Nano Banana Pro API auf WaveSpeed: So rufen Sie es auf + Preisnotizen

Haben Sie sich jemals die Nano Banana Pro API in der WaveSpeed-Dokumentation angesehen und gedacht “Was zum Teufel soll ich denn jetzt tun?” Sie sind nicht allein. Ich bin Dora, habe persönlich Dutzende von APIs getestet und meine faire Quote an nicht dokumentierten Endpoints und überraschenden Abrechnungsemails hinter mir. In diesem Leitfaden zeige ich Ihnen Schritt für Schritt, wie Sie die Nano Banana Pro API sauber aufrufen und Preis-Fallstricke vermeiden, die Ihr Projektbudget überrumpeln können.
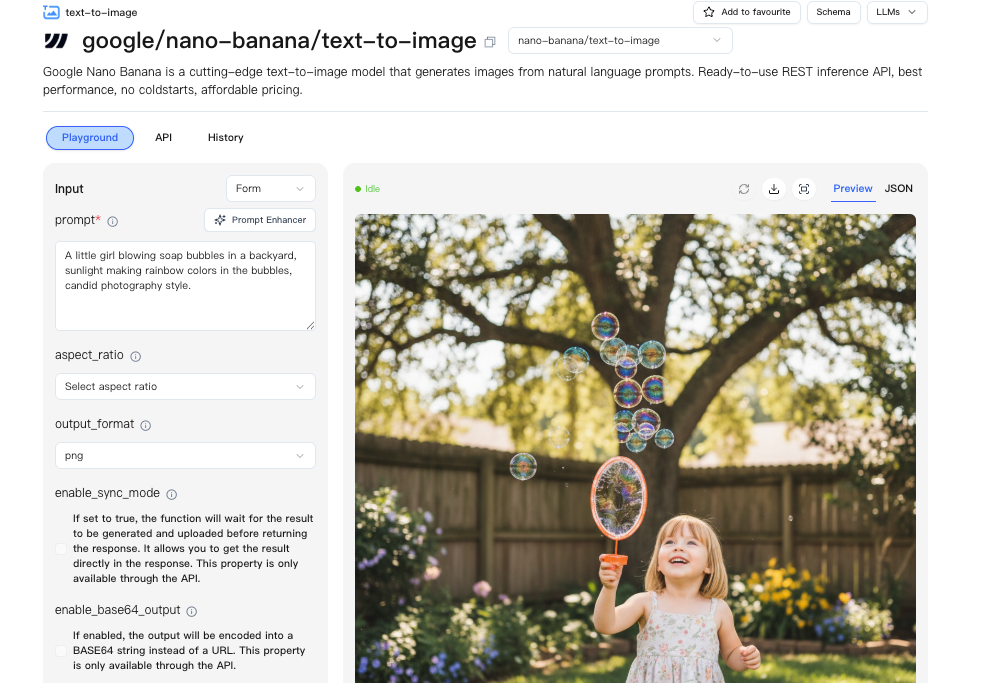
Endpoint / Ablauf
Ich habe meinen gesamten Stack nicht umgestellt. Ich habe Nano Banana Pro hinter einen kleinen Adapter-Service gelegt, um zwischen Anbietern wechseln zu können, ohne Code herauszureißen. Das WaveSpeed-Dashboard hat das einfacher gemacht, als ich erwartet hatte. Ein Endpoint, konsistente Authentifizierung und eine einfache Kontingentansicht, bei der ich nicht herumsuchen musste.
Mein Ablauf sah so aus:
- Ein kleiner Pre-Prozessor bereinigte Eingaben (Fachbegriffe in Kleinbuchstaben, Extra-Leerzeichen entfernen, Zeitstempel vereinheitlichen).
- Ich sendete Anfragen an den Nano Banana Pro Endpoint mit einer stabilen Systeminstruktion und einer kurzen Reihe von Beispielen.
- Ich zwischenspeicherte stabile Prompts und häufige Responses. Nichts Ausgefallenes, nur ein lokaler TTL-Cache und WaveSpeed’s eigenes Response-Caching für identische Payloads.
- Ich speicherte Traces: Prompt-Hash, Parameter, Latenz, Token-Zählungen und Fehlercodes, wenn sie auftauchten.
Das meisten geholfen hat war die Vorhersagbarkeit. Der Endpoint versuchte nicht, auf meine Seite cleveres Routing zu betreiben. Wenn ich Nano Banana Pro anforderte, bekam ich es. Während meiner Durchläufe lag die mittlere Latenz in einem stabilen Bereich, und die Variation spitzte sich während der US-Arbeitszeiten nicht so sehr zu, wie ich erwartet hatte. Nicht perfekt, aber ruhiger als mein Baseline.

Wenn Ihnen stabiles Routing und transparente Nutzung wichtiger sind als die Jagd nach dem billigsten Posten, versuchen Sie Wavespeed. Wir konzentrieren uns auf vorhersagbare Endpoints, saubere Authentifizierung und Nutzungstransparenz, die keine Raterei erfordert.
Eine kleine Besonderheit: Die Streaming-Option funktionierte, aber in meiner Verwendung reduzierte sie die wahrgenommene Latenz nicht genug, um zu zählen. Bei kurzen Texten fühlte sich Streaming wie extra Zeremonie an. Bei längeren Zusammenfassungen war es angenehm, aber nicht notwendig. Ich schaltete es für alles außer manuellen Review-Sitzungen aus.
Wichtige Parameter
Ich versuche, Knöpfe nicht zu drehen, wenn es keinen Grund gibt. Eine Handvoll hat hier tatsächlich eine Rolle gespielt.
- Modellauswahl: Nano Banana Pro blieb über meinen Testzeitraum konsistent (ab Januar 2026). Keine überraschenden Wechsel. Diese Stabilität ist der Hauptgrund, warum ich weitermachte.
- Temperatur: Für Tagging und Klassifizierung parkte ich sie nahe Null. Das reduzierte Inkonsistenz. Für Zusammenfassungen mit etwas Synthese gaben mir 0,3–0,4 glattere Ausdrücke, ohne vom Brief abzuweichen.
- Max Tokens: Ich setzte enge Obergrenzen für kurze Aufgaben, um aufgeblähte Ausgaben zu vermeiden. Bei langen Zusammenfassungen gab ich großzügige Limits und verließ mich auf eine harte Zeichenanzahl in der Nachbearbeitung.
- Systeminstruktion: Eine kurze, schlichte Instruktion schlug lange Richtlinienblöcke. Ich nutzte einen Satz, um die Rolle zu setzen, plus ein winziges Rubrik für “nicht interpretieren, zeige Evidenz bei Unsicherheit.” Je mehr ich hinzufügte, desto mehr zierte es herum.
- Top-p vs. Temperatur: Ich behielt Top-p auf 1,0 während ich die Temperatur nudzte. Das Mischen beider machte Unterschiede schwerer zu verfolgen.
Was mich überraschte, war wie empfindlich das Modell auf Beispielplatzierung reagierte. Zwei konkrete Beispiele direkt nach der Instruktion funktionierten besser als fünf durchmischt. Als ich Beispiele ans Ende verschob, sank die Qualität bei Grenzfällen. Die API erzwang kein Format, aber Konsistenz zahlte sich aus: gleiche Feldnamen, gleiche Reihenfolge, gleiche Zeichensetzung.
Qualitätsknöpfe
Über Temperatur und Token-Caps hinaus veränderten einige Züge das Gefühl der Ausgaben:
- Kurze Primer schlagen lange Richtlinien. Eine Zeile Absicht + zwei Beispiele produzierten weniger Über-Erklärungen als eine Seite Anleitung.
- Evidenz-Prompts halfen. Zu fragen “zitiere den Satz, der dieses Tag ausgelöst hat” reduzierte fantasievolles Tagging erheblich. Es machte QA auch ruhiger, weil ich Halluzinationen schnell erkennen konnte.
- Sanfte Beschränkungen > harte Beschränkungen. “Streben Sie 3–5 Aufzählungspunkte an” funktionierte besser als “genau 4 Aufzählungspunkte.” Das Modell respektierte Grenzen, ohne nervös zu werden.
- Deterministische Rahmen: Ich fügte am Ende ein Hauch Struktur hinzu, “Rückgabe: Label, Vertrauen (0–1), Evidenz (Text).” Es hielt Ausgaben ordentlich, ohne sich wie ein Schema-Gefängnis anzufühlen.
Die Qualität sank in zwei Fällen: unordentliche OCR-Eingaben und Domänen-Slang. Die Reparatur war nicht klügeres Prompting. Es war nur ein winziger Pre-Schritt: Junk-Zeichen trimmen, Bindestriche vereinheitlichen und unbekannte Begriffe oben als “Begriffe gesehen” auflisten. Sobald ich das tat, hörte das Modell auf zu raten. Das sparte mir am ersten Tag keine Zeit, aber beim vierten Durchlauf merkte ich, dass ich nicht mehr so viel neu las. Weniger mentale Anstrengung zählt.
Preisüberlegungen
Ich habe nicht nach dem billigsten Posten gejagt. Ich wollte vorhersagbare Ausgaben für vorhersagbare Ausgaben.
Über meine Tests hinweg landete Nano Banana Pro im mittleren Bereich für Kosten pro tausend Token auf WaveSpeed. Der stille Vorteil war konsistentere Token-Nutzung. Weil das Modell mit der richtigen Prompt-Form nicht redete, sah ich weniger überraschende Spitzen. Meine durchschnittliche Ausgabelänge für Zusammenfassungen stabilisierte sich, nachdem ich die sanfte Aufzählungsbeschränkung hinzufügte.
Zwei kleine Gewohnheiten reduzierten Kosten, ohne Qualität zu beeinträchtigen:
- Prompt-Caching für wiederkehrende Anweisungen und Beispiele (WaveSpeed tat einen Teil davon: mein Adapter tat den Rest, also Short-Circuit gleiche Anfragen).
- Frühe Ausstiege für No-Op-Fälle. Wenn die Eingabe zu kurz oder offensichtlich irrelevant ist, überspringen Sie den Anruf und geben Sie einen Standard zurück. Das klingt offensichtlich, aber ich neige dazu, es zu vergessen, bis ich die Rechnung sehe.
Wenn Sie mit spitzigen Workloads umgehen, machte das Pay-as-you-go-Modell Sinn für mich. Wenn Ihre Nutzung stabil und schwer ist, könnten Sie sich verbindliche Kredite ansehen, aber nur nach einem Monat echter Zahlen. Ich würde nicht auf Verdacht pre-committen.
Batch-Tipps
Ich führte während der Testphase zwei wöchentliche Batches durch. Ein paar Muster halfen:
- Kleine, stabile Batch-Größe. Ich setzte mich auf Chunks von 50 Elementen. Nebenläufigkeit war bescheiden (10–12). Der Durchsatz war gut und die Fehlerbehandlung blieb sinnvoll.
- Wiederhole Budget mit Backoff. Ein schneller Wiederholungsversuch für vorübergehende Probleme, dann ein längeres Backoff, dann Element parken. Keine Endlosschleifen.
- Idempotenz-Token. Gleiche Eingabe, gleicher Hash, gleicher Request-Schlüssel. Wenn ein Wiederholungsversuch landete, zahlte ich nicht doppelt oder loggierte doppelt.
- Pre-Validierung. Ich lehnte Eingaben ab, denen erforderliche Felder fehlten, bevor ich irgendetwas an die API sendete. Langweilig, aber es sparte Zeit.
Die eine Reibung war Ratenlimit-Transparenz. WaveSpeed’s Dashboard zeigte Nutzung klar an, aber pro-Minute Obergrenzen fühlten sich während Peak ein wenig undurchsichtig an. Ich löste es, indem ich einen gleitenden Durchschnitt Guard in meinen Adapter hinzufügte und 429s als Signale, nicht Fehler behandelte. Danach liefen die Batches ohne Drama.
Fehlerbehandlung
Ich hielt die Fehlerbehandlung einfach und beobachtbar und folgte Best Practices für REST API-Fehlerbehandlung.
- Timeouts: Ich setzte einen konservativen Client-Timeout. Wenn eine Anfrage lange lief, markierte ich sie für eine langsamere Wiederholungsspur. Lange Anfragen endeten oft bei Wiederholung: Der Schlüssel war, die schnelle Spur nicht zu verstopfen.
- 4xx vs 5xx: 4xx wurde geparkt für manuelle Überprüfung, wenn es keine Ratenbegrenzung war. 5xx bekam einen kurzen Wiederholungsversuch. Das vermied Zyklen bei schlechten Eingaben zu verbrennen.
- Schutzgitter in Ausgaben: Ich forderte das Modell auf, immer eine Vertrauensscore einzubeziehen. Wenn die Score unter 0,6 sank, sendete ich das Element in eine Warteschlange für menschliche Überprüfung. Einfache Triage, weniger Bedauern.
- Protokollierung: Ich loggerte den rohen Prompt und Response nur für gekennzeichnete Fälle, nicht alles. Datenschutz blieb sauberer und meine Logs waren kleiner.
Es gab ein paar echte Modellfehlgriffe, zuversichtliche, aber falsche Labels auf Sarkasmus. Ich versuchte nicht, mich aus diesem Prompt zu befreien. Ich fügte einen Sarkasmus-Check als separaten leichten Durchlauf hinzu und wendete nur dann den Haupt-Tagger an. Zwei Schritte, weniger Unordnung.
Beispiel-Payload-Logik (nicht-Code-Erklärung)
Hier ist die Form dessen, was ich sendete, in einfacher Sprache.
- Systemrolle: ein Satz zum Job. Zum Beispiel, “Sie sind ein sorgfältiger Klassifizierer, der Marketingkopie mit einem kleinen Satzsatz von Labels kennzeichnet und auf die Wörter hinweist, die die Entscheidung antrieben.”
- Kontext: ein winziges Glossar für seltsame Begriffe, plus zwei knackige Beispiele, eines sauber, eines knifflig.
- Instruktion: was zurückgeben und in welcher Reihenfolge (Label, Vertrauen, Evidenz) und die Tonbeschränkung (kurz, keine Absicherungssprache).
- Eingabe: der Rohtext, unberührt außer Leerzeichen-Cleanup.
- Limits: eine angeforderte maximale Länge für die Evidenz und eine Obergrenze für die Anzahl der Labels.
Auf der Adapter-Seite generierte ich einen stabilen Hash aus der Systemrolle + Beispiele + Instruktion. Wenn dieser Hash eine vorherige Anfrage mit gleicher Eingabe übereinstimmte, prüfte ich den Cache. Wenn nicht, rief ich WaveSpeed’s Nano Banana Pro Endpoint mit Temperatur und Token-Limits auf, die für die Workload gesetzt sind. Ich analysierte die Ausgabe nach Schlüsseln, nicht nach Position, daher brachen kleine Ausdrucksänderungen nichts.
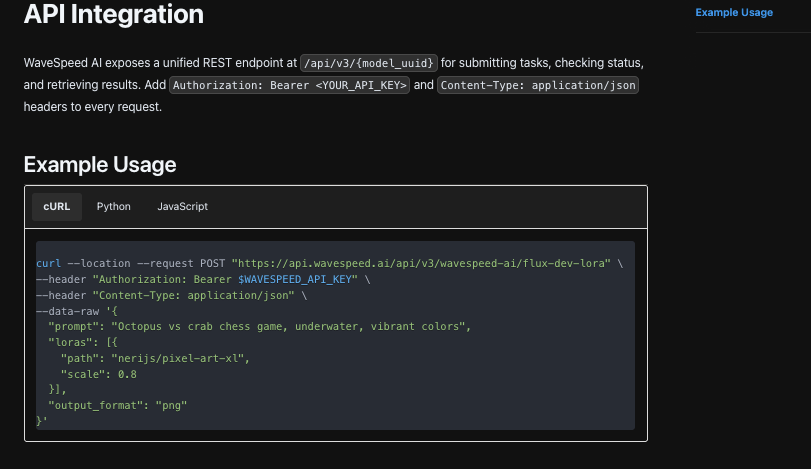
Wenn der Response einen erforderlichen Schlüssel vermisste, fragte ich das Modell nicht, um sich an Ort und Stelle zu korrigieren. Ich gab den Prompt mit einer kurzen Erinnerung aus: “Geben Sie nur die drei Schlüssel zurück.” Eine Wiederholung maximal. Danach ging es in die Überprüfungswarteschlange. Dies hielt das System davon ab, sich selbst in Unsinn zu schleifen.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
