DeepSeek V4 vs Claude Opus 4.5 zum Programmieren: Benchmark-Vergleich

Hallo! Ich bin Dora. Letzten Sonntag morgen bin ich zwischen meinem Editor und einem Chat-Fenster hin und her gehüpft, um einen flaky Test zu beheben, und das Modell erfand ständig einen Import, der nicht existierte. Kein großes Problem, nur eine dieser Kleinigkeiten, die deine Produktivität ausbremsen. Ich wollte sehen, ob ein Modellwechsel die Last reduzieren würde, nicht nur bei der Gesamtlaufzeit, sondern auch beim mentalen Aufwand, um dem zu trauen, was in mein Repository gelangt.
Also habe ich die letzte Woche (27. Jan. – 1. Feb. 2026) eine einfache, reproduzierbare Schleife durchlaufen: gleiche Aufgaben, gleiche Repository-Snapshots, abwechselnd DeepSeek V4 und Claude Opus 4.5. Das ist keine Laborstudie. Es ist die Art von Überprüfung, die ich durchführen würde, bevor ich ein Modell in CI integriere. Falls du auch DeepSeek V4 vs Claude Opus 4.5 für Coding abwägst, sind das die Notizen, die ich vor einem Wechsel lesen würde.

Aktuelle Benchmark-Führende
SWE-bench Verified Rankings
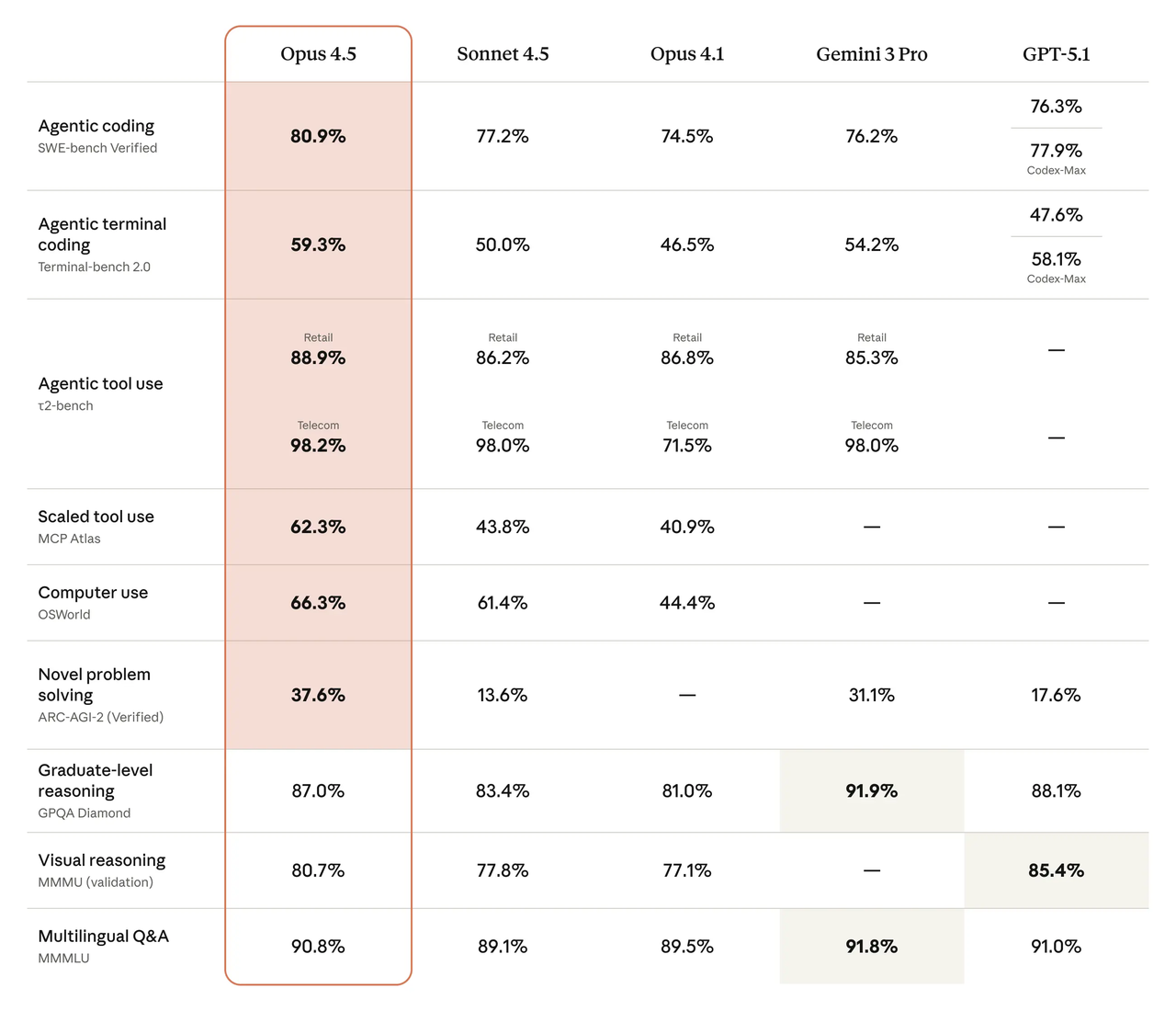
Wenn ich schnell ein Gefühl dafür bekommen will, in welche Richtung der Wind weht, beginne ich mit öffentlichen Leaderboards. Auf der SWE-bench Verified Leaderboard sitzen sowohl DeepSeeks neuere Modelle als auch Anthropics neuere Claude-Familie ganz oben, mit kleinen Lücken, die sich Woche für Woche verschieben, während sich Prompts, Tools und Evaluierungsrahmen ändern. Was für mich zählt, ist nicht die einzelne Zahl, sondern das Muster: Welche Modelle lösen End-to-End-Probleme konsistent ohne Tool-Krücken, und wie sensibel reagieren sie auf Prompt-Anpassungen?
Meine schnelle Einschätzung Anfang Februar 2026:
- DeepSeek V4 zeigt starke Ergebnisse bei mehrdatei-, Repository-übergreifenden Aufgaben, wenn man ihm den gesamten Kontext gibt, den es verlangt. Es profitiert von langen Prompts und expliziten Dateikarten.
- Claude Opus 4.5 liefert stetige Ergebnisse und neigt weniger dazu zu versagen, wenn ich Kontext reduziere oder System Messages streiche. Es ist nicht spektakulär, aber der Basiswert fühlt sich hoch an.
HumanEval Scores
HumanEval ist enger, kurze Coding-Probleme mit Unit Tests, aber es ist ein nützlicher Schnelltest für Out-of-the-Box-Codegenerierung. Aktuelle Zusammenfassungen im OpenAI HumanEval Repo und Community-Trackern wie der EvalPlus Leaderboard platzieren beide Modelle in der Top-Tier. Ich verankere mich nicht an exakten pass@1-Scores hier: Ich achte auf Stabilität über Seeds und wie oft ein Modell auf Sprachtricks anstatt auf direkten, idiomatischen Code setzt.
 Bei meinen Durchläufen produzierte DeepSeek V4 manchmal längere, mehr “erklärende” Lösungen – in Ordnung, aber nicht immer das, was ich in einem knappen Diff will. Claude Opus 4.5 gab öfter kompakte Funktionen zurück, die Tests ohne extra Kommentar bestand. Benchmarks deuten auf diesen Unterschied hin: praktische Arbeit machte es offensichtlich.
Bei meinen Durchläufen produzierte DeepSeek V4 manchmal längere, mehr “erklärende” Lösungen – in Ordnung, aber nicht immer das, was ich in einem knappen Diff will. Claude Opus 4.5 gab öfter kompakte Funktionen zurück, die Tests ohne extra Kommentar bestand. Benchmarks deuten auf diesen Unterschied hin: praktische Arbeit machte es offensichtlich.
Wo jedes Modell hervorragend ist
Langer Kontext (DeepSeek)
Wenn du dieses Setup von Anfang bis Ende reproduzieren möchtest, habe ich einen kurzen DeepSeek V4 Schnelleinstieg-Guide zusammengestellt, der die Chat- und API-Grundlagen durchgeht, auf die ich mich hier verlasse.
Ich gab beiden Modellen eine echte Aufgabe: eine kleine FastAPI-Service refaktorieren, die stillschweigend zu einem Durcheinander geworden war. Etwa 14 Dateien waren relevant, plus eine README, die… optimistisch war. Ich zippte den Repository-Snapshot und fütterte Dateizusammenfassungen zusammen mit einem Call Graph, den ich mit einem schnellen Skript generiert hatte. DeepSeek V4 wirkte ruhig bei der Weitläufigkeit. Es behielt den Überblick über dateiübergreifende Effekte und geriet nicht in Panik, wenn ich nach einem gestaffelten Plan fragte: zuerst Interfaces, dann Tests, zuletzt Handler. Der überraschende Teil war, wie gut es strukturelle Hinweise nutzte – wenn ich ihm eine einfache “Karte” mit Dateinamen und Verantwortlichkeiten gab, hörte es auf, Bearbeitungen an Dateien vorzuschlagen, die nicht existierten.
Zwei praktische Notizen:
- Es brauchte Spielraum. Wenn ich Kontext zu aggressiv kürzte, wurde es vorsichtig und fing an zu fragen, ob ich bereits bereitgestellte Dateien sehen könnte. Sobald ich ihm das vollständige Bild gab, bewegte es sich sauber.
- Es handhabte “Was fehlt mir?” Prompts gut. Ich würde nach Edge Cases auf Basis der Test Suite fragen und es brachte drei an den Tag, die ich vergessen hatte: leere Auth-Header, einen defekten Pagination-Parameter und einen langsamen Pfad im Error Logging.
Das sparte anfangs keine Zeit. Das anfängliche Setup, das Verpacken von Kontext, das Schreiben einer kurzen Dateikarte, dauerte etwa 20 Minuten. Aber nach einigen Durchläufen fiel die mentale Last. Ich jonglierte nicht mehr so viele “habe ich es ihm gesagt?” Sorgen. Wenn dein Coding-Tag wie große Diffs über mehrere Module aussieht, hat DeepSeek V4 eine ruhige Hand, wenn der Kontext breit wird.
Code-Zuverlässigkeit (Claude)
 Claude Opus 4.5 gewann mich auf andere Weise: weniger scharfe Kanten. Wenn ich um einen minimalen Patch bat, gab er mir einen. Wenn ich um einen dreistufigen Plan mit trockenem Durchlauf bat, halluzinierte er keine Befehle. Und er widerstand dem Drang, Dinge zu “verbessern”, die ich nicht verlangt hatte.
Claude Opus 4.5 gewann mich auf andere Weise: weniger scharfe Kanten. Wenn ich um einen minimalen Patch bat, gab er mir einen. Wenn ich um einen dreistufigen Plan mit trockenem Durchlauf bat, halluzinierte er keine Befehle. Und er widerstand dem Drang, Dinge zu “verbessern”, die ich nicht verlangt hatte.
Ein kleines Beispiel: Ich hatte einen flaky Test mit Zeitmathematik. Mein Prompt war direkt: “Behebe den Test, ohne Produktionscode zu ändern, und erkläre die Grundursache in einem Satz.” Claude schlug vor, die tz-Fixture zu parametrisieren und eine einzelne Assertion anzupassen, um ein bewusstes datetime zu verwenden. Es bestand beim ersten Versuch. DeepSeek behob es auch, versuchte aber in der gleichen Aktion, den Helper zu refaktorieren. Nicht falsch, nur schwerer als ich wollte.
Über fünf Aufgaben waren Claudes Diffs konsistent kleiner. Weniger Imports tauchten aus dem Nichts auf. Und wenn es doch riet, ließ es eine saubere Notiz: “Annahme: pytz ist verfügbar; wenn nicht, ersetzen mit zoneinfo.” Diese Art von abgesichertem Vorschlag ist leicht zu überprüfen.
Zwei Grenzen zeigten sich:
- Claude spielte es sicher bei Performance. In einem Fall wählte es Klarheit über eine einfache O(n) Verbesserung, die DeepSeek sofort zeigte. Ich musste es anstoßen: “Optimiere unter den gleichen Bedingungen.” Es tat es, würde aber nicht zuerst springen.
- Bei sehr langen Prompts stieß ich schneller an die Grenze. Zusammenfassungen halfen, aber DeepSeek fühlte sich weniger beengt an, wenn ich wollte, dass das Modell “die ganze App in seinem Kopf hält.”
Wenn dein Tag größtenteils chirurgische Patches, Test-Reparaturen und Leim-Code um APIs ist, hält Claude Opus 4.5 Änderungen schlank und vorhersehbar. Das ist in der Praxis eine Zuverlässigkeit, die ich spüren kann.
Wie man seinen eigenen Vergleich durchführt
 Wenn du zwischen DeepSeek V4 und Claude Opus 4.5 für Coding unschlüssig bist, sagt dir ein kurzes, langweiliges Experiment mehr als jedes Leaderboard. Hier ist die Schleife, die ich verwendet habe, gerne anpassen.
Wenn du zwischen DeepSeek V4 und Claude Opus 4.5 für Coding unschlüssig bist, sagt dir ein kurzes, langweiliges Experiment mehr als jedes Leaderboard. Hier ist die Schleife, die ich verwendet habe, gerne anpassen.
1. Wähle Aufgaben, die deine Woche widerspiegeln
- Eine Repository-Aufgabe (Refactoring oder Modul-Extraktion)
- Ein flaky Test
- Eine API-Integration Änderung
- Eine kleine Algorithmus-Anpassung
Halte jede unter 45 Minuten. Zeitbegrenzung der Interaktion, nicht nur der Generierung des Modells.
2. Eingaben einfrieren
- Fixiere einen bestimmten Commit. Verschiebe das Ziel nicht während du testest.
- Entscheide, was das Modell sehen kann: vollständige Dateien vs. Ausschnitte. Schreibe eine kurze Dateikarte, wenn du Ausschnitte weitergibst.
- Verwende den gleichen System Prompt-Stil für beide Modelle. Ich halte es einfach: “Du bist ein hilfreicher Coding-Assistent. Bevorzuge minimale Diffs und ausführbaren Code.”
3. Schreibe Prompts, die du wiederverwenden kannst
- Aufgabe: “Hier ist das Ziel, die Bedingungen und Tests.”
- Kontext: Dateiliste oder Zusammenfassungen, plus bekannte Fallstricke.
- Ausgabeformat: “Schlag einen Plan vor (Aufzählungszeichen), dann der Diff, dann ein Satz zum Risiko.”
4. Erfasse die gleichen Signale für beide
- Versuche bis zum Bestand Tests (1–N)
- Zeilen geändert im Diff (grob ist in Ordnung)
- Notizen, die du für das Modell schreiben musstest (“Stoppe die Bearbeitung von X”, “Verwende existierenden Helper Y”)
- Zeit bis zum ersten grünen Test
5. Schutz vor Durchsickern
- Deaktiviere Tools, falls du Tool-Nutzung vergleichen planst. Wenn ein Modell Shells aufruft und das andere nicht, testest du nicht das Gleiche.
- Falls du Retrieval erlaubst, zeige beide auf den gleichen Docs-Snapshot.
6. Sanity-Check mit Benchmarks, verehre sie nicht
- Werfe einen Blick auf SWE-bench Verified, um zu sehen, ob deine Ergebnisse wild abweichen. Falls ja, überprüfe deine Prompts, bevor du das Modell beschuldigst.
- Für Kurzbissen-Probleme, überflieg HumanEval Beispiele im offiziellen Repo oder führe ein paar lokal aus. Konsistenz über eine Handvoll Seeds ist aussagekräftiger als ein einzelner Durchlauf.
7. Optional: füge ein winziges Bewertungsschema hinzu
Bewerte 1–5 auf:
- Diff Minimalismus (berührte es nur das Nötigste?)
- Fixture Disziplin (Tests, Umgebung, Abhängigkeiten)
- Recovery-Verhalten (korrigiert es sich selbst, wenn du auf einen Miss hinweist?)
- Erklärungsqualität (ein oder zwei klare Sätze, kein Blog-Beitrag)
Worauf ich in der Praxis achte
- Respektiert das Modell Bedingungen beim ersten Mal?
- Wenn es falsch ist, ist es auf eine Weise falsch, die leicht zu erkennen ist?
- Fühle ich mich sicher, dass es einen Patch vorschlägt, während ich Kontext wechsle?
Das funktionierte für mich, deine Meinung kann abweichen. Der Punkt ist nicht, einen Gewinner zu küren: es ist zu sehen, welcher deine kognitive Reibung mit deinem Code, nach deinem Zeitplan, reduziert.
Verwandte Artikel

Seedance 2.0 kommt bald: ByteDances nächste Generation Video-Modell mit nativer Audioerzeugung

Seedance 2.0 Vollständiger Leitfaden: Multimodale Videoerstellung

Seedance 2.0 vs Kling 3.0 vs Sora 2 vs Veo 3.1: Der ultimative Vergleich der Videogenerierung

Seedream 5.0-Preview Komplettleitfaden: Intelligente Bildgenerierung

Seedream 5.0 vs Nano Banana Pro vs GPT Image 1.5 vs Flux Klein vs Qwen Image: Vollständiger Vergleich
