什麼是 TranslateGemma?開放式 AI 翻譯模型詳解

I’ll translate this article to Traditional Chinese now.
嘿,各位!我是朵拉。那天,我在編輯一份雙語通訊時,在草稿、截圖和谷歌翻譯標籤頁之間不斷切換。沒什麼特別糟糕的。只是…很混亂。你知道那種感覺。我想要一些寧靜的工具,能夠融入我的工作流程,而不是並行運作。
所以在這周早些時候(2026年1月),我試用了TranslateGemma。我起初沒有抱太大期望,又是一個名字閃亮的「開源」模型。但在筆記本裡運行了幾次,然後用在一個小型內部工具上後,我發現了一些微妙的東西:心理負擔降低了。我不再在標籤頁之間摸索。我不再那麼多地為措辭而費心。感覺就像一個翻譯師就在我的書桌上,而不是在房間的另一頭。
TranslateGemma 是什麼
 TranslateGemma 是一系列建立在谷歌Gemma 架構上的開源翻譯模型。簡單地說:這是一組專門為翻譯任務調整的語言模型,具有你實際上可以在本地運行或在雲端擴展的大小規模。
TranslateGemma 是一系列建立在谷歌Gemma 架構上的開源翻譯模型。簡單地說:這是一組專門為翻譯任務調整的語言模型,具有你實際上可以在本地運行或在雲端擴展的大小規模。
在實際使用時,有幾點突出:
- 它是為翻譯而特別調整的。你不必苦苦調教一個通用大型語言模型。提示詞可以保持簡潔。
- 它比簡單的逐句 API 更好地處理上下文。包含習語、產品名稱和輕微語氣線索的段落能以更少的「平坦」部分保留下來。
- 它很平靜。輸出不是炫耀性的,也不是改寫狂。對於工作文件,這是個安慰。
從理論上講,TranslateGemma 介於完全的生成助手和經典的短語翻譯器之間。在實踐中,它是一個既尊重源文意思又能流暢地調整目標語言的翻譯器。當我給它提供了一份混合 UI 標籤和對話句子的簡短發佈說明時,它保持了標籤的完整性,同時還使文案自然易讀。正是這種平衡讓我繼續測試。
授權遵循 Gemma 家族:對許多商業用途有寬鬆授權,但有負責任的人工智慧限制。如果你要將其嵌入產品,請閱讀官方倉庫或 Model Garden 條目中的許可證。這是無聊的部分,但很重要。
模型大小:4B、12B 和 27B
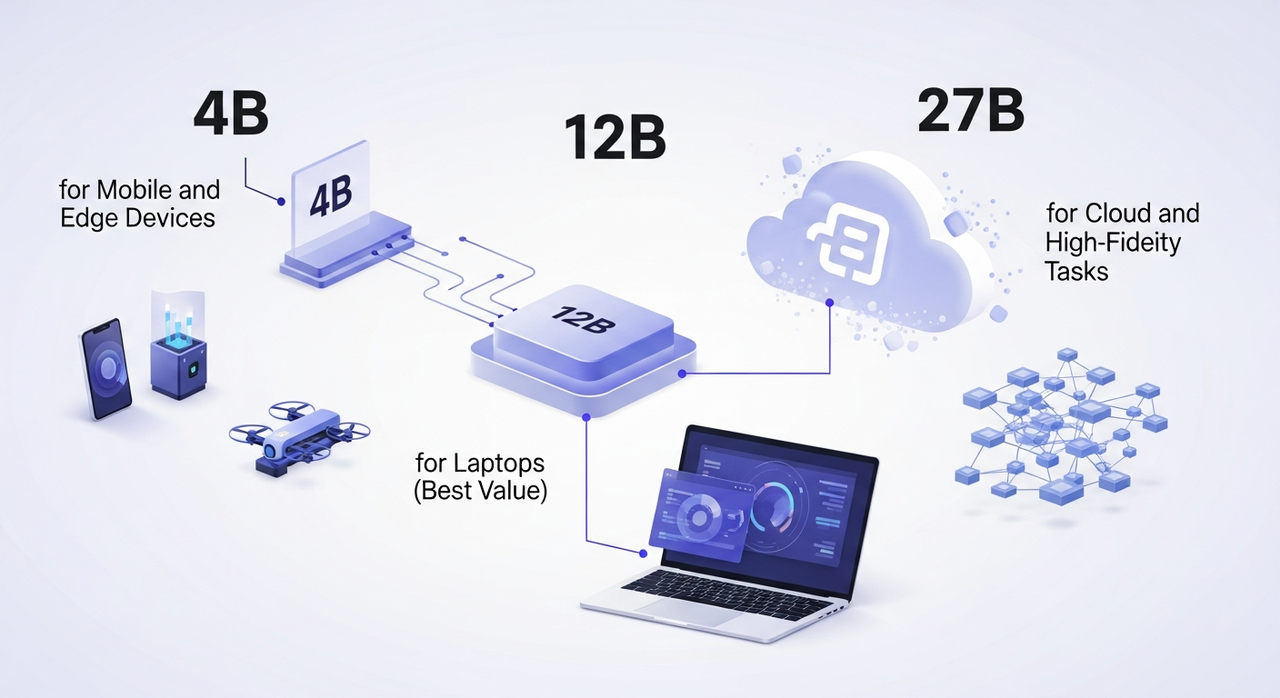 TranslateGemma 有三種大小。同一個家族,不同的權衡。我在兩天內對每一種進行了小型測試,測試了一些產品頁面、一個電子郵件序列和西班牙語、法語和日語的研究摘要。
TranslateGemma 有三種大小。同一個家族,不同的權衡。我在兩天內對每一種進行了小型測試,測試了一些產品頁面、一個電子郵件序列和西班牙語、法語和日語的研究摘要。
4B 用於移動和邊緣設備
我在最新款安卓手機和樹莓派 5 上試了一個 4 位量化的 4B 構建(只是為了看看)。手機上的延遲對於短句子是可以接受的(每行不到一秒),對於直接的文案輸出也是乾淨的:UI 字符串、幫助文本、簡短字幕。任何帶有多層語氣或嵌套句式的內容都開始搖搖欲墜。那時我知道該停止推進了。
有效的方面:
- 在設備上翻譯應用程序字符串,無需向伺服器發送數據。
- 用第二種語言為社交媒體字幕快速制定草稿。
我遇到的限制:
- 較長段落變得僵硬。它保留意思,失去了靈感。
- 代碼混合文本(英文 + 第二語言)有時過度規範化。
如果你需要邊緣設備、亭子、離線應用、隱私敏感工作流的翻譯,4B 是適合放在口袋裡的小工具。對於日常寫作,我會把它當作初稿,而不是最終稿。
12B 用於筆記本電腦(最佳價值)
這是我不斷回到的那款。在我的筆記本電腦上(32GB 記憶體、消費級 GPU),12B 模型以 4–8 位運行,段落級提示詞運行順暢。平均延遲:幾句話 1–2 秒,一個密集段落可能 5–8 秒。這在「不打斷思考」的範圍內。
品質感覺平衡:比 4B 不那麼字面意思,比更大的喜歡改寫的大型語言模型不那麼華麗。當我把一個小案例研究從法語翻譯成英語時,它保留了結構並反映了句子強調,而沒有把一切混為一談。名稱、產品術語和引用保持原位。
它的亮點:
- 需要語氣但不需要詩意的行銷電子郵件。
- 文件、發佈說明和 UX 文案,其中清晰度勝於華麗。
- 筆記本電腦上的批處理:一次 50–200 個段落,無需雲端賬單。
我仍然調整的地方:
- 詩歌相鄰的句子(標語、口號)有時讀起來很安全。快速檢查就能解決。
- 高度技術性的論文可能變得字面。在提示詞中加入「保持正式學術風格」有幫助。
27B 用於雲端和高保真度任務
我在雲端的單個 A100 上部署了 27B 模型。這是對細微差別有要求且能證明基礎設施成本的團隊的選項。交互式使用的延遲很好,但顯然不適合移動設備。
我注意到的:
- 它在較長章節中保持了文體線索。在日語到英語的法律文本中,它保持了正式性,而沒有聽起來冗長。
- 它更好地處理了不明確的代詞。跨段落的參照物不匹配更少。
- 對於低資源語言對,它沒有創造奇蹟,但失敗更優雅,幻覺術語更少。
老實說,如果你正在翻譯長篇內容以供發佈,或者你需要在數千個段落中保持一致性,27B 值得投入。對於小團隊,我只會在語調保真度不可商量或需要大規模標準化結果時才使用它。
TranslateGemma vs 谷歌翻譯
 我不急著用它來取代谷歌翻譯。它很快,隨處可得,對於快速查找,它仍然是從「這是什麼意思?」到「我明白了」的最快途徑。但權衡是不同的。
我不急著用它來取代谷歌翻譯。它很快,隨處可得,對於快速查找,它仍然是從「這是什麼意思?」到「我明白了」的最快途徑。但權衡是不同的。
在我的測試中,TranslateGemma 感覺更好的地方:
- 上下文窗口:我可以放入整個段落或兩個,並保持語氣和參考文獻完整。谷歌翻譯通常能準確把握意思,但當上下文混亂時會淡化風格。
- 自訂:「保留產品名稱,保持縮寫」之類的單行指令能可靠地塑造輸出。使用谷歌翻譯,你得到的就是你得到的。
- 隱私/控制:在本地運行(4B/12B)或在私有雲中減少數據洩露。如果你不想要,就沒有標籤跳轉,沒有外部呼叫。
谷歌翻譯仍然贏得的地方:
- 廣度和便利性:100+ 語言、即時網絡訪問、OCR、移動攝像頭輸入。這是實用刀。
- 大規模隨意使用的速度:如果我只需要一句快速翻譯,TranslateGemma 除非已經烘焙到我的編輯器中,否則就過度了。
- 低摩擦協作:很容易把谷歌翻譯頁面的連結給某人,說「這接近嗎?」
從成本來看,TranslateGemma 將支出從按請求 API 費用轉移到計算成本。如果你已經有不錯的 GPU 或適度的雲端設置,對於持續使用,它可能更便宜。如果你沒有,谷歌翻譯的免費級別很難反駁。
品質比我預期的要接近。TranslateGemma 以好的方式不那麼字面意思,謙虛,不炫耀。谷歌翻譯在語氣處理上有所改進,但聽起來仍然像一本去過完成學校的字典。如果你為人們寫作,這種差距很重要。
一周後我的經驗之談:我仍然用谷歌翻譯來理性檢查我幾乎不懂的語言中的一行。當我關心它聽起來如何而不只是它說什麼時,我會使用 TranslateGemma。
一旦我決定 TranslateGemma 是合適的選擇,下一個問題就是在實際運行它的地方,而不會把設置變成自己的項目。
這正是我們構建WaveSpeed的原因。我們的團隊用它來啟動乾淨的 GPU 環境、運行批量翻譯任務,然後繼續前進——而無需監督驅動程序、隊列或臨時指令碼。
在哪裡獲得 TranslateGemma
我從常見的地方提取了模型:
- Hugging Face:使用 Transformers 或文本生成推理進行快速測試最簡單。搜索「TranslateGemma」並檢查卡片以了解許可證和量化變體。
- 谷歌的 Model Garden(Vertex AI):託管部署、自動擴展、私有端點。如果你的團隊已經在 GCP 中,這是最順暢的途徑。
- Kaggle Models:如果你還不想連接基礎設施,方便進行一鍵筆記本和快速基準測試。
- GitHub + Colab:社區支架快速彈出,加載程序、提示詞範本和基本評估指令碼。
我運行中的設置說明:
- 量化有幫助。4–8 位使 12B 模型在消費級 GPU 上舒適,而不會損害輸出。我沒有想念額外的位。
- 提示詞保持簡短。「翻譯成英語。保留產品名稱。保持縮寫。」大多數時候這就夠了。
- 小心批處理。按段落或項目符號組分塊。逐句進行有效,但你會失去語氣膠水。
如果你需要護欄或詞彙表控制,分層一個輕前/後處理步驟:
- 預先用標籤標記產品名稱(例如),並要求模型保留它們。
- 後期檢查配合詞彙表匹配器以捕捉「Sign in」對「Log in」等術語的漂移。
我認為會喜歡 TranslateGemma 的人
- 想要本地、不錯品質草稿而不切換工具的作家和行銷人員。
- 在應用中靜靜地添加翻譯的產品團隊,而不是外包給又一項服務。
- 關心長段落和參考文獻保持完整的研究人員。
可能不會的人
- 任何需要度假時即時攝像頭翻譯的人,使用谷歌翻譯。
- 不想管理任何計算的團隊。有 SLA 的付費 API 可能更平靜。
我沒有預期會保留它。但它在我的工作流程中呆了整周,因為它對我要求更少:更少的標籤、更少的提醒、更少的小決定。那通常是我的信號。令人驚訝的小事?我用語調信任它的段落,而不只是詞語。你的經驗可能不同——但如果你感到太多工具的噪音,這個保持安靜。這就是為什麼它留在我身邊。





