DeepSeek V4 vs Claude Opus 4.5 para Programación: Comparación de Benchmarks

¡Hola a todos! Soy Dora. El domingo pasado por la mañana, estaba saltando entre mi editor y una ventana de chat para parchar una prueba inestable, y el modelo seguía inventando una importación que no existía. No es gran cosa, solo una de esas molestias que ralentizan tu trabajo. Quería ver si cambiar de modelo aliviaría la carga, no solo en tiempo de reloj de pared, sino en el esfuerzo mental que requiere confiar en lo que llega a mi repositorio.
Así que pasé la última semana (27 de enero - 1 de febrero de 2026) ejecutando un bucle simple y repetible: mismas tareas, mismas instantáneas del repositorio, alternando DeepSeek V4 y Claude Opus 4.5. Esto no es un estudio de laboratorio. Es el tipo de verificación que haría antes de conectar un modelo a CI. Si también estás sopesando DeepSeek V4 frente a Claude Opus 4.5 para codificación, estas son las notas que me gustaría leer antes de hacer el cambio.

Líderes de Benchmark Actuales
Rankings Verificados de SWE-bench
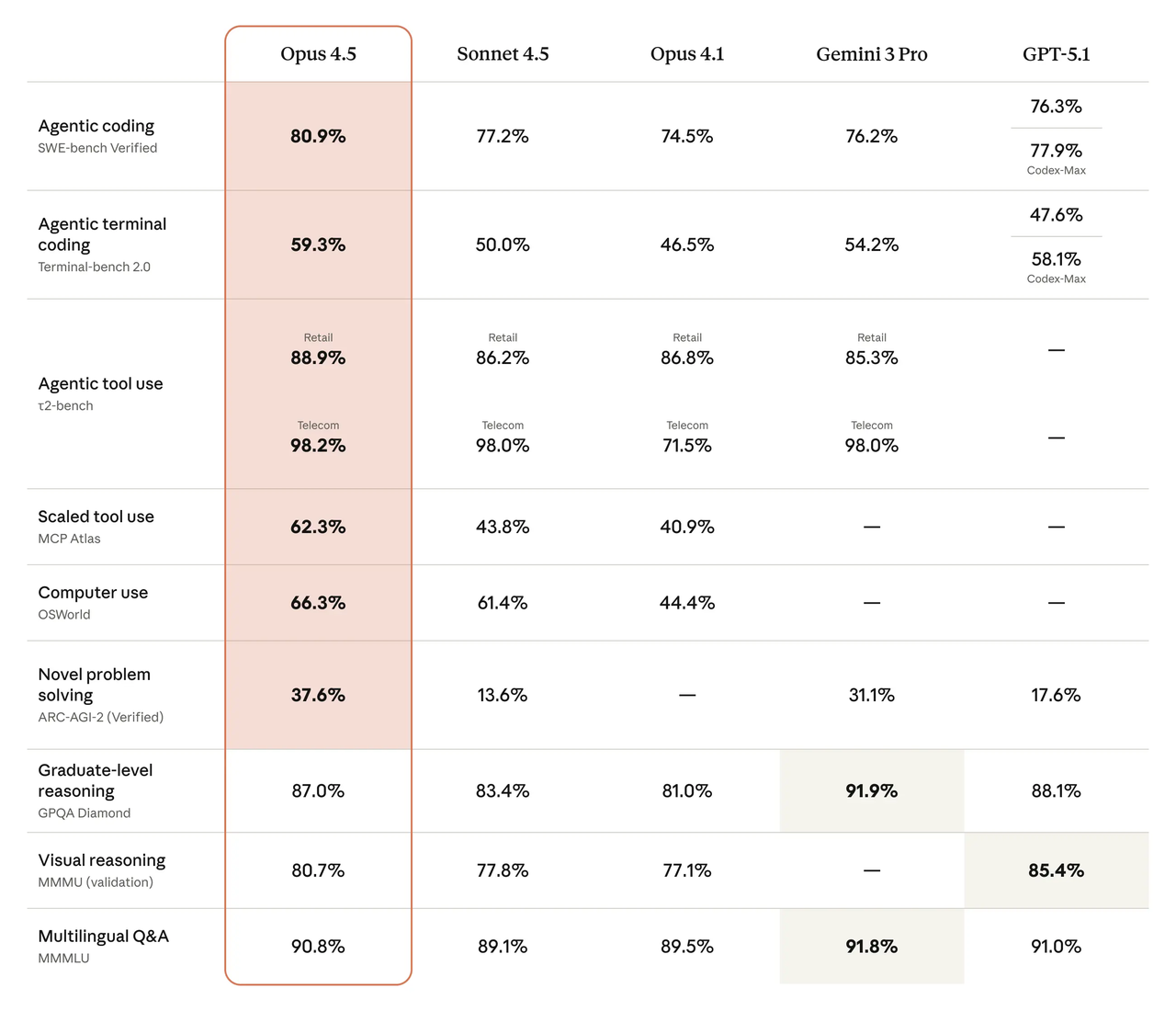
Cuando necesito un sentido rápido de hacia dónde sopla el viento, comienzo con tableros públicos. En el tablero de SWE-bench Verified, los modelos recientes de DeepSeek y la familia Claude más nueva de Anthropic se sientan cerca de la cima, con brechas pequeñas que cambian semana a semana a medida que los prompts, herramientas y arneses de evaluación se desplazan. Lo que me importa no es el número único, es el patrón: cuáles son los modelos que resuelven problemas de extremo a extremo de manera consistente sin muletas de herramientas, y qué tan sensibles son a los ajustes de prompts.
Mi lectura rápida, a principios de febrero de 2026:
- DeepSeek V4 muestra un movimiento fuerte en tareas de escala de repositorio multiarchi cuando le das todo el contexto que solicita. Se beneficia de prompts largos y mapas de archivos explícitos.
- Claude Opus 4.5 produce resultados constantes y tiende a retroceder menos cuando reduzco el contexto o elimino mensajes del sistema. No es llamativo, pero el piso se siente alto.
Puntuaciones HumanEval
HumanEval es más estrecho, problemas de codificación cortos con pruebas unitarias, pero es una prueba de olor útil para la generación de código lista para usar. Los resúmenes actuales en el repositorio oficial de HumanEval y rastreadores comunitarios como el tablero de clasificación de EvalPlus colocan ambos modelos en el nivel superior. No anclo en la pass@1 exacta aquí: observo la estabilidad entre semillas y con qué frecuencia un modelo se apoya en trucos del lenguaje en lugar de escribir código directo e idiomático.
 En mis ejecuciones, DeepSeek V4 a veces produjo soluciones más largas y más “explicativas”, está bien, pero no siempre es lo que quiero en un diff ajustado. Claude Opus 4.5 más a menudo devolvió funciones compactas que pasaron las pruebas sin comentarios adicionales. Los benchmarks insinúan esta diferencia: el trabajo práctico lo hizo obvio.
En mis ejecuciones, DeepSeek V4 a veces produjo soluciones más largas y más “explicativas”, está bien, pero no siempre es lo que quiero en un diff ajustado. Claude Opus 4.5 más a menudo devolvió funciones compactas que pasaron las pruebas sin comentarios adicionales. Los benchmarks insinúan esta diferencia: el trabajo práctico lo hizo obvio.
Dónde Destaca Cada Modelo
Contexto Largo (DeepSeek)
Si quieres reproducir esta configuración de principio a fin, preparé una guía de inicio rápido corta sobre DeepSeek V4 que recorre los conceptos básicos de chat y API en los que me estoy basando aquí.
Le di a ambos modelos una tarea real: refactorizar un pequeño servicio FastAPI que había crecido silenciosamente en un enredo. Aproximadamente 14 archivos importaban, además de un README que era… optimista. Comprimí la instantánea del repositorio y proporcioné resúmenes de archivos junto con un gráfico de llamadas que generé con un script rápido. DeepSeek V4 se sintió tranquilo con la propagación. Realizó un seguimiento de los efectos entre archivos y no entró en pánico cuando le pedí un plan por etapas: interfaces primero, pruebas segundo, controladores último. La parte sorprendente fue lo bien que utilizó las sugerencias estructurales, cuando le entregué un simple “mapa” de nombres de archivos y responsabilidades, dejó de sugerir ediciones a archivos que no existían.
Dos notas prácticas:
- Necesitaba espacio para respirar. Cuando recorté el contexto demasiado agresivamente, se volvió cauteloso y comenzó a pedir que viera archivos que ya había proporcionado. Una vez que le di la imagen completa, se movió limpiamente.
- Manejó bien los prompts “¿Qué me falta?”. Preguntaría por casos límite según el conjunto de pruebas y surgieron tres que había olvidado: encabezados de autorización vacíos, un parámetro de paginación roto y una ruta lenta en el registro de errores.
Esto no ahorró tiempo al principio. La configuración inicial, el empaquetamiento de contexto, la escritura de un mapa de archivos corto, tomaron tal vez 20 minutos. Pero después de algunos ejecuciones, la carga mental bajó. No estaba haciendo malabarismo con tantas preocupaciones de “¿le dije X?”. Si tu día de codificación se parece a diffs grandes distribuidos entre múltiples módulos, DeepSeek V4 tiene una mano firme cuando el contexto se vuelve amplio.
Confiabilidad del Código (Claude)
 Claude Opus 4.5 me ganó de una manera diferente: menos bordes afilados. Cuando le pedí un parche mínimo, me lo dio. Cuando le pedí un plan de tres pasos con una ejecución seca, no alucina comandos. Y resistió la tentación de “mejorar” cosas que no pedí.
Claude Opus 4.5 me ganó de una manera diferente: menos bordes afilados. Cuando le pedí un parche mínimo, me lo dio. Cuando le pedí un plan de tres pasos con una ejecución seca, no alucina comandos. Y resistió la tentación de “mejorar” cosas que no pedí.
Un pequeño ejemplo: tenía una prueba inestable alrededor de matemáticas de zona horaria. Mi prompt fue contundente: “Arregle la prueba sin cambiar el código de producción, y explique la causa raíz en una oración”. Claude sugirió parametrizar la fixture tz y ajustar una única afirmación para usar un datetime consciente. Pasó en el primer intento. DeepSeek también lo arregló, pero intentó refactorizar el ayudante en el mismo aliento. No está mal, solo más pesado de lo que quería.
En cinco tareas, los diffs de Claude fueron consistentemente más pequeños. Menos importaciones aparecieron de la nada. Y cuando adivinó, dejó una nota ordenada: “Suponiendo que pytz esté disponible: si no, reemplácelo con zoneinfo”. Ese tipo de sugerencia prudente es fácil de auditar.
Dos límites se presentaron:
- Claude jugó seguro en el rendimiento. En un caso, eligió claridad sobre una mejora simple O(n) que DeepSeek señaló inmediatamente. Tuve que empujarlo: “Optimiza bajo las mismas restricciones”. Lo hizo, pero no saltaría primero.
- Con prompts muy largos, alcancé el límite más rápido. Los resúmenes ayudaron, pero DeepSeek se sintió menos constreñido cuando quería que el modelo “sostuviera toda la aplicación en su cabeza”.
Si tu día es principalmente parches quirúrgicos, reparaciones de pruebas y código de pegamento alrededor de APIs, Claude Opus 4.5 mantiene los cambios esbeltos y predecibles. Eso, en la práctica, es una confiabilidad que puedo sentir.
Cómo Ejecutar Tu Propia Comparación
 Si estás dudando sobre DeepSeek V4 frente a Claude Opus 4.5 para codificación, un experimento simple y aburrido te dice más que cualquier tablero de clasificación. Aquí está el bucle que utilicé, personalízalo libremente.
Si estás dudando sobre DeepSeek V4 frente a Claude Opus 4.5 para codificación, un experimento simple y aburrido te dice más que cualquier tablero de clasificación. Aquí está el bucle que utilicé, personalízalo libremente.
1. Elige tareas que reflejen tu semana
- Una tarea de repositorio (refactor o extracción de módulo)
- Una prueba inestable
- Un cambio de integración de API
- Un pequeño ajuste de algoritmo
Mantén cada uno bajo 45 minutos. Establece un límite de tiempo en la interacción, no solo en la generación del modelo.
2. Congela las entradas
- Fija un commit específico. No muevas el objetivo mientras pruebas.
- Decide qué puede ver el modelo: archivos completos versus extractos. Escribe un mapa de archivos corto si estás pasando extractos.
- Utiliza el mismo estilo de prompt del sistema para ambos modelos. Lo mantengo simple: “Eres un asistente de codificación útil. Prefiere diffs mínimos y código ejecutable”.
3. Escribe prompts que puedas reutilizar
- Tarea: “Aquí está el objetivo, restricciones y pruebas”.
- Contexto: lista de archivos o resúmenes, además de peligros conocidos.
- Formato de salida: “Proponga un plan (viñetas), luego el diff, luego una nota de riesgo de una oración”.
4. Captura las mismas señales para ambos
- Intentos hasta pasar las pruebas (1–N)
- Líneas modificadas en el diff (aproximado está bien)
- Notas que tuviste que escribir para el modelo (“Deja de editar X”, “Usa el ayudante existente Y”)
- Tiempo hasta la primera prueba verde
5. Protégete contra fugas
- Deshabilita herramientas a menos que planees comparar el uso de herramientas. Si un modelo ejecuta comandos de shell y el otro no, no estás probando lo mismo.
- Si permites recuperación, apunta ambos a la misma instantánea de documentos.
6. Verifica la cordura con benchmarks, no los adores
- Echa un vistazo a SWE-bench Verified para ver si tus resultados se ven salvajemente fuera. Si lo hacen, verifica tus prompts antes de culpar al modelo.
- Para problemas pequeños, revisa ejemplos de HumanEval en el repositorio oficial o ejecuta algunos localmente. La consistencia en unos pocos seeds es más reveladora que una sola ejecución.
7. Opcional: agrega un pequeño rúbrica
Puntúa 1–5 en:
- Minimalismo de diff (¿tocó solo lo que necesitaba?)
- Disciplina de fixture (pruebas, env, dependencias)
- Comportamiento de recuperación (¿se autocorrige cuando señalas una falta?)
- Calidad de explicación (una o dos oraciones claras, no una entrada de blog)
Lo que observo en la práctica
- ¿Respeta el modelo las restricciones la primera vez?
- Cuando se equivoca, ¿se equivoca de una manera que es fácil de detectar?
- ¿Me siento seguro dejando que proponga un parche mientras cambio de contexto?
Esto funcionó para mí, tu experiencia puede variar. El punto no es coronar un ganador: es ver cuál reduce tu carga cognitiva con tu código, en tu horario.
Artículos relacionados

Seedance 2.0 Próximamente: El Modelo de Video de Próxima Generación de ByteDance con Audio Nativo

Guía Completa de Seedance 2.0: Creación de Vídeo Multimodal

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: La Comparación Definitiva de Generación de Video

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Comparación Completa

Guía Completa de Seedream 5.0-Preview: Generación Inteligente de Imágenes
