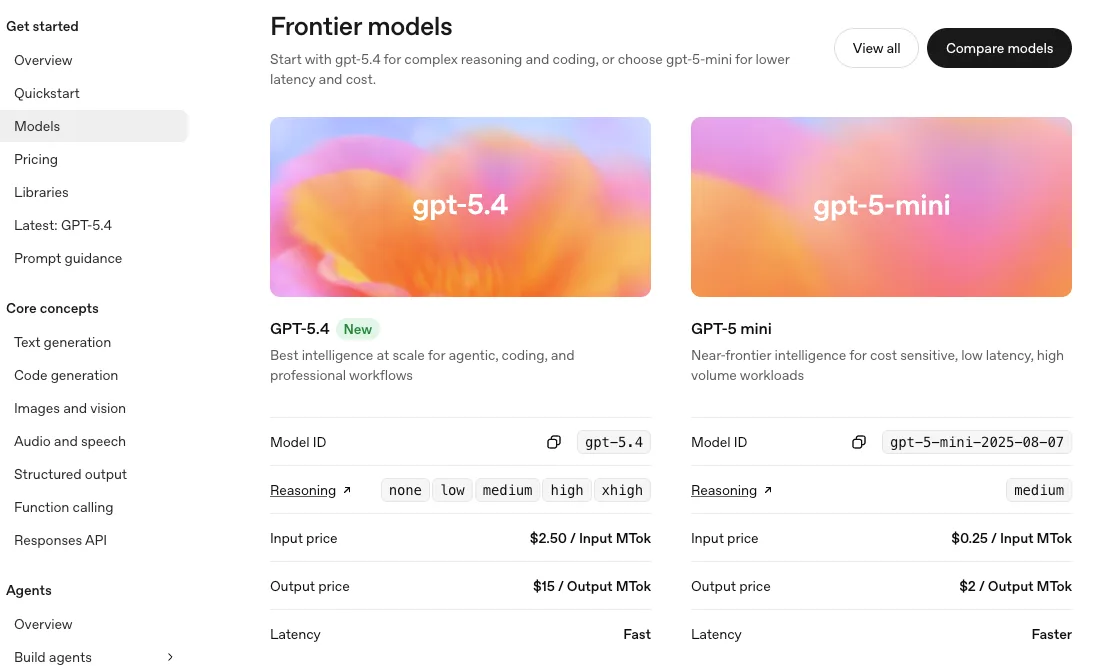
GPT-5 (Base) — Capacidades iniciales
Inicialmente traté el GPT-5 base como un generalista. No porque fuera mágico, sino porque manejaba tres trabajos comunes bastante bien con poca configuración.
Características principales en el lanzamiento
- Claridad de razonamiento: Para tareas de planificación, “redáctame un enfoque de 3 pasos y luego completa el paso 1”, el modelo base se ciñó a la estructura sin que yo tuviera que explicar demasiado. No era ostentoso. Era constante.
- Uso de herramientas sin drama: Las llamadas a funciones funcionaron desde el principio. Cuando le pedí que extrajera campos estructurados, pasaba argumentos consistentes y tipados la mayor parte del tiempo.
- Contexto más largo sin colapsar: Empujé informes largos y referencias de múltiples partes. Se mantuvo suficientemente coherente para ser útil, especialmente cuando lo anclé con encabezados de sección.
- Modo JSON y esquemas de respuesta: Con un esquema simple, podía obtener resultados analizables 8-9 veces de cada 10 en el primer intento. Cuando fallaba, fallaba de forma obvia (objeto truncado), lo cual es una especie de misericordia extraña.
Limitaciones iniciales
- El determinismo sigue siendo blando: Incluso con temperatura baja, las ejecuciones repetidas variaban la formulación y, a veces, el orden. Para producción, tuve que añadir un post-procesamiento ligero (ordenar claves, normalizar espacios en blanco) para mantener las diferencias tranquilas.
- Memoria de llamadas a herramientas: Si encadenaba herramientas, el modelo a veces “olvidaba” las restricciones de límite de una herramienta anterior a menos que las reiterara. Una pequeña molestia, pero real.
- Picos de latencia: La mayoría de las llamadas estaban bien. Luego una o dos tardaban notablemente más. No minutos, solo lo suficiente para arruinar un bucle ajustado.
- Conciencia de costos: El modelo base no era el más barato, por lo que los prompts largos descuidados se sentían costosos. Recorté los mensajes del sistema y moví el texto repetitivo a plantillas de código. Un paso simple, un ahorro significativo.
GPT-5.1 a GPT-5.3 — Cambios incrementales
Estas versiones de punto no cambiaron el carácter de los modelos GPT-5. Ajustaron tornillos.
Mejoras versión por versión
- 5.1: El seguimiento de instrucciones se volvió más preciso. Cuando pedí “solo viñetas, sin introducción”, lo escuchó con más frecuencia. La conformidad con JSON también aumentó un poco.
- 5.2: Mejor fundamentación en citas. Cuando proporcioné pasajes y pedí resúmenes respaldados por citas, se ancló de forma más limpia al texto citado. Las alucinaciones disminuyeron, no a cero, pero lo suficiente como para notarlo.
- 5.3: Las llamadas a herramientas se sintieron más confiables bajo carga. Menos formas de argumentos extrañas. También vi primeros tokens ligeramente más rápidos en mis registros, aunque esto podría ser el enrutador haciendo una clasificación inteligente en lugar del modelo en sí.
Todo esto apareció de maneras silenciosas: menos reintentos, menos limpieza, menos ayuda manual en los prompts.
Diferencias orientadas al desarrollador
- Esquemas de respuesta: Las versiones más nuevas eran más exigentes de una buena manera. Cuando declaré un esquema, o lo seguían o fallaban rápidamente. Eso me ahorró más tiempo que cualquier mejora de “inteligencia”.
- Deltas de streaming: El flujo de tokens llegaba en fragmentos más estables. Más fácil de construir interfaces de usuario que no parpadeen.
- Tolerancia de firma de herramientas: 5.2 y 5.3 manejaban tipos estrictos sin improvisar. Si un campo era un enum, dejaba de inventar nuevos valores con tanta frecuencia. Eso redujo el código de protección.
Estos son pequeños, pero eliminan molestias menores. Si mantienes agentes, lo pequeño es grande a lo largo de muchas llamadas.
Lo que se mantuvo igual
- Realidades de la longitud del contexto: Alimentar contexto enorme sigue penalizando la latencia y el costo. Recortar e indexar sigue ganando.
- Deriva de estilo: Incluso con ejemplos, el tono vagaba un poco en resultados más largos. Mantengo fragmentos de referencia y le pido al modelo que los emule; funciona mejor que los adjetivos.
- El “genio de un solo intento” es raro: Los mejores resultados siguen viniendo de un andamiaje constante, objetivos claros, pasos pequeños y retroalimentación. El modelo mejoró, pero el diseño de mi sistema importó más.
GPT-5.4 — Lo que las filtraciones sugieren actualmente
No tengo acceso al 5.4 mientras escribo esto. Me baso en migajas de pan públicas, charlas de desarrolladores, un par de referencias de SDK que la gente detectó y el patrón general de cómo evolucionan estas familias. Trátalo como direccional, no definitivo. Si estás cerca de una ventana de lanzamiento, verifica la documentación del modelo y las notas de versión recientes.
Referencias al modo rápido
Hay conversación constante sobre un camino de enrutamiento “rápido” o “turbo” en el 5.4. Mi suposición: un perfil de latencia primero que relaja algunas protecciones de calidad, similar en espíritu a los niveles de velocidad que hemos visto en familias pasadas. Si eso llega, esperaría:
- Tiempo de primer token más ágil.
- Varianza ligeramente mayor en el formato exacto a menos que uses esquemas estrictos.
- Mejor comportamiento de concurrencia para interfaces de usuario de chat y agentes en vivo.
Si te importa más la velocidad percibida que la formulación perfecta, este podría ser el predeterminado.
Señales de manejo de visión
Algunas pistas apuntan a una comprensión de imágenes más sólida y OCR más robusto en entradas desordenadas (resplandor, recibos sesgados, capturas de pantalla de código). También esperaría respuestas más estables en gráficos y tablas, especialmente si proporcionas un esquema objetivo. La conclusión práctica: menos preprocesamiento manual. Hoy a menudo recorto o mejoro las imágenes antes de enviarlas. Si el 5.4 puede absorber más ese caos, un paso entero desaparece.
Mejoras en el flujo de trabajo de codificación
La conversación aquí se centra en la planificación y las ediciones de múltiples archivos. Si es cierto, el 5.4 podría:
- Proponer planes de pasos más claros antes de tocar el código.
- Mantener las firmas de funciones consistentes entre archivos.
- Reducir los errores de desfase por uno y las rutas de importación incorrectas.
Incluso una pequeña mejora en la confiabilidad importa. En mis pruebas con versiones anteriores, el 70-80% del “tiempo perdido” no era lógica, sino limpiar ediciones seguras pero ligeramente incorrectas. Si el 5.4 recorta eso en un 10-15%, se sentirá como más que una versión incremental.

Cómo los desarrolladores eligen entre las versiones GPT-5.x
No elijo una versión porque un blog me lo dijo. Ejecuto pruebas pequeñas y aburridas. Este es el marco que me ha funcionado.
Mapeo de casos de uso
- Redacción de contenido con control de tono: Me inclino por lo más nuevo (5.2/5.3) porque la adherencia al estilo mejoró ligeramente. Mantengo una pequeña biblioteca de ejemplos de tono y los señalo.
- Extracción estructurada: Gana la versión que me da la mayor adherencia al esquema. Últimamente ha sido 5.2 o 5.3 con esquemas de respuesta explícitos. Aún añado un validador y un reintento.
- Agentes y flujos de trabajo de herramientas: El 5.3 ha sido el más estable en los argumentos de función. Si el modo rápido del 5.4 es real, lo haré A/B para agentes en vivo que necesiten un intercambio rápido más que prosa perfecta.
- Asistencia con código: Empiezo con un contexto corto y primero pido un plan. Si el modelo no puede escribir un plan creíble, no escribirá diferencias limpias. Las versiones 5.x adyacentes difieren lo suficiente aquí como para importar; prueba en tu repositorio, no en un archivo de juguete.
Rastro tres números para cada caso de uso: tasa de éxito en el primer intento, latencia promedio y el porcentaje de llamadas que necesitan limpieza humana. Si una versión más nueva no mueve al menos uno de esos en la dirección correcta, no cambio.
Compensaciones de costo frente a capacidad
Los precios de OpenAI cambian, y no voy a adivinar números aquí. Sin embargo, el patrón es estable:
- Los modelos más nuevos no siempre son más caros, pero pueden serlo. Presupuesto por tokens, no por intuición.
- Los prompts largos aumentan el costo. Elimino el texto estándar, comprimo los ejemplos y hago referencia a IDs externos donde puedo.
- Si procesas trabajo en lotes (resúmenes, extracciones), la versión confiable más barata generalmente gana. Si estás de cara al usuario, la velocidad percibida a menudo importa más que el costo puro.
Dos consejos prácticos que me ahorraron dinero y tiempo:
- Conjuntos dorados: Mantén 20-50 prompts reales con resultados conocidos y buenos. Vuelve a ejecutarlos cuando consideres un cambio. Sin memoria, solo comparaciones limpias. Verás las compensaciones rápidamente.
- Protecciones en código, no en prosa: Los esquemas, validadores y pequeños post-procesadores superan a los párrafos de instrucciones.
Política de actualización de página (mantenida continuamente)
Actualizo esta página cuando veo cambios significativos en los modelos GPT-5, generalmente después de volver a ejecutar mi conjunto de pruebas o cuando la documentación de OpenAI cambia. Añado una nota breve con una fecha, lo que probé y lo que cambió (si acaso). Enlazo a fuentes oficiales donde puedo y señalo la incertidumbre cuando no puedo verificar algo.
Si lidias con restricciones similares, vale la pena echarle un vistazo de vez en cuando, pero no me esperes. La documentación del modelo es la fuente de verdad. Mantengo mis notas constantes, no exhaustivas.
Una pequeña observación para terminar: cuanto más trato “GPT-5” como un sistema vivo en lugar de un único interruptor, más tranquilas se vuelven mis decisiones. El menú desplegable deja de sentirse como una prueba. Es solo un dial que giro con una razón.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber